Although distant reading always involves work, some parts of the task have an immediate reward. Solving these problems gives you an article with clear disciplinary significance, or at least a sparkly website. You could call these problems the glamorous ones.
Other problems are just nasty. They require a lot of detail work that never sees the light of day, and when you’re done, all you have is an intermediate product that makes further inquiry possible. The research community as a whole benefits, but you don’t get your picture taken with the Mayor. At most, if you’re lucky, you get a couple of data or code citations.
Perspectives vary, of course: problems that look nasty to literary scholars might be glamorous in information science. But untenured scholars understandably want problems that count as glamorous in their home disciplines. Even post-tenure, I only do thankless work in the dead of night if I can get help and/or grant funding, because I’m not a masked billionaire vigilante. For the last several years, I’ve been collaborating with HathiTrust Research Center to create a public dataset of word counts for English-language literature 1800-2000, and we’re only halfway done with that slightly nasty task.
So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
1: Proving how much ngram information is safe to share.
In order to do research beyond the wall of copyright, we often need to share derived data about books, instead of the original text. The question is, how much information can you share, legally, before it becomes possible to reconstruct the book?
There’s already some good research on this problem, and it might be 90% solved. But it’s a Rasputin-like problem that will keep coming back to life if you only kill it 90% dead. We need someone to bury it, which probably means, someone with real CS training, who can produce a specific, confident answer you could show a lawyer. In particular, there are tricky questions about interactions between different levels of aggregation. Suppose (for instance) you had page-level counts of single words, plus volume-level counts of trigrams. How much of a book, at most, could you reconstruct, given real-life variations in book length and page length?
2: Date-of-first-publication metadata.
We’re beginning to assemble large literary collections. But some of them include a lot of reprints, published decades or centuries after the first edition. That’s not necessarily a bad thing, but we will probably also want datasets that are deduplicated, or limited to first editions.
The beautiful, general solution to this problem probably requires linked data, and FRBR protocols, and a great deal of discussion. But see xkcd on solutions to “general problems.”
The solution Gotham City needs right now is probably more like a list of 50,000 titles, associated with dates of first publication.
This may be the next nasty problem I tackle. I suspect it would benefit from a tiered solution, where you produce a small amount of hand-checked data, plus a large amount of scraped or algorithmically-guessed data with a lower level of confidence.
3: A half-decent eighteenth century collection.
OCR problems before 1800 are real, but the universe of English literature before 1800 is also small enough that it’s possible to imagine creating a reasonable sample of hand-corrected texts. The eMOP crowd-sourcing initiative may be the solution here. Or a very modest supplement to ECCO-TCP might be sufficient. I don’t know; I understand nineteenth-century digital collections much better.
***
A post like this one may seem to be encouraging people, generally, to tackle more nasty problems, but that’s not what I intend. Actually, I think scholars who work with computers tend to have a temperament that makes us all too willing to work on unglamorous infrastructure & markup problems, in the faith that they will eventually produce a general solution useful to everyone.
Fields that aren’t yet securely central to a discipline sometimes need to emphasize shorter-term thinking. But maybe distant reading is getting secure enough that a few of us can afford to do vigilante work on the side. Or maybe there are computer scientists out there who just need to see a bat signal.
Feel free to suggest more nasty problems in the comments.
by Ted Underwood, Hoyt Long, Richard Jean So, and Yuancheng Zhu
This is the second part of a two-part blog post about quantitative approaches to cultural change, focusing especially on a recent article that claimed to identify “stylistic revolutions” in popular music.
Are measures of the stylistic “distance” between songs or texts really what we mean by cultural change?
If we did take that approach to measuring change, would we find brief periods where the history of music or literature speeds up by a factor of six, as Mauch et al. claim?
Underwood’s initial post last October discussed both of these questions. The first one is more important. But it may also be hard to answer — in part because “cultural change” could mean a range of different things (e.g., the ever-finer segmentation of the music market, not just changes that affect it as a whole).
So putting the first question aside for now, let’s look at the the second one closely. When we do measure the stylistic or linguistic “distance” between works of music or literature, do we actually discover brief periods of accelerated change?
