The Institute of Electrical and Electronics Engineers is an odd venue for literary history, and our paper ends up touching so many disciplinary bases that it may be distracting.* So I thought I’d pull out four issues of interest to humanists and discuss them briefly here; I’m also taking the occasion to add a little information about gender that we uncovered too late to include in the paper itself.
1) The overall point about genre. Our title, “Mapping Mutable Genres in Structurally Complex Volumes,” may sound like the sort of impossible task heroines are assigned in fairy tales. But the paper argues that the blurry mutability of genres is actually a strong argument for a digital approach to their history. If we could start from some consensus list of categories, it would be easy to crowdsource the history of genre: we’d each take a list of definitions and fan out through the archive. But centuries of debate haven’t yet produced stable definitions of genre. In that context, the advantage of algorithmic mapping is that it can be comprehensive and provisional at the same time. If you change your mind about underlying categories, you can just choose a different set of training examples and hit “run” again. In fact we may never need to reach a consensus about definitions in order to have an interesting conversation about the macroscopic history of genre.
2) A workset of 32,209 volumes of English-language fiction. On the other hand, certain broad categories aren’t going to be terribly controversial. We can probably agree about volumes — and eventually specific page ranges — that contain (for instance) prose fiction and nonfiction, narrative and lyric poetry, and drama in verse, or prose, or some mixture of the two. (Not to mention interesting genres like “publishers’ ads at the back of the volume.”) As a first pass at this problem, we extract a workset of 32,209 volumes containing prose fiction from a collection of 469,200 eighteenth- and nineteenth-century volumes in HathiTrust Digital Library. The metadata for this workset is publicly available from Illinois’ institutional repository. More substantial page-level worksets will soon be produced and archived at HathiTrust Research Center.
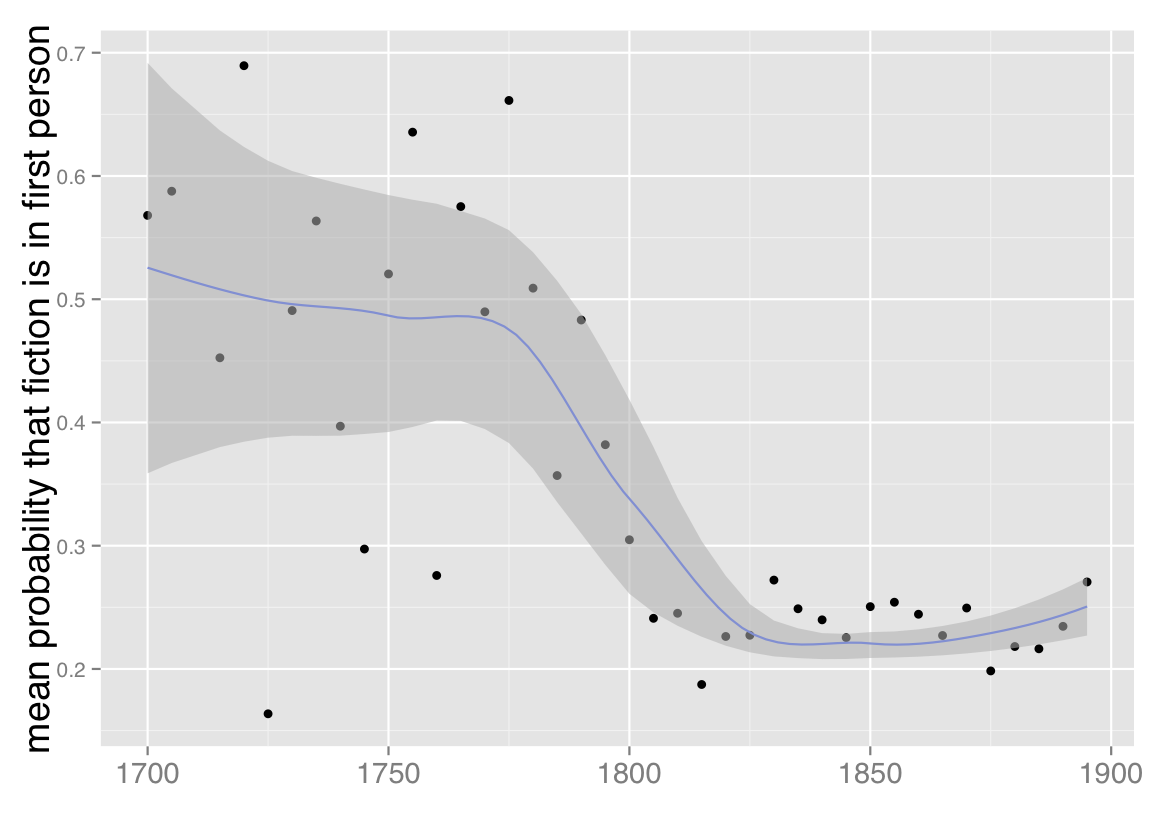
3) The declining prevalence of first-person narration. Once we’ve identified this fiction workset, we switch gears to consider point of view — frankly, because it’s a temptingly easy problem with clear literary significance. Though the fiction workset we’re using is defined more narrowly than it was last February, we confirm the result I glimpsed at that point, which is that the prevalence of first-person point of view declines significantly toward the end of the eighteenth century and then remains largely stable for the nineteenth.
