This blog began as a space where I could tinker with unfamiliar methods. Lately I’ve had less time to do that, because I was finishing a book. But the book is out now—so, back to tinkering!
There are plenty of new methods to explore, because computational linguistics is advancing at a dizzying pace. In this post, I’m going to ask how historical inquiry might be advanced by Transformer-based models of language (like GPT and BERT). These models are handily beating previous benchmarks for natural language understanding. Will they also change historical conclusions based on text analysis? For instance, could BERT help us add information about word order to quantitative models of literary history that previously relied on word frequency? It is a slightly daunting question, because the new methods are not exactly easy to use.
I don’t claim to fully understand the Transformer architecture, although I get a feeling of understanding when I read this plain-spoken post by “nostalgebraist.” In essence Transformers capture information implicit in word order by allowing every word in a sentence—or in a paragraph—to have a relationship to every other word. For a fuller explanation, see the memorably-titled paper “Attention Is All You Need” (Vaswani et al. 2017). BERT is pre-trained on a massive English-language corpus; it learns by trying to predict missing words and put sentences in the right order (Devlin et al., 2018). This gives the model a generalized familiarity with the syntax and semantics of English. Users can then fine-tune the generic model for specific tasks, like answering questions or classifying documents in a particular domain.

Even if you have no intention of ever using the model, there is something thrilling about BERT’s ability to reuse the knowledge it gained solving one problem to get a head start on lots of other problems. This approach, called “transfer learning,” brings machine learning closer to learning of the human kind. (We don’t, after all, retrain ourselves from infancy every time we learn a new skill.) But there are also downsides to this sophistication. Frankly, BERT is still a pain for non-specialists to use. To fine-tune the model in a reasonable length of time, you need a GPU, and Macs don’t come with the commonly-supported GPUs. Neural models are also hard to interpret. So there is definitely a danger that BERT will seem arcane to humanists. As I said on Twitter, learning to use it is a bit like “memorizing incantations from a leather-bound tome.”
I’m not above the occasional incantation, but I would like to use BERT only where necessary. Communicating to a wide humanistic audience is more important to me than improving a model by 1%. On the other hand, if there are questions where BERT improves our results enough to produce basically new insights, I think I may want a copy of that tome! This post applies BERT to a couple of different problems, in order to sketch a boundary between situations where neural language understanding really helps, and those where it adds little value.
I won’t walk the reader through the whole process of installing and using BERT, because there are other posts that do it better, and because the details of my own workflow are explained in the github repo. But basically, here’s what you need:
1) A computer with a GPU that supports CUDA (a language for talking to the GPU). I don’t have one, so I’m running all of this on the Illinois Campus Cluster, using machines equipped with a TeslaK40M or K80 (I needed the latter to go up to 512-word segments).
2) The PyTorch module of Python, which includes classes that implement BERT, and translate it into CUDA instructions.
3) The BERT model itself (which is downloaded automatically by PyTorch when you need it). I used the base uncased model, because I wanted to start small; there are larger versions.
4) A few short Python scripts that divide your data into BERT-sized chunks (128 to 512 words) and then ask PyTorch to train and evaluate models. The scripts I’m using come ultimately from HuggingFace; I borrowed them via Thilina Rajapakse, because his simpler versions appeared less intimidating than the original code. But I have to admit: in getting these scripts to do everything I wanted to try, I sometimes had to consult the original HuggingFace code and add back the complexity Rajapakse had taken out.
Overall, this wasn’t terribly painful: getting BERT to work took a couple of days. Dependencies were, of course, the tricky part: you need a version of PyTorch that talks to your version of CUDA. For more details on my workflow (and the code I’m using), you can consult the github repo.
So, how useful is BERT? To start with, let’s consider how it performs on a standard sentiment-analysis task: distinguishing positive and negative opinions in 25,000 movie reviews from IMDb. It takes about thirty minutes to convert the data into BERT format, another thirty to fine-tune BERT on the training data, and a final thirty to evaluate the model on a validation set. The results blow previous benchmarks away. I wrote a casual baseline using logistic regression to make predictions about bags of words; BERT easily outperforms both my model and the more sophisticated model that was offered as state-of-the-art in 2011 by the researchers who developed the IMDb dataset (Maas et al. 2011).
