
A paper for the IEEE “big humanities” workshop, written in collaboration with Michael L. Black, Loretta Auvil, and Boris Capitanu, is available on arXiv now as a preprint.
The Institute of Electrical and Electronics Engineers is an odd venue for literary history, and our paper ends up touching so many disciplinary bases that it may be distracting.* So I thought I’d pull out four issues of interest to humanists and discuss them briefly here; I’m also taking the occasion to add a little information about gender that we uncovered too late to include in the paper itself.
1) The overall point about genre. Our title, “Mapping Mutable Genres in Structurally Complex Volumes,” may sound like the sort of impossible task heroines are assigned in fairy tales. But the paper argues that the blurry mutability of genres is actually a strong argument for a digital approach to their history. If we could start from some consensus list of categories, it would be easy to crowdsource the history of genre: we’d each take a list of definitions and fan out through the archive. But centuries of debate haven’t yet produced stable definitions of genre. In that context, the advantage of algorithmic mapping is that it can be comprehensive and provisional at the same time. If you change your mind about underlying categories, you can just choose a different set of training examples and hit “run” again. In fact we may never need to reach a consensus about definitions in order to have an interesting conversation about the macroscopic history of genre.
2) A workset of 32,209 volumes of English-language fiction. On the other hand, certain broad categories aren’t going to be terribly controversial. We can probably agree about volumes — and eventually specific page ranges — that contain (for instance) prose fiction and nonfiction, narrative and lyric poetry, and drama in verse, or prose, or some mixture of the two. (Not to mention interesting genres like “publishers’ ads at the back of the volume.”) As a first pass at this problem, we extract a workset of 32,209 volumes containing prose fiction from a collection of 469,200 eighteenth- and nineteenth-century volumes in HathiTrust Digital Library. The metadata for this workset is publicly available from Illinois’ institutional repository. More substantial page-level worksets will soon be produced and archived at HathiTrust Research Center.
3) The declining prevalence of first-person narration. Once we’ve identified this fiction workset, we switch gears to consider point of view — frankly, because it’s a temptingly easy problem with clear literary significance. Though the fiction workset we’re using is defined more narrowly than it was last February, we confirm the result I glimpsed at that point, which is that the prevalence of first-person point of view declines significantly toward the end of the eighteenth century and then remains largely stable for the nineteenth.