Mean probability that fiction is written in first person, 1700-1899. Based on a corpus of 32,209 volumes of fiction extracted from HathiTrust Digital Library. Points are mean probabilities for five-year spans of time; a trend line with standard errors has been plotted with loess smoothing.
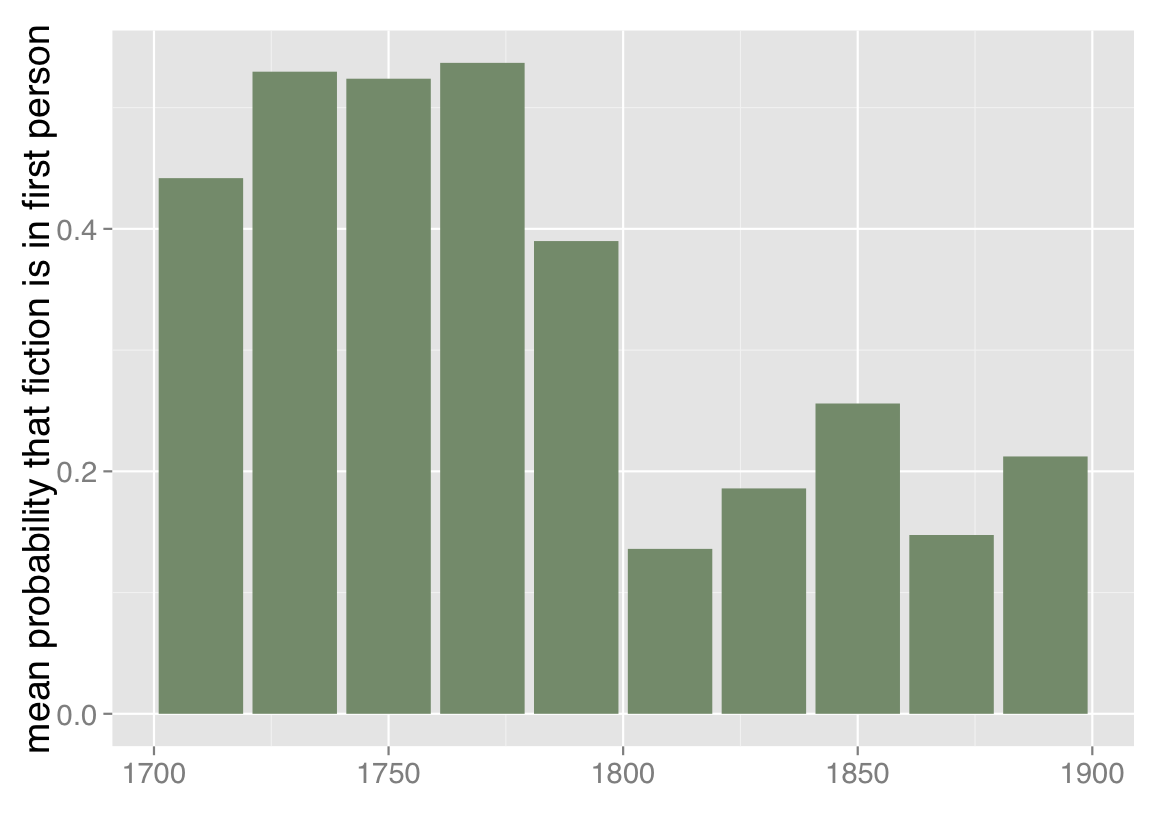
We can also confirm that result in a way I’m finding increasingly useful, which is to test it in a collection of a completely different sort. The HathiTrust collection includes reprints, which means that popular works have more weight in the collection than a novel printed only once. It also means that many volumes carry a date much later than their first date of publication. In some ways this gives a more accurate picture of print culture (an approximation to “what everyone read,” to borrow Scott Weingart’s phrase), but one could also argue for a different kind of representativeness, where each volume would be included only once, in a record dated to its first publication (an attempt to represent “what everyone wrote”).
Mean probability that fiction is written in first person, 1700-1899. Based on a corpus of 774 volumes of fiction selected by multiple hands from multiple sources. Plotted in 20-year bins because n is smaller here. Works are weighted by the number of words they contain.