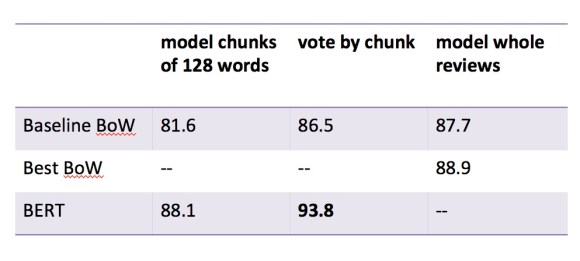
I suspect it is possible to get even better performance from BERT. This was a first pass with very basic settings: I used the bert-base-uncased model, divided reviews into segments of 128 words each, ran batches of 24 segments at a time, and ran only a single “epoch” of training. All of those choices could be refined.
Note that even with these relatively short texts (the movie reviews average 234 words long), there is a big difference between accuracy on a single 128-word chunk and on the whole review. Longer texts provide more information, and support more accurate modeling. The bag-of-words model can automatically take full advantage of length, treating the whole review as a single, richly specified entity. BERT is limited to a fixed window; when texts are longer than the window, it has to compensate by aggregating predictions about separate chunks (“voting” or averaging them). When I force my bag-of-words model to do the same thing, it loses some accuracy—so we can infer that BERT is also handicapped by the narrowness of its window.
But for sentiment analysis, BERT’s strengths outweigh this handicap. When a review says that a movie is “less interesting than The Favourite,” a bag-of-words model will see “interesting!” and “favorite!” BERT, on the other hand, is capable of registering the negation.
Okay, but this is a task well suited to BERT: modeling a boundary where syntax makes a big difference, in relatively short texts. How does BERT perform on problems more typical of recent work in cultural analytics—say, questions about genre in volume-sized documents?
The answer is that it struggles. It can sometimes equal, but rarely surpass, logistic regression on bags of words. Since I thought BERT would at least equal a bag-of-words model, I was puzzled by this result, and didn’t believe it until I saw the same code working very well on the sentiment-analysis task above.
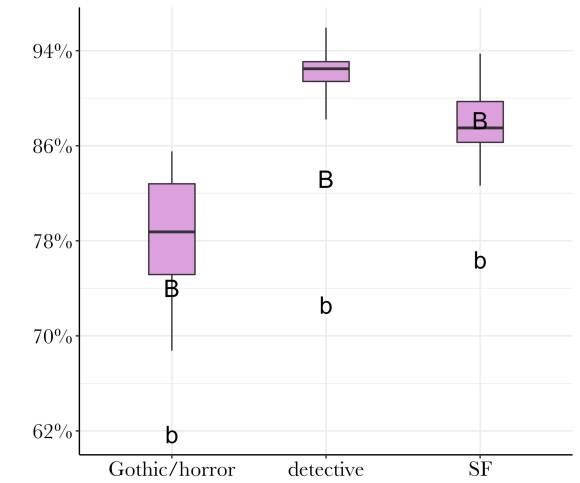
Why can’t BERT beat older methods of genre classification? I am not entirely sure yet. I don’t think BERT is simply bad at fiction, because it’s trained on Google Books, and Sims et al. get excellent results using BERT embeddings on fiction at paragraph scale. What I suspect is that models of genre require a different kind of representation—one that emphasizes subtle differences of proportion rather than questions of word sequence, and one that can be scaled up. BERT did much better on all genres when I shifted from 128-word segments to 256- and then 512-word lengths. Conversely, bag-of-words methods also suffer significantly when they’re forced to model genre in a short window: they lose more accuracy than they lost modeling movie reviews, even after aggregating multiple “votes” for each volume.