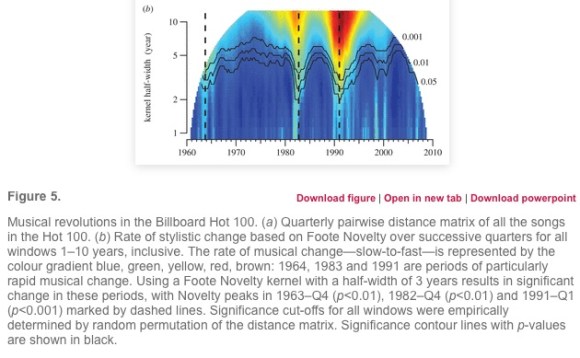
The authors of “The Evolution of Popular Music” say “yes!” Epochal breaks can be dated to particular years.
We identified three revolutions: a major one around 1991 and two smaller ones around 1964 and 1983 (figure 5b). From peak to succeeding trough, the rate of musical change during these revolutions varied four- to six-fold.
Tying musical revolutions to particular years (and making 1991 more important than 1964) won the article a lot of attention in the press. Underwood’s questions about these claims last October stirred up an offline conversation with three researchers at the University of Chicago, who have joined this post as coauthors. After gathering in Hyde Park to discuss the question for a couple of days, we’ve concluded that “The Evolution of Popular Music” overstates its results, but is also a valuable experiment, worth learning from. The article calculates significance in a misleading way: only two of the three “revolutions” it reported are really significant at p < 0.05, and it misses some odd periods of stasis that are just as significant as the periods of acceleration. But these details are less interesting than the reason for the error, which involved a basic challenge facing quantitative analysis of history.
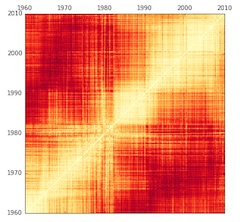
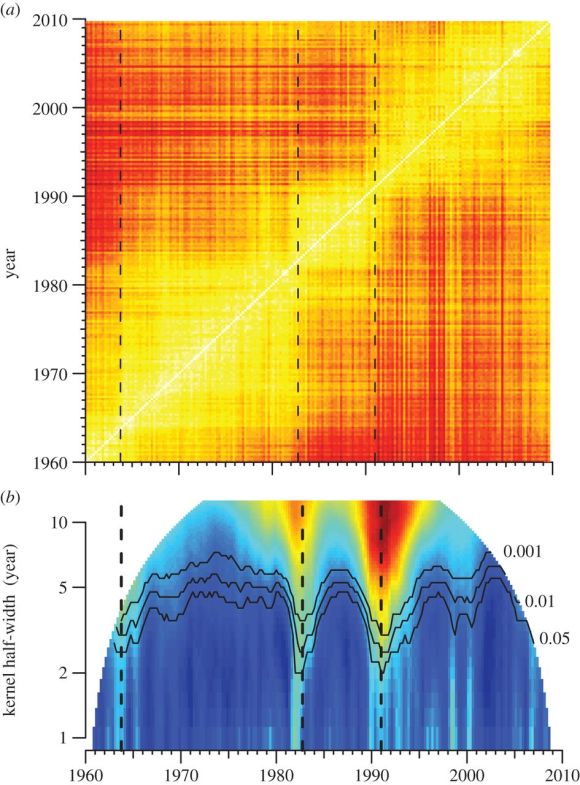
To explain that problem, we’ll need to explain the central illustration in the original article. The authors’ strategy was to take every quarter-year of the Billboard Hot 100 between 1960 and 2010, and compare it to every other quarter, producing a distance matrix where light (yellow-white) colors indicate similarity, and dark (red) colors indicate greater differences. (Music historians may wonder whether “harmonic and timbral topics” are the right things to be comparing in the first place, and it’s a fair question — but not central to our purpose in this post, so we’ll give it a pass.)
You see a diagonal white line in the matrix, because comparing a quarter to itself naturally produces a lot of similarity. As you move away from that line (to the upper left or lower right), you’re making comparisons across longer and longer spans of time, so colors become darker (reflecting greater differences).
Figure 5 from Mauch, et. al., “The evolution of popular music” (RSOS 2015).
Then, underneath the distance matrix, Mauch et al. provide a second illustration that measures “Foote novelty” for each quarter. This is a technique for segmenting audio files developed by Jonathan Foote. The basic idea is to look for moments of acceleration where periods of relatively slow change are separated by a spurt of rapid change. In effect, that means looking for a point where yellow “squares” of similarity touch at their corners.
For instance, follow the dotted line associated with 1991 in the illustration above up to its intersection with the white diagonal. At that diagonal line, 1991 is (unsurprisingly) similar to itself. But if you move upward in the matrix (comparing 1991 to its own future), you rapidly get into red areas, revealing that 1994 is already quite different. The same thing is true if you move over a year to 1992 and then move down (comparing 1992 to its own past). At a “pinch point” like this, change is rapid. According to “The Evolution of Popular Music,” we’re looking at the advent of rap and hip-hop in the Billboard Hot 100. Contrast this pattern, for instance, to a year like 1975, in the middle of a big yellow square, where it’s possible to move several years up or down without encountering significant change.