Fortunately, Jordan Sellers and I produced a collection like that a few years ago, and we can run the same point-of-view classifier on this very different set of 774 fiction volumes (metadata available), selected by multiple hands from multiple sources (including TCP-ECCO, the Brown Women Writers Project, and the Internet Archive). Doing that reveals broadly the same trend line we saw in the HathiTrust collection. No collection can be absolutely representative (for one thing, because we don’t agree on what we ought to be representing). But discovering parallel results in collections that were constructed very differently does give me some confidence that we’re looking at a real trend.
4. Gender and point of view. In the process of classifying works of fiction, we stumbled on interesting thematic patterns associated with point of view. Features associated with first-person perspective include first-person pronouns, obviously, but also number words and words associated with sea travel. Some of this association may be explained by the surprising persistence of a particular two-century-long genre, the Robinsonade. A castaway premise obviously encourages first-person narration, but the colonial impulse in the Robinsonade also seems to have encouraged acquisitive enumeration of the objects (goats, barrels, guns, slaves) its European narrators find on ostensibly deserted islands. Thus all the number words. (But this association of first-person perspective with colonial settings and acquisitive enumeration may well extend beyond the boundaries of the Robinsonade to other genres of adventure fiction.)
Third-person perspective, on the other hand, is durably associated with words for domestic relationships (husband, lover, marriage). We’re still trying to understand these associations; they could be consequences of a preference for third-person perspective in, say, courtship fiction. But third-person pronouns correlate particularly strongly with words for feminine roles (girl,daughter,woman) — which suggests that there might also be a more specifically gendered dimension to this question.
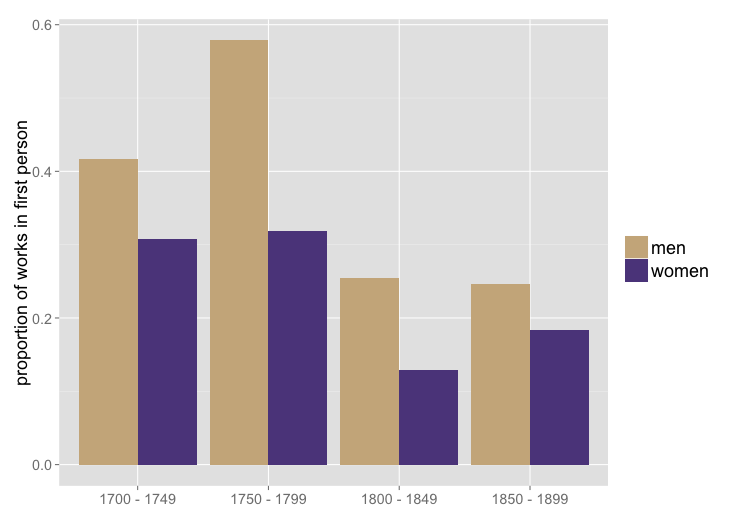
Since transmitting our paper to the IEEE I’ve had a chance to investigate this hypothesis in the smaller of the two collections we used for that paper — 774 works of fiction between 1700 and 1899: 521 by men, 249 by women, and four not characterized by gender. (Mike Black and Jordan Sellers recorded this gender data by hand.) In this collection, it does appear that male writers choose first-person perspective significantly more than women do. The gender gap persists across the whole timespan, although it might be fading toward the end of the nineteenth century.
Proportion of works of fiction by men and women in first person. Based on the same set of 774 volumes described above. (This figure counts strictly by the number of works rather than weighting works by the number of words they contain.)
Over the whole timespan, women use first person in roughly 23% of their works, and men use it in roughly 35% of their works.** That’s not a huge difference, but in relative terms it’s substantial. (Men are using first person 52% more than women). The Bayesian mafia have made me wary of p-values, but if you still care: a chi-squared test on the 2×2 contingency table of gender and point of view gives p < 0.001. (Attentive readers may already be wondering whether the decline of first person might be partly explained by an increase in the proportion of women writers. But actually, in this collection, works by women have a distribution that skews slightly earlier than that of works by men.)
These are very preliminary results. 774 volumes is a small set when you could test 32,209. At the recent HTRC Uncamp, Stacy Kowalczyk described a method for gender identification in the larger HathiTrust corpus, which we will be eager to borrow once it’s published. Also, the mere presence of an association between gender and point of view doesn’t answer any of the questions literary critics will really want to pose about this phenomenon — like, why is point of view associated with gender? Is this actually a direct consequence of gender, or is it an indirect consequence of some other variable like genre? Does this gendering of narrative perspective really fade toward the end of the nineteenth century? I don’t pretend to have answered any of those questions, all I’m doing here is flagging the existence of an interesting open question that will deserve further inquiry.
** We don’t actually represent point of view as a binary choice between first person or third person; the classifier reports probabilities as a continuous range between 0 and 1. But for purposes of this blog post I’ve simplified by dividing the works into two sets at the 0.5 mark. On this point, and for many other details of quantitative methodology, you’ll want to consult the paper itself.
In recent months I’ve had several conversations with colleagues who are friendly to digital methods but wary of claims about novelty that seem overstated. They believe that text mining can add a new level of precision to our accounts of literary history, or add a new twist to an existing debate. They just don’t think it’s plausible that quantification will uncover fundamentally new evidence, or patterns we didn’t previously expect.
If I understand my friends’ skepticism correctly, it’s founded less on a narrow objection to text mining than on a basic premise about the nature of literary study. And where the history of the discipline is concerned, they’re arguably right. In fact, the discipline of literary studies has not usually advanced by uncovering unexpected evidence. As grad students, that’s not what we were taught to aim for. Instead we learned that the discipline moves forward dialectically. You take something that people already believe and “push against” it, or “critique” it, or “complicate” it. You don’t make discoveries in literary study, or if you do they’re likely to be minor — a lost letter from Byron to his tailor. Instead of making discoveries, you make interventions — a telling word.
The broad contours of our discipline are already known, so nothing can grow without displacing something else.
So much flows from this assumption. If we’re not aiming for discovery, if the broad contours of literary history are already known, then methodological conversation can only be a zero-sum game. That’s why, when I say “digital methods don’t have to displace traditional scholarship,” my colleagues nod politely but assume it’s insincere happy talk. They know that in reality, the broad contours of our discipline are already known, and anything within those boundaries can only grow by displacing something else.
These are the assumptions I was also working with until about three years ago. But a couple of years of mucking about in digital archives have convinced me that the broad contours of literary history are not in fact well understood.
For instance, I just taught a course called Introduction to Fiction, and as part of that course I talk about the importance of point of view. You can characterize point of view in a lot of subtle ways, but the initial, basic division is between first-person and third-person perspectives.
Suppose some student had asked the obvious question, “Which point of view is more common? Is fiction mostly written in the first or third person? And how long has it been that way?” Fortunately undergrads don’t ask questions like that, because I couldn’t have answered.
I have a suspicion that first person is now used more often in literary fiction than in novels for a mass market, but if you ask me to defend that — I can’t. If you ask me how long it’s been that way — no clue. I’ve got a Ph.D in this field, but I don’t know the history of a basic formal device. Now, I’m not totally ignorant. I can say what everyone else says: “Jane Austen perfected free indirect discourse. Henry James. Focalizing character. James Joyce. Stream of consciousness. Etc.” And three years ago that might have seemed enough, because the bigger, simpler question was obviously unanswerable and I wouldn’t have bothered to pose it.
But recently I’ve realized that this question is answerable. We’ve got large digital archives, so we could in principle figure out how the proportions of first- and third-person narration have changed over time.
You might reasonably expect me to answer that question now. If so, you underestimate my commitment to the larger thesis here: that we don’t understand literary history. I will eventually share some new evidence about the history of narration. But first I want to stress that I’m not in a position to fully answer the question I’ve posed. For three reasons:
1) Our digital collections are incomplete. I’m working with a collection of about 700,000 18th and 19th-century volumes drawn from HathiTrust.
That’s a lot. But it’s not everything that was written in the English language, or even everything that was published.
2) This is work in progress. For instance, I’ve cleaned and organized the non-serial part of the collection (about 470,000 volumes), but I haven’t started on the periodicals yet. Also, at the moment I’m counting volumes rather than titles, so if a book was often reprinted I count it multiple times. (This could be a feature or a bug depending on your goals.)
3) Most importantly, we can’t answer the question because we don’t fully understand the terms we’re working with. After all, what is “first-person narration?”
The truth is that the first person comes in a lot of different forms. There are cases where the narrator is also the protagonist. That’s pretty straightforward. Then epistolary novels. Then there are cases where the narrator is anonymous — and not a participant in the action — but sometimes refers to herself as I. Even Jane Austen’s narrator sometimes says “I.” Henry Fielding’s narrator does it a lot more. Should we simply say this is third-person narration, or should we count it as a move in the direction of first? Then, what are we going to do about books like Bleak House? Alternating chapters of first and third person. Maybe we call that 50% first person? — or do we assign it to a separate category altogether? What about a novel like Dracula, where journals and letters are interspersed with news clippings?
Suppose we tried to crowdsource this problem. We get a big team together and decide to go through half a million volumes, first of all to identify the ones that are fiction, and secondly, if a volume is fiction, to categorize the point of view. Clearly, it’s going to be hard to come to agreement on categories. We might get halfway through the crowdsourcing process, discover a new category, and have to go back to the drawing board.
Notice that I haven’t mentioned computers at all yet. This is not a problem created by computers, because they “only understand binary logic.” It’s a problem created by us. Distant reading is hard, fundamentally, because human beings don’t agree on a shared set of categories. Franco Moretti has a well-known list of genres, for instance, in Graphs, Maps, Trees. But that list doesn’t represent an achieved consensus. Moretti separates the eighteenth-century gothic novel from the late-nineteenth-century “imperial gothic.” But for other critics, those are two parts of the same genre. For yet other critics, the “gothic” isn’t a genre at all; it’s a mode like tragedy or satire, which is why gothic elements can pervade a bunch of different genres.
This is the darkest moment of this post. It may seem that there’s no hope for literary historians. How can we ever know anything if we can’t even agree on the definitions of basic concepts like genre and point of view? But here’s the crucial twist — and the real center of what I want to say. The blurriness of literary categories is exactly why it’s helpful to use computers for distant reading. With an algorithm, we can classify 500,000 volumes provisionally. Try defining point of view one way, and see what you get. If someone else disagrees, change the definition; you can run the algorithm again overnight. You can’t re-run a crowdsourced cataloguing project on 500,000 volumes overnight.
Second, algorithms make it easier to treat categories as plural and continuous. Although Star Trek teaches us otherwise, computers do not start to stammer and emit smoke if you tell them that an object belongs in two different categories at once. Instead of sorting texts into category A or category B, we can assign degrees of membership to multiple categories. As many as we want. So The Moonstone can be 80% similar to a sensation novel and 50% similar to an imperial gothic, and it’s not a problem. Of course critics are still going to disagree about individual cases. And we don’t have to pretend that these estimates are precise characterizations of The Moonstone. The point is that an algorithm can give us a starting point for discussion, by rapidly mapping a large collection in a consistent but flexibly continuous way.
Then we can ask, Does the gothic often overlap with the sensation novel? What other genres does it overlap with? Even if the boundaries are blurry, and critics disagree about every individual case — even if we don’t have a perfect definition of the term “genre” itself — we’ve now got a map, and we can start talking about the relations between regions of the map.
Can we actually do this? Can we use computers to map things like genre and point of view? Yes, to coin a phrase, we can. The truth is that you can learn a lot about a document just by looking at word frequency. That’s how search engines work, that’s how spam gets filtered out of your e-mail; it’s a well-developed technology. The Stanford Literary Lab suggested a couple of years ago that it would probably work for literary genres as well (see Pamphlet 1), and Matt Jockers has more detailed work forthcoming on genre and diction in Macroanalysis.
There are basically three steps to the process. First, get a training set of a thousand or so examples and tag the categories you want to recognize: poetry or prose, fiction or nonfiction, first- or third-person narration. Then, identify features (usually words) that turn out to provide useful clues about those categories. There are a lot of ways of doing this automatically. Personally, I use a Wilcoxon test to identify words that are consistently common or uncommon in one class relative to others. Finally, train classifiers using those features. I use what’s known as an “ensemble” strategy where you train multiple classifiers and they all contribute to the final result. Each of the classifiers individually uses an algorithm called “naive Bayes,” which I’m not going to explain in detail here; let’s just say that collectively, as a group, they’re a little less “naive” than they are individually — because they’re each relying on slightly different sets of clues.
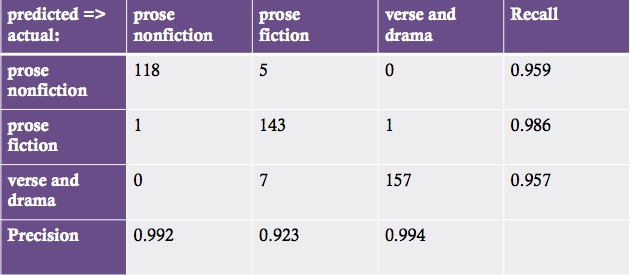
Confusion matrix from an ensemble of naive Bayes classifiers. (432 test documents held out from a larger sample of 1356.)
How accurate does this end up being? This confusion matrix gives you a sense. Let me underline that this is work in progress. If I were presenting finished results I would need to run this multiple times and give you an average value. But these are typical results. Here I’ve got a corpus of thirteen hundred nineteenth-century volumes. I train a set of classifiers on two-thirds of the corpus, and then test it by using it to classify the other third of the corpus which it hasn’t yet seen. That’s what I mean by saying 432 documents were “held out.” To make the accuracy calculations simple here, I’ve treated these categories as if they were exclusive, but in the long run, we don’t have to do that: documents can belong to more than one at once.
These results are pretty good, but that’s partly because this test corpus didn’t have a lot of miscellaneous collected works in it. In reality you see a lot of volumes that are a mosaic of different genres — the collected poems and plays of so-and-so, prefaced by a prose life of the author, with an index at the back. Obviously if you try to classify that volume as a single unit, it’s going to be a muddle. But I think it’s not going to be hard to use genre classification itself to segment volumes, so that you get the introduction, and the plays, and the lyric poetry sorted out as separate documents. I haven’t done that yet, but it’s the next thing on my agenda.
One complication I have already handled is historical change. Following up a hint from Michael Witmore, I’ve found that it’s useful to train different classifiers for different historical periods. Then when you get an uncategorized document, you can have each classifier make a prediction, and weight those predictions based on the date of the document.
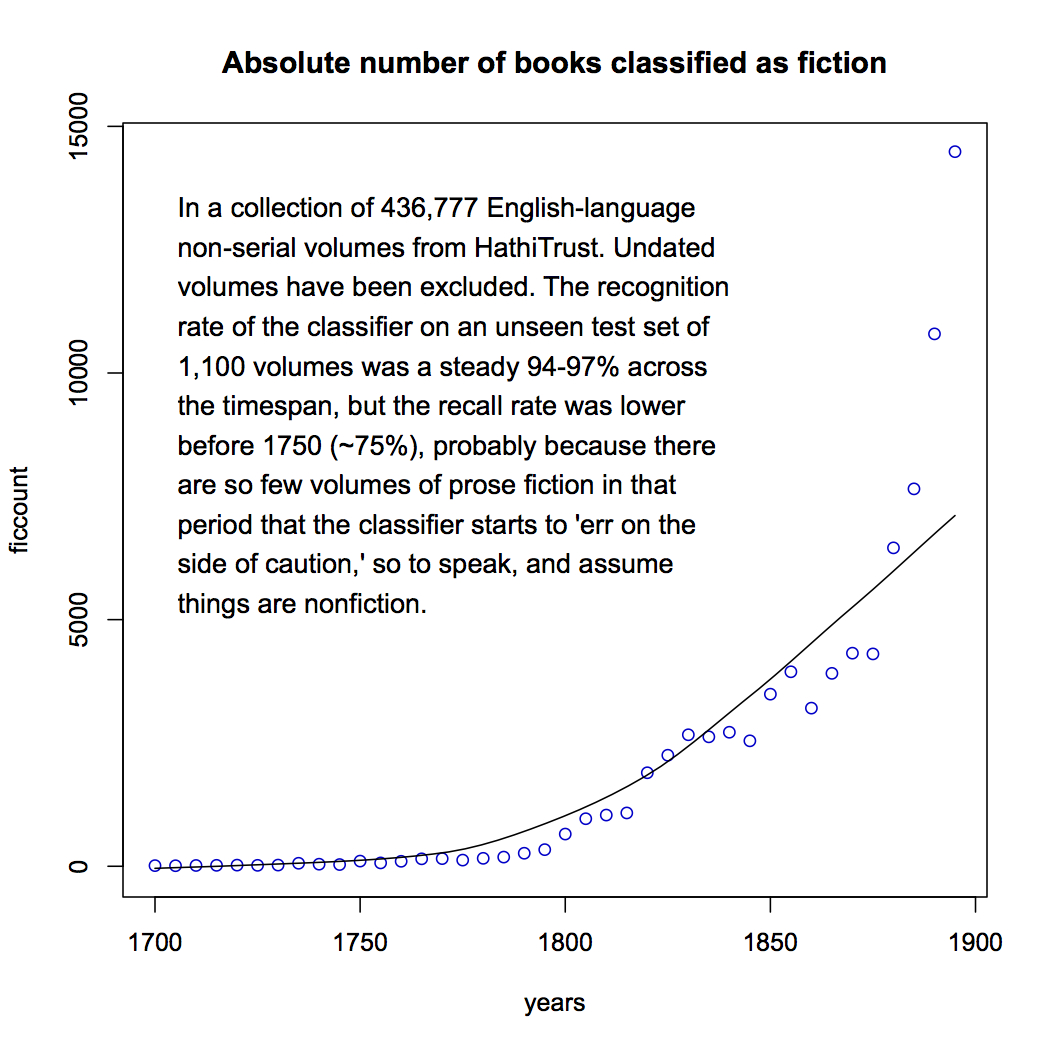
So what have I found? First of all, here’s the absolute number of volumes I was able to identify as fiction in HathiTrust’s collection of eighteenth and nineteenth-century English-language books. Instead of plotting individual years, I’ve plotted five-year segments of the timeline. The increase, of course, is partly just an absolute increase in the number of books published.
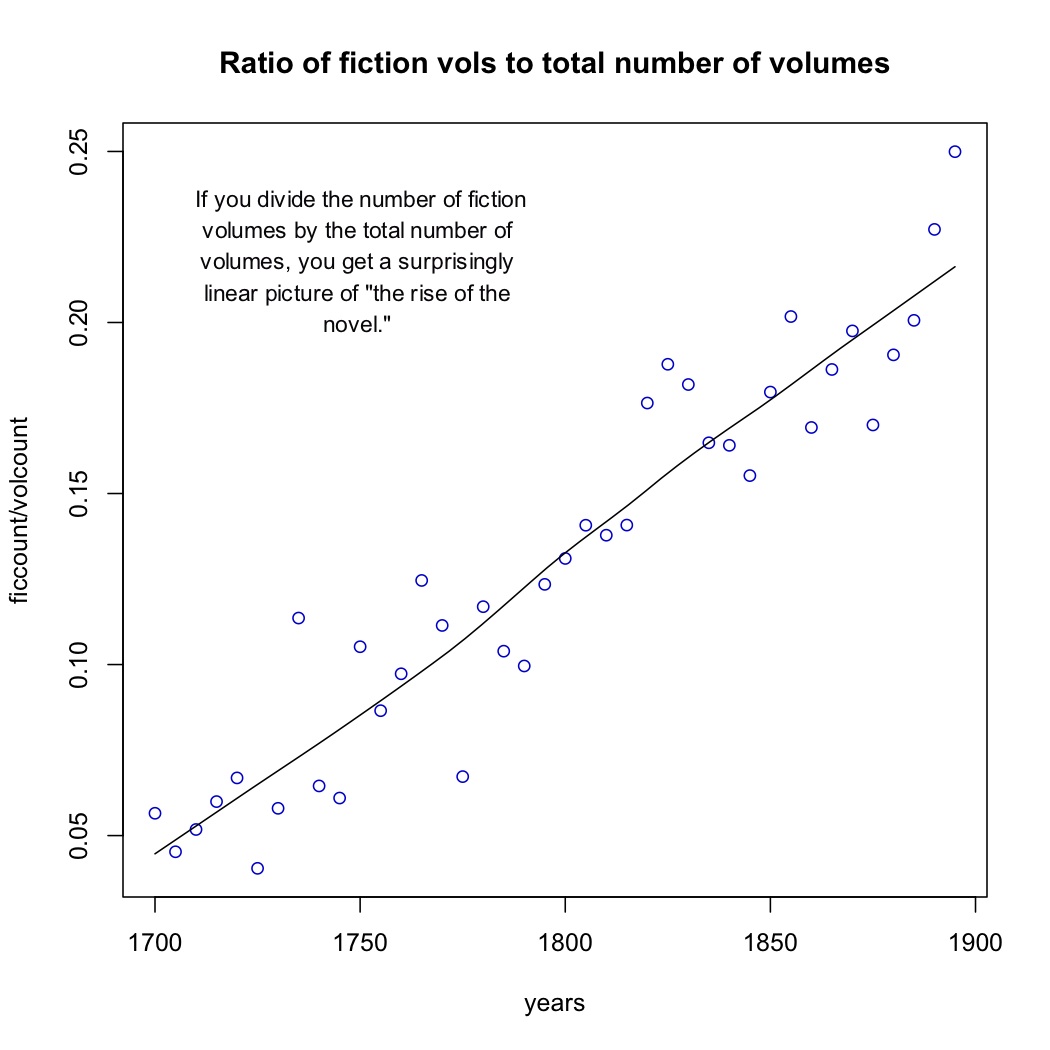
But it’s also an increase specifically in fiction. Here I’ve graphed the number of volumes of fiction divided by the total number of volumes in the collection. The proportion of fiction increases in a straightforward linear way. From 1700-1704, when fiction is only about 5% of the collection, to 1895-99, when it’s 25%. People better-versed in book history may already have known that this was a linear trend, but I was a bit surprised. (I should note that I may be slightly underestimating the real numbers before 1750, for reasons explained in the fine print to the earlier graph — basically, it’s hard for the classifier to find examples of a class that is very rare.)
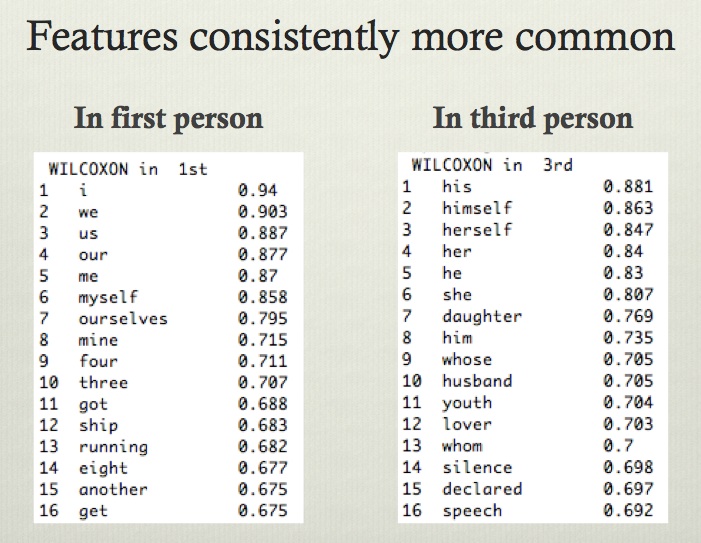
Features consistently more common in first- or third-person narration, ranked by Mann-Whitney-Wilcoxon rho.
What about the question we started with — first-person narration? I approach this the same way I approached genre classification. I trained a classifier on 290 texts that were clearly dominated by first- or third-person narration, and used a Wilcoxon test to select features that are consistently more common in one set or in the other.
Now, it might seem obvious what these features are going to be: obviously, we would expect first-person and third-person pronouns to be the most important signal. But I’m allowing the classifier to include whatever features it in practice finds. For instance, terms for domestic relationships like “daughter” and “husband” and the relative pronouns “whose” and “whom” are also consistently more common in third-person contexts, and oddly, numbers seem more common in first-person contexts. I don’t know why that is yet; this is work in progress and there’s more exploration to do. But for right now I haven’t second-guessed the classifier; I’ve used the top sixteen features in both lists whether they “make sense” or not.
And this is what I get. The classifier predicts each volume’s probability of belonging to the class “first person.” That can be anywhere between 0 and 1, and it’s often in the middle (Bleak House, for instance, is 0.54). I’ve averaged those values for each five-year interval. I’ve also dropped the first twenty years of the eighteenth century, because the sample size was so low there that I’m not confident it’s meaningful.
Now, there’s a lot more variation in the eighteenth century than in the nineteenth century, partly because the sample size is smaller. But even with that variation it’s clear that there’s significantly more first-person narration in the eighteenth century. About half of eighteenth-century fiction is first-person, and in the nineteenth century that drops down to about a quarter. That’s not something I anticipated. I expected that there might be a gradual decline in the amount of first-person narration, but I didn’t expect this clear and relatively sudden moment of transition. Obviously when you see something you don’t expect, the first question you ask is, could something be wrong with the data? But I can’t see a source of error here. I’ve cleaned up most of the predictable OCR errors in the corpus, and there aren’t more medial s’s in one list than in the other anyway.
And perhaps this picture is after all consistent with our expectations. Eleanor Courtemanche points out that the timing of the shift to third person is consistent with Ian Watt’s account of the development of omniscience (as exemplified, for instance, in Austen). In a quick twitter poll I carried out before announcing the result, Jonathan Hope did predict that there would be a shift from first-person to third-person dominance, though he expected it to be more gradual. Amanda French may have gotten the story up to 1810 exactly right, although she expected first-person to recover in the nineteenth century. I expected a gradual decline of first-person to around 1810, and then a gradual recovery — so I seem to have been completely wrong.
The ratio between raw counts of first- and third-person pronouns in fiction.
Much more could be said about this result. You could decide that I’m wrong to let my classifier use things like numbers and relative pronouns as clues about point of view; we could restrict it just to counting personal pronouns. (That won’t change the result very significantly, as you can see in the illustration on the right — which also, incidentally, shows what happens in those first twenty years of the eighteenth century.) But we could refine the method in many other ways. We could exclude pronouns in direct discourse. We could break out epistolary narratives as a separate category.
All of these things should be tried. I’m explicitly not claiming to have solved this problem yet. Remember, the thesis of this talk is that we don’t understand literary history. In fact, I think the point of posing these questions on a large scale is partly to discover how slippery they are. I realize that to many people that will seem like a reason not to project literary categories onto a macroscopic scale. It’s going to be a mess, so — just don’t go there. But I think the mess is the reason to go there. The point is not that computers are going to give us perfect knowledge, but that we’ll discover how much we don’t know.
For instance, I haven’t figured out yet why numbers are common in first-person narrative, but I suspect it might be because there’s a persistent affinity with travel literature. As we follow up leads like that we may discover that we don’t understand point of view itself as well as we assume.
It’s this kind of complexity that will ultimately make classification interesting. It’s not just about sorting things into categories, but about identifying the places where a category breaks down or has changed over time. I would draw an analogy here to a paper on “Gender in Twitter” recently published by a group of linguists. They used machine learning to show that there are not two but many styles of gender performance on Twitter. I think we’ll discover something similar as we explore categories like point of view and genre. We may start out trying to recognize known categories, like first-person narration. But when you sort a large collection into categories, the collection eventually pushes back on your categories as much as the categories illuminate the collection.
Acknowledgments: This research was supported by the Andrew W. Mellon Foundation through “Expanding SEASR Services” and “The Uses of Scale in Literary Study.” Loretta Auvil, Mike Black, and Boris Capitanu helped develop resources for normalizing 18/19c OCR, many of which are public at usesofscale.com. Jordan Sellers developed the initial training corpus of 19c documents categorized by genre.