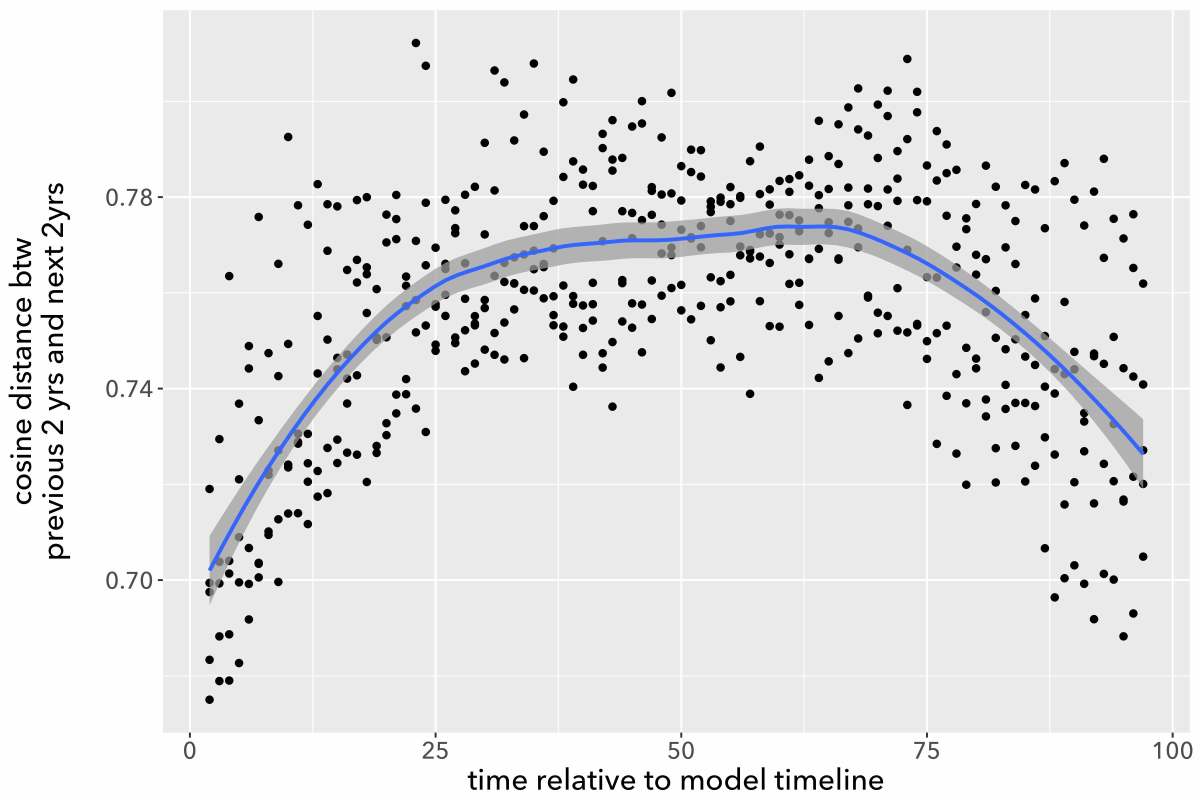
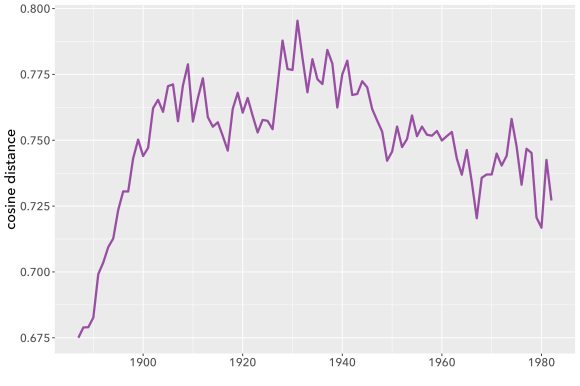
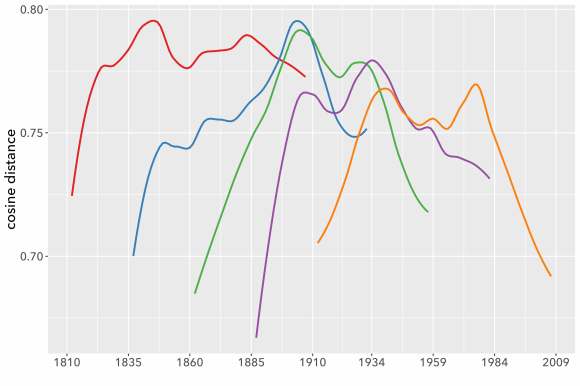
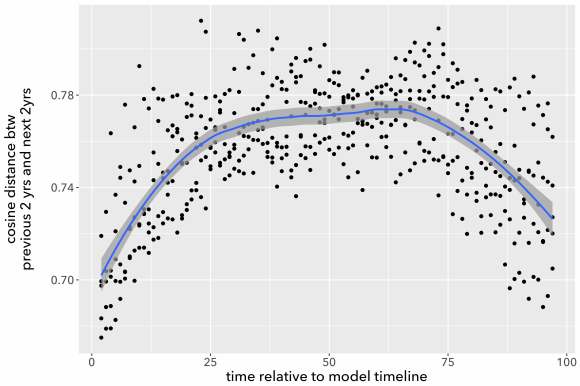
It seems that genre is expressed more diffusely than the opinions of a movie reviewer. If we chose a single paragraph randomly from a work of fiction, it wouldn’t necessarily be easy for human eyes to categorize it by genre. It is a lovely day in Hertfordshire, and Lady Cholmondeley has invited six guests to dinner. Is this a detective story or a novel of manners? It may remain hard to say for the first twenty pages. It gets easier after her nephew gags, turns purple and goes face-first into the soup course, but even then, we may get pages of apparent small talk in the middle of the book that could have come from a different genre. (Interestingly, BERT performed best on science fiction. This is speculative, but I tend to suspect it’s because the weirdness of SF is more legible locally, at the page level, than is the case for other genres.)
Although it may be legible locally in SF, genre is usually a question about a gestalt, and BERT isn’t designed to trace boundaries between 100,000-word gestalts. Our bag-of-words model may seem primitive, but it actually excels at tracing those boundaries. At the level of a whole book, subtle differences in the relative proportions of words can distinguish detective stories from realist novels with sordid criminal incidents, or from science fiction with noir elements.
I am dwelling on this point because the recent buzz around neural networks has revivified an old prejudice against bag-of-words methods. Dissolving sentences to count words individually doesn’t sound like the way human beings read. So when people are first introduced to this approach, their intuitive response is always to improve it by adding longer phrases, information about sentence structure, and so on. I initially thought that would help; computer scientists initially thought so; everyone does, initially. Researchers have spent the past thirty years trying to improve bags of words by throwing additional features into the bag (Bekkerman and Allan 2003). But these efforts rarely move the needle a great deal, and perhaps now we see why not.
BERT is very good at learning from word order—good enough to make a big difference for questions where word order actually matters. If BERT isn’t much help for classifying long documents, it may be time to conclude that word order just doesn’t cast much light on questions about theme and genre. Maybe genres take shape at a level of generality where it doesn’t really matter whether “Baroness poisoned nephew” or “nephew poisoned Baroness.”
I say “maybe” because this is just a blog post based on one week of tinkering. I tried varying the segment length, batch size, and number of epochs, but I haven’t yet tried the “large” or “cased” pre-trained models. It is also likely that BERT could improve if given further pre-training on fiction. Finally, to really figure out how much BERT can add to existing models of genre, we might try combining it in an ensemble with older methods. If you asked me to bet, though, I would bet that none of those stratagems will dramatically change the outlines of the picture sketched above. We have at this point a lot of evidence that genre classification is a basically different problem from paragraph-level NLP.
Anyway, to return to the question in the title of the post: based on what I have seen so far, I don’t expect Transformer models to displace other forms of text analysis. Transformers are clearly going to be important. They already excel at a wide range of paragraph-level tasks: answering questions about a short passage, recognizing logical relations between sentences, predicting which sentence comes next. Those strengths will matter for classification boundaries where syntax matters (like sentiment). More importantly, they could open up entirely new avenues of research: Sims et al. have been using BERT embeddings for event detection, for instance—implying a new angle of attack on plot.
But volume-scale questions about theme and genre appear to represent a different sort of modeling challenge. I don’t see much evidence that BERT will help there; simpler methods are actually tailored to the nature of this task with a precision we ought to appreciate.
Finally, if you’re on the fence about exploring this topic, it might be shrewd to wait a year or two. I don’t believe Transformer models have to be hard to use; they are hard right now, I suspect, mostly because the technology isn’t mature yet. So you may run into funky issues about dependencies, GPU compatibility, and so on. I would expect some of those kinks to get worked out over time; maybe eventually this will become as easy as “from sklearn import bert”?
References
Bekkerman, Ron, and James Allan. “Using Bigrams in Text Categorization.” 2003. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.152.4885&rep=rep1&type=pdf
Devlin, Jacob, Ming-Wei Chan, Kenton Lee, and Kristina Toutonova. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. 2018. https://arxiv.org/pdf/1810.04805.pdf
HuggingFace. “PyTorch Pretrained BERT: The Big and Extending Repository of Pretrained Transformers.” https://github.com/huggingface/pytorch-pretrained-BERT
Maas, Andrew, et al. “Learning Word Vectors for Sentiment Analysis.” 2011. https://www.aclweb.org/anthology/P11-1015
Rajapakse, Thilina. “A Simple Guide to Using BERT for Binary Text Classification.” 2019. https://medium.com/swlh/a-simple-guide-on-using-bert-for-text-classification-bbf041ac8d04
Sims, Matthew, Jong Ho Park, and David Bamman. “Literary Event Detection.” 2019. http://people.ischool.berkeley.edu/~dbamman/pubs/pdf/acl2019_literary_events.pdf
Underwood, Ted. “The Life Cycles of Genres.” The Journal of Cultural Analytics. 2015. https://culturalanalytics.org/2016/05/the-life-cycles-of-genres/
Vaswani, Ashish, et al. “Attention Is All You Need.” 2017. https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf