Last year, Jordan Sellers and I published an article in Modern Language Quarterly, trying to trace the “great divide” that is supposed to open up between mass culture and advanced literary taste around the beginning of the twentieth century.
I’m borrowing the phrase “great divide” from Andreas Huyssen, but he’s not the only person to describe the phenomenon. Whether we explain it neutrally as a consequence of widespread literacy, or more skeptically as the rise of a “culture industry,” literary historians widely agree that popularity and prestige parted company in the twentieth century. So we were surprised not to be able to measure the widening gap.
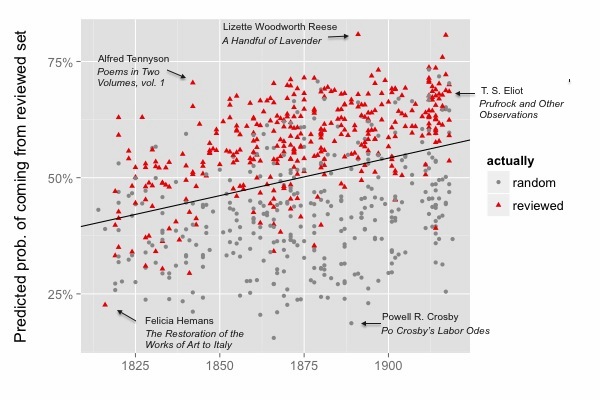
 We could certainly model literary taste. We trained a model to distinguish poets reviewed in elite literary magazines from a less celebrated “contrast group” selected randomly. The model achieved roughly 79% accuracy, 1820-1919, and the stability of the model itself raised interesting questions. But we didn’t find that the model’s accuracy increased across time in the way we would have expected in a period when elite and popular literary taste are specializing and growing apart.
We could certainly model literary taste. We trained a model to distinguish poets reviewed in elite literary magazines from a less celebrated “contrast group” selected randomly. The model achieved roughly 79% accuracy, 1820-1919, and the stability of the model itself raised interesting questions. But we didn’t find that the model’s accuracy increased across time in the way we would have expected in a period when elite and popular literary taste are specializing and growing apart.
Instead of concluding that the division never happened, we guessed that we had misunderstood it or looked in the wrong place. Algee-Hewitt and McGurl have pretty decisively confirmed that a divide exists in the twentieth century. So we ought to be able to see it emerging. Maybe we needed to reach further into the twentieth century — or maybe we would have better luck with fiction, since the history of fiction provides evidence about sales, as well as prestige?
In fact, getting evidence about that second, economic axis seems to be the key. It took work by many hands over a couple of years: Kyle Johnston, Sabrina Lee, and Jessica Mercado, as well as Jordan Sellers, have all contributed to this project. I’m presenting a preliminary account of our results at Cultural Analytics 2017, and this blog post is just a brief summary of the main point.
When you look at the books described as bestsellers by Publisher’s Weekly, or by book historians (see references to Altick, Bloom, Hackett, Leavis, below) it’s easy to see the two circles of the Venn diagram pulling apart: on the one hand bestsellers, on the other hand books reviewed in elite venues. (For our definition of “elite venues” see the “Table” in a supporting code & data repository.)
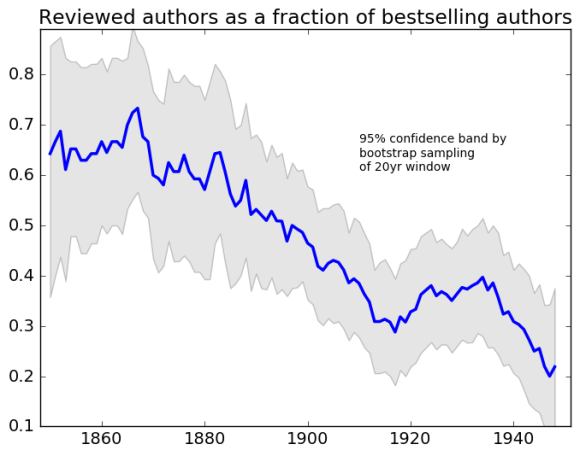
On the other hand, when you back up from bestsellers to look at a broader sample of literary production, it’s still not easy to detect increasing stylistic differentiation between the elite “reviewed” texts and the rest of the literary field. A classifier trained on the reviewed fiction has roughly 72.5% accuracy from 1850 to 1949; if you break the century into parts, there are some variations in accuracy, but no consistent pattern. (In a subsequent blog post, I’ll look at the fiddly details of algorithm choice and feature engineering, but the long and short of that question is — it doesn’t make a significant difference.)
To understand why the growing separation of bestsellers from “reviewed” texts at the high end of the market doesn’t seem to make literary production as a whole more strongly stratified, I’ve tried mapping authors onto a two-dimensional model of the literary field, intended to echo Pierre Bourdieu’s well-known diagrams of the interaction between economic and cultural distinction.
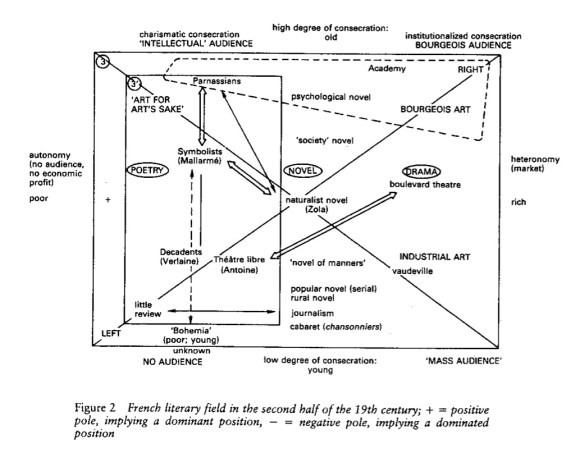
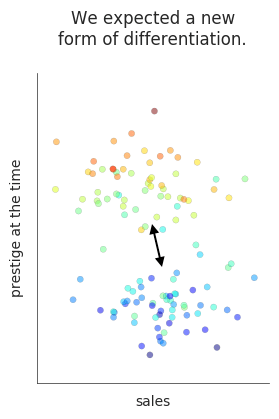
In the diagram below, for instance, the horizontal axis represents sales, and the vertical axis represents prestige. Sales would be easy to measure, if we had all the data. We actually don’t — so see the end of this post for the estimation strategy I adopted. Prestige, on the other hand, is difficult to measure: it’s perspectival and complex. So we modeled prestige by sampling texts that were reviewed in prominent literary magazines, and then training a model that used textual cues to predict the probability that any given book came from the “reviewed” set. An author’s prestige in this diagram is simply the average probability of review for their books. (The Stanford Literary Lab has similarly recreated Bourdieu’s model of distinction in their pamphlet “Canon/Archive,” using academic citations as a measure of prestige.)
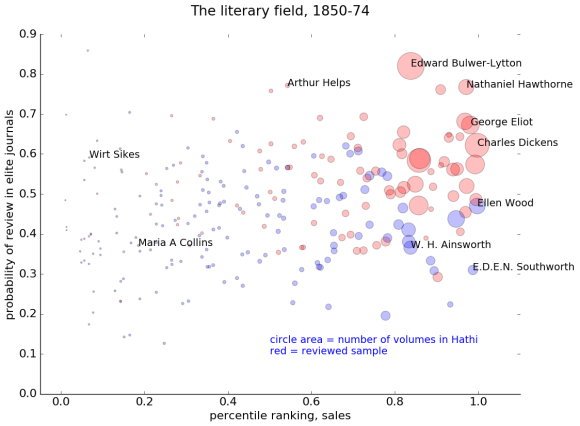
The upward drift of these points reveals a fairly strong correlation between prestige and sales. It is possible to find a few high-selling authors who are predicted to lack critical prestige — notably, for instance, the historical novelist W. H. Ainsworth and the sensation novelist Ellen Wood, author of East Lynne. It’s harder to find authors who have prestige but no sales: there’s not much in the northwest corner of the map. Arthur Helps, a Cambridge Apostle, is a fairly lonely figure.
Fast-forward seventy-five years and we see a different picture.
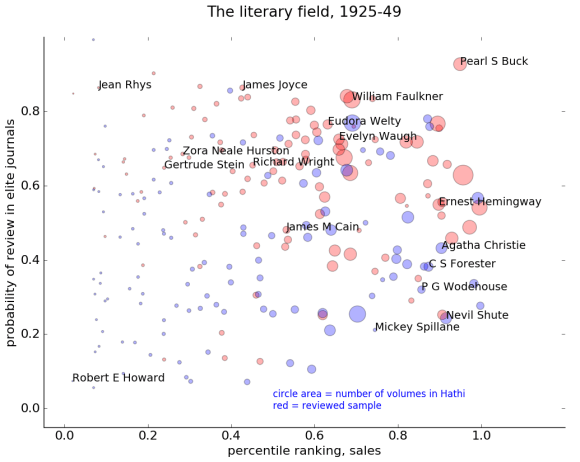
The correlation between sales and prestige is now weaker; the cloud of authors is “rounder” overall.
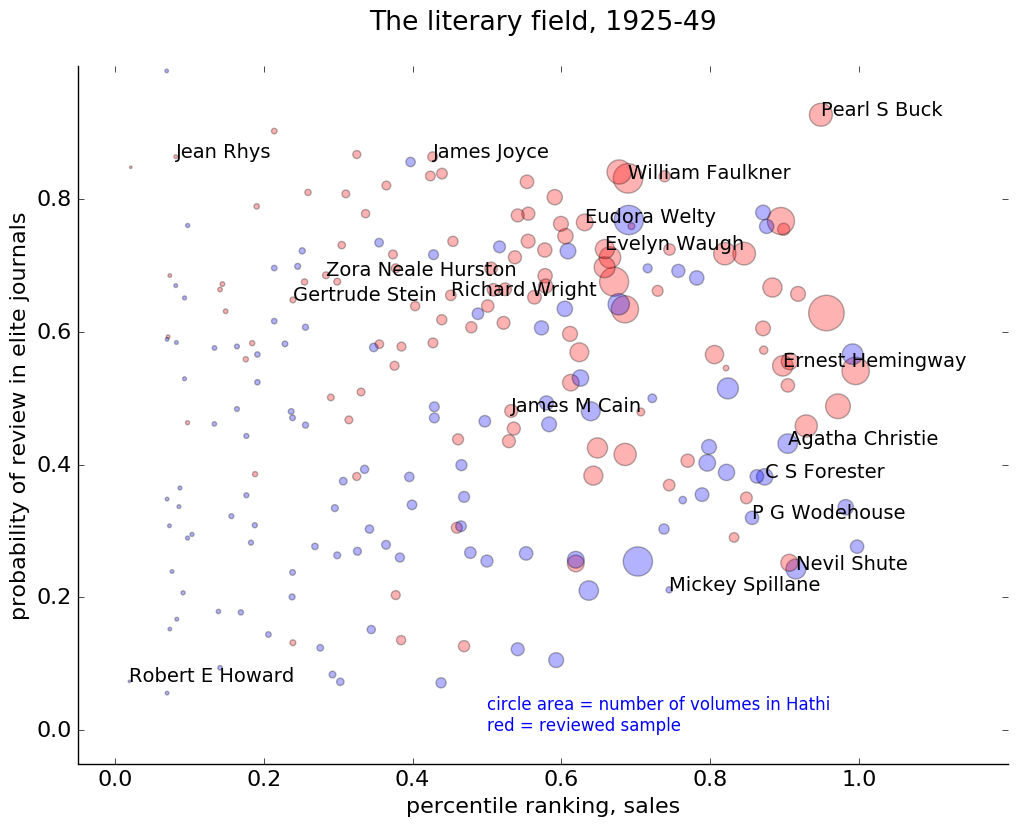
There are also more authors in the “upper midwest” portion of the map now — people like Zora Neale Hurston and James Joyce, who have critical prestige but not enormous sales (or not up to 1949, at least as far as my model is aware).
There’s also a distinct “genre fiction” and “pulp fiction” world emerging in the southeast corner of this map, ranging from Agatha Christie to Mickey Spillane. (A few years earlier, Edgar Rice Burroughs and Zane Gray are in the same region.)
Moreover, if you just look at the large circles (the authors we’re most likely to remember), you can start to see how people in this period might get the idea that sales are actually negatively correlated with critical prestige. The right side of the map almost looks like a diagonal line slanting down from William Faulkner to P. G. Wodehouse.
That negative correlation doesn’t really characterize the field as a whole. Critical prestige still has a faint positive correlation with sales, as people over on the left side of the map might sadly remind us. But a brief survey of familiar names could give you the opposite impression.
In short, we’re not necessarily seeing a stronger stratification of the literary field. The change might better be described as a decline in the correlation of two existing forms of distinction. And as they become less correlated, the difference between them becomes more visible, especially among the well-known names on the right side of the map.
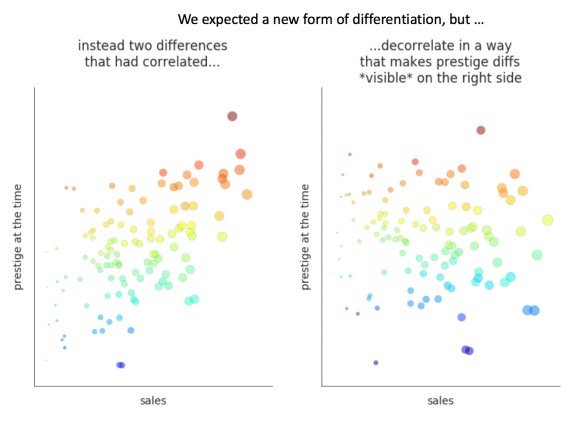
So, while we’re broadly confirming an existing story about literary history, the evidence also suggests that the metaphor of a “great divide” is a bit of an exaggeration. We don’t see any chasm emerging.
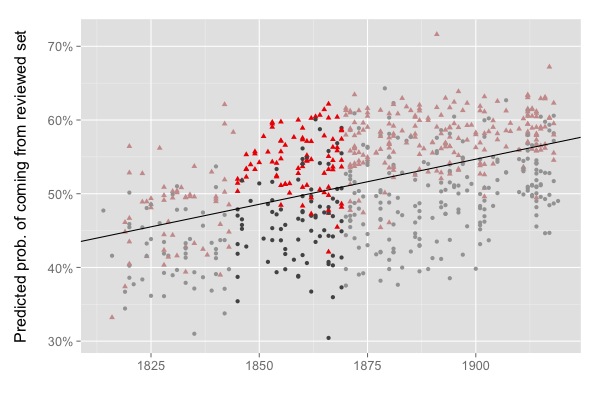
Maps of the literary field also help me understand why a classifier trained on an elite “reviewed” sample didn’t necessarily get stronger over time. The correlation of prestige and sales in the Victorian era means that the line separating the red and blue samples was strongly tilted there, and may borrow some of its strength from both axes. (It’s really a boundary between the prominent and the obscure.)
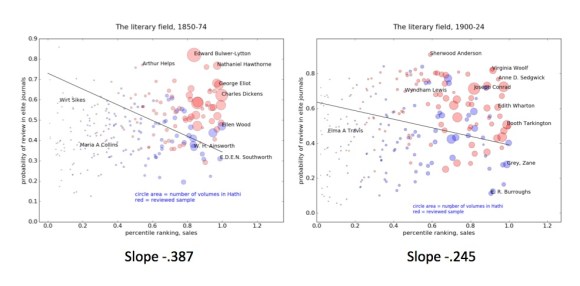
As we move into the twentieth century, the slope of the line gets flatter, and we get closer to a “pure” model of prestige (as distinguished from sales). But the boundary itself may not grow more clearly marked, if you’re sampling a group of the same size. (However, if you leave The New Republic and New Yorker behind, and sample only works reviewed in little magazines, you do get a more tightly unified group of texts that can be distinguished from a random sample with 83% accuracy.)
This is all great, you say — but how exactly are you “estimating” sales? We don’t actually have good sales figures for every author in HathiTrust Digital Library; we have fairly patchy records that depend on individual publishers.
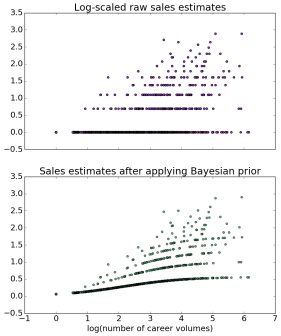
For the answer to that question, I’m going to refer you to the github repo where I work out a model of sales. The short version is that I borrow a version of “empirical Bayes” from Julia Silge and David Robinson, and apply it to evidence drawn from bestseller lists as well as digital libraries, to construct a rough estimate of each author’s relative prominence in the market. The trick is, basically, to use the evidence we have to construct an estimate of our uncertainty, and then use our uncertainty to revise the evidence. The picture on the left gives you a rough sense of how that transformation works. I think empirical Bayes may turn out to be useful for a lot of problems where historians need to reconstruct evidence that is patchy or missing in the historical record, but the details are too much to explain here; see Silge’s post and my Jupyter notebook.
Bubble charts invite mouse-over exploration. I can’t easily embed interactive viz in this blog, but here are a few links to plotly visualizations:
https://plot.ly/~TedUnderwood/8/the-literary-field-1850-1874/
https://plot.ly/~TedUnderwood/4/the-literary-field-1875-1899/
https://plot.ly/~TedUnderwood/2/the-literary-field-1900-1924/
https://plot.ly/~TedUnderwood/6/the-literary-field-1925-1949/
Acknowledgments
The texts used here are drawn from HathiTrust via the HathiTrust Research Center. Parts of the research were funded by the Andrew G Mellon Foundation via the WCSA+DC grant, and part by SSHRC via NovelTM.
Most importantly, I want to acknowledge my collaborators on this project, Kyle Johnston, Sabrina Lee, Jessica Mercado, and Jordan Sellers. They contributed a lot of intellectual depth to the project — for instance by doing research that helped us decide which periodicals should represent a given period of literary history.
References
Algee-Hewitt, Mark, and Mark McGurl. “Between Canon and Corpus: Six Perspectives on 20th-Century Novels.” Stanford Literary Lab, Pamphlet 9, 2015. https://litlab.stanford.edu/LiteraryLabPamphlet8.pdf
Algee-Hewitt, Mark, Sarah Allison, Marissa Gemma, Ryan Heuser, Franco Moretti, Hannah Walser. “Canon/Archive: Large-Scale Dynamics in the Literary Field.” Stanford Literary Lab, January 2016. https://litlab.stanford.edu/LiteraryLabPamphlet11.pdf
Altick, Richard D. The English Common Reader: A Social History of the Mass Reading Public 1800-1900. Chicago: University of Chicago Press, 1957.
Bloom, Clive. Bestsellers: Popular Fiction Since 1900. 2nd edition. Houndmills: Palgrave Macmillan, 2008.
Hackett, Alice Payne, and James Henry Burke. 80 Years of Best Sellers 1895-1975. New York: R.R. Bowker, 1977.
Leavis, Q. D. Fiction and the Reading Public. 1935.
Mott, Frank Luther. Golden Multitudes: The Story of Bestsellers in the United States. New York: R. R. Bowker, 1947.
Robinson, David. Introduction to Empirical Bayes: Examples from Baseball Statistics. 2017. http://varianceexplained.org/r/empirical-bayes-book/
Silge, Julia. “Singing the Bayesian Beginner Blues.” data science ish, September 2016. http://juliasilge.com/blog/Bayesian-Blues/
Unsworth, John. 20th Century American Bestsellers. (http://bestsellers.lib.virginia.edu)