Mathematically, “Foote novelty” is measured by sliding a smaller matrix along the diagonal timeline, multiplying it element-wise with the measurements of distance underlying all those red or yellow points. Then you add up the multiplied values. The smaller matrix has positive and negative coefficients corresponding to the “squares” you want to contrast, as seen on the right.
As you can see, matrices of this general shape will tend to produce a very high sum when they reach a pinch point where two yellow squares (of small distances) are separated by the corners of reddish squares (containing large distances) to the upper left and lower right. The areas of ones and negative-ones can be enlarged to measure larger windows of change.
This method works by subtracting the change on either side of a temporal boundary from the changes across the boundary itself. But it has one important weakness. The contrast between positive and negative areas in the matrix is not apples-to-apples, because comparisons made across a boundary are going to stretch across a longer span of time, on average, than the comparisons made within the half-spans on either side. (Concretely, you can see that the ones in the matrix above will be further from the central diagonal timeline than the negative-ones.)
If you’re interested in segmenting music, that imbalance may not matter. There’s a lot of repetition in music, and it’s not always true that a note will resemble a nearby note more than it resembles a note from elsewhere in the piece. Here’s a distance matrix, for instance, from The Well-Tempered Clavier, used by Foote as an example.
From Foote, “Automatic Audio Segmentation Using a Measure of Audio Novelty.”
Unlike the historical matrix in “The Evolution of Popular Music,” this has many light spots scattered all over — because notes are often repeated.
Original distance matrix produced using data from Mauch et al. (2015).
History doesn’t repeat itself in the same way. It’s extremely likely (almost certain) that music from 1992 will resemble music from 1991 more than it resembles music from 1965. That’s why the historical distance matrix has a single broad yellow path running from lower left to upper right.
As a result, historical sequences are always going to produce very high measurements of Foote novelty. Comparisons across a boundary will always tend to create higher distances than the comparisons within the half-spans on either side, because differences across longer spans of time always tend to be bigger.
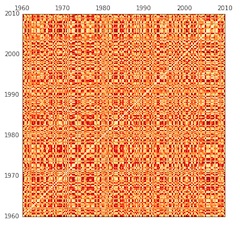
Matrix produced by permuting years and then measuring the distances between them.
This also makes it tricky to assess the significance of “Foote novelty” on historical evidence. You might ordinarily do this using a “permutation test.” Scramble all the segments of the timeline repeatedly and check Foote novelty each time, in order to see how often you get “squares” as big or well-marked as the ones you got in testing the real data. But that sort of scrambling will make no sense at all when you’re looking at history. If you scramble the years, you’ll always get a matrix that has a completely different structure of similarity — because it’s no longer sequential.
The Foote novelties you get from a randomized matrix like this will always be low, because “Foote novelty” partly measures the contrast between areas close to, and far from, the diagonal line (a contrast that simply doesn’t exist here).
This explains a deeply puzzling aspect of the original article. If you look at the significance curves labeled .001, .01, and 0.05 in the visualization of Foote novelties (above), you’ll notice that every point in the original timeline had a strongly significant novelty score. As interpreted by the caption, this seems to imply that change across every point was faster than average for the sequence … which … can’t possibly be true everywhere.
All this image really reveals is that we’re looking at evidence that takes the form of a sequential chain. Comparisons across long spans of time always involve more difference than comparisons across short ones — to an extent that you would never find in a randomized matrix.
In short, the tests in Mauch et al. don’t prove that there were significant moments of acceleration in the history of music. They just prove that we’re looking at historical evidence! The authors have interpreted this as a sign of “revolution,” because all change looks revolutionary when compared to temporal chaos.
On the other hand, when we first saw the big yellow and red squares in the original distance matrix, it certainly looked like a significant pattern. Granted that the math used in the article doesn’t work — isn’t there some other way to test the significance of these variations?
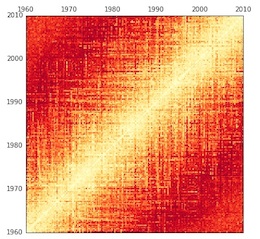
It took us a while to figure out, but there is a reliable way to run significance tests for Foote novelty. Instead of scrambling the original data, you need to permute the distances along diagonals of the distance matrix.
Produced by permuting diagonals in the original matrix.
In other words, you take a single diagonal line in the original matrix and record the measurements of distance along that line. (If you’re looking at the central diagonal, this will contain a comparison of every quarter to itself; if you move up one notch, it will contain a comparison of every quarter to the quarter in its immediate future.) Then you scramble those values randomly, and put them back on the same line in the matrix. (We’ve written up a Jupyter notebook showing how to do it.) This approach distributes change randomly across time while preserving the sequential character of the data: comparisons over short spans of time will still tend to reveal more similarity than long ones.
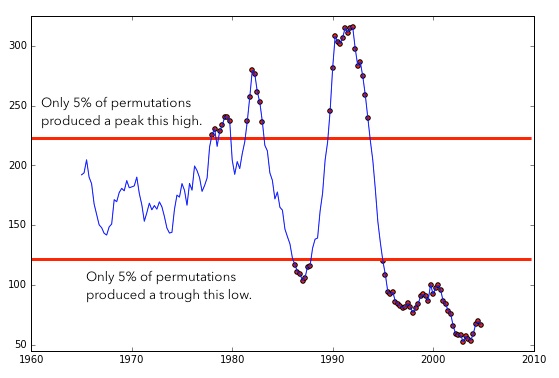
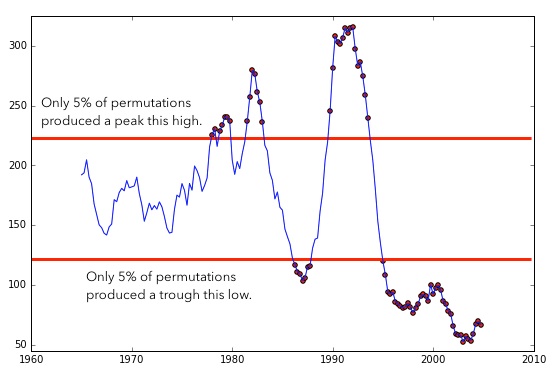
If you run this sort of permutation 100 times, you can discover the maximum and minimum Foote novelties that would be likely to occur by chance.
Measurements of Foote novelty produced by a matrix with a five-year half-width, and the thresholds for significance.
Variation between the two red lines isn’t statistically significant — only the peaks of rapid change poking above the top line, and the troughs of stasis dipping below the bottom line. (The significance of those troughs couldn’t become visible in the original article, because the question had been framed in a way that made smaller-than-random Foote novelties impossible by definition.)
These corrected calculations do still reveal significant moments of acceleration in the history of the Billboard Hot 100: two out of three of the “revolutions” Mauch et al. report (around 1983 and 1991) are still significant at p < 0.05 and even p < 0.001. (The British Invasion, alas, doesn’t pass the test.) But the calculations also reveal something not mentioned in the original article: a very significant slowing of change after 1995.
Can we still call the moments of acceleration in this graph stylistic “revolutions”?
Foote novelty itself won’t answer the question. Instead of directly measuring a rate of change, it measures a difference between rates of change in overlapping periods. But once we’ve identified the periods that interest us, it’s simple enough to measure the pace of change in each of them. You can just divide the period in half and compare the first half to the second (see the “Effect size” section in our Jupyter notebook). This confirms the estimate in Mauch et al.: if you compare the most rapid period of change (from 1990 to 1994) to the slowest four years (2001 to 2005), there is a sixfold difference between them.
On the other hand, it could be misleading to interpret this as a statement about the height of the early-90s “peak” of change, since we’re comparing it to an abnormally stable period in the early 2000s. If we compare both of those periods to the mean rate of change across any four years in this dataset, we find that change in the early 90s was about 171% of the mean pace, whereas change in the early 2000s was only 29% of mean. Proportionally, the slowing of change after 1995 might be the more dramatic aberration here.
Overall, the picture we’re seeing is different from the story in “The Evolution of Popular Music.” Instead of three dramatic “revolutions” dated to specific years, we see two periods where change was significantly (but not enormously) faster than average, and two periods where it was slower. These periods range from four to fifteen years in length.
Humanists will surely want to challenge this picture in theoretical ways as well. Was the Billboard Hot 100 the right sample to be looking at? Are “timbral topics” the right things to be comparing? These are all valid questions.
But when scientists make quantitative claims about humanistic subjects, it’s also important to question the quantitative part of their argument. If humanists begin by ceding that ground, the conversation can easily become a stalemate where interpretive theory faces off against the (supposedly objective) logic of science, neither able to grapple with the other.
One of the authors of “The Evolution of Popular Music,” in fact, published an editorial in The New York Times representing interdisciplinary conversation as exactly this sort of stalemate between “incommensurable interpretive fashions” and the “inexorable logic” of math (“One Republic of Learning,” NYT Feb 2015). But in reality, as we’ve just seen, the mathematical parts of an argument about human culture also encode interpretive premises (assumptions, for instance, about historical difference and similarity). We need to make those premises explicit, and question them.
Having done that here, and having proposed a few corrections to “The Evolution of Popular Music,” we want to stress that the article still seems to us a bold and valuable experiment that has advanced conversation about cultural history. The basic idea of calculating “Foote novelty” on a distance matrix is useful: it can give historians a way of thinking about change that acknowledges several different scales of comparison at once.
The authors also deserve admiration for making their data available; that transparency has permitted us to replicate and test their claims, just as Andrew Goldstone recently tested Ted Underwood’s model of poetic prestige, and Annie Swafford tested Matt Jockers’ syuzhet package. Our understanding of these difficult problems can only advance through collective practices of data-sharing and replication. Being transparent in our methods is more important, in the long run, than being right about any particular detail.
The authors want to thank the NovelTM project for supporting the collaboration reported here. (And we promise to apply these methods to the history of the novel next.)
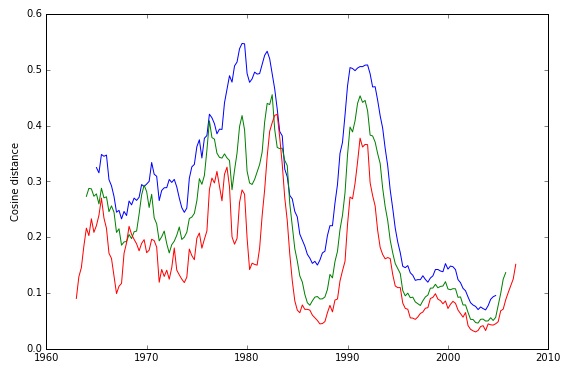
Postscript: Several commenters on the original blog post proposed simpler ways of measuring change that begin by comparing adjacent segments of a timeline. This an intuitive approach, and a valid one, but it does run into difficulties — as we discovered when we tried to base changepoint analysis on it (Jupyter notebook here). The main problem is that apparent trajectories of change can become very delicately dependent on the particular window of comparison you use. You’ll see lots of examples of that problem toward the end of our notebook.
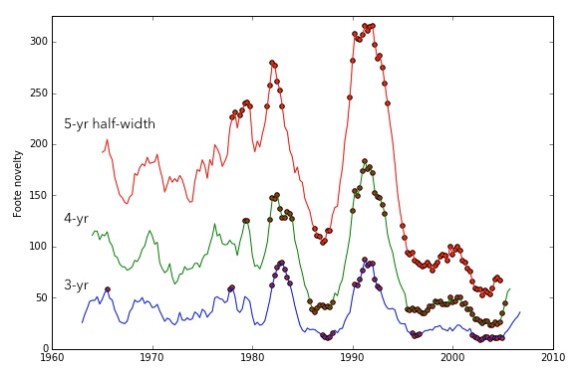
The advantage of the “Foote novelty” approach is that it combines lots of different scales of comparison (since you’re considering all the points in a matrix — some closer and some farther from the timeline). That makes the results more robust. Here, for instance, we’ve overlaid the “Foote novelties” generated by three different windows of comparison on the music dataset, flagging the quarters that are significant at p < 0.05 in each case.
This sort of close congruence is not something we found with simpler methods. Compare the analogous image below, for instance. Part of the chaos here is a purely visual issue related to the separation of curves — but part comes from using segments rather than a distance matrix.


 So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
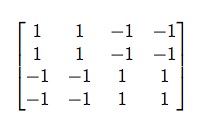 Mathematically, “Foote novelty” is measured by sliding a smaller matrix along the diagonal timeline, multiplying it element-wise with the measurements of distance underlying all those red or yellow points. Then you add up the multiplied values. The smaller matrix has positive and negative coefficients corresponding to the “squares” you want to contrast, as seen on the right.
Mathematically, “Foote novelty” is measured by sliding a smaller matrix along the diagonal timeline, multiplying it element-wise with the measurements of distance underlying all those red or yellow points. Then you add up the multiplied values. The smaller matrix has positive and negative coefficients corresponding to the “squares” you want to contrast, as seen on the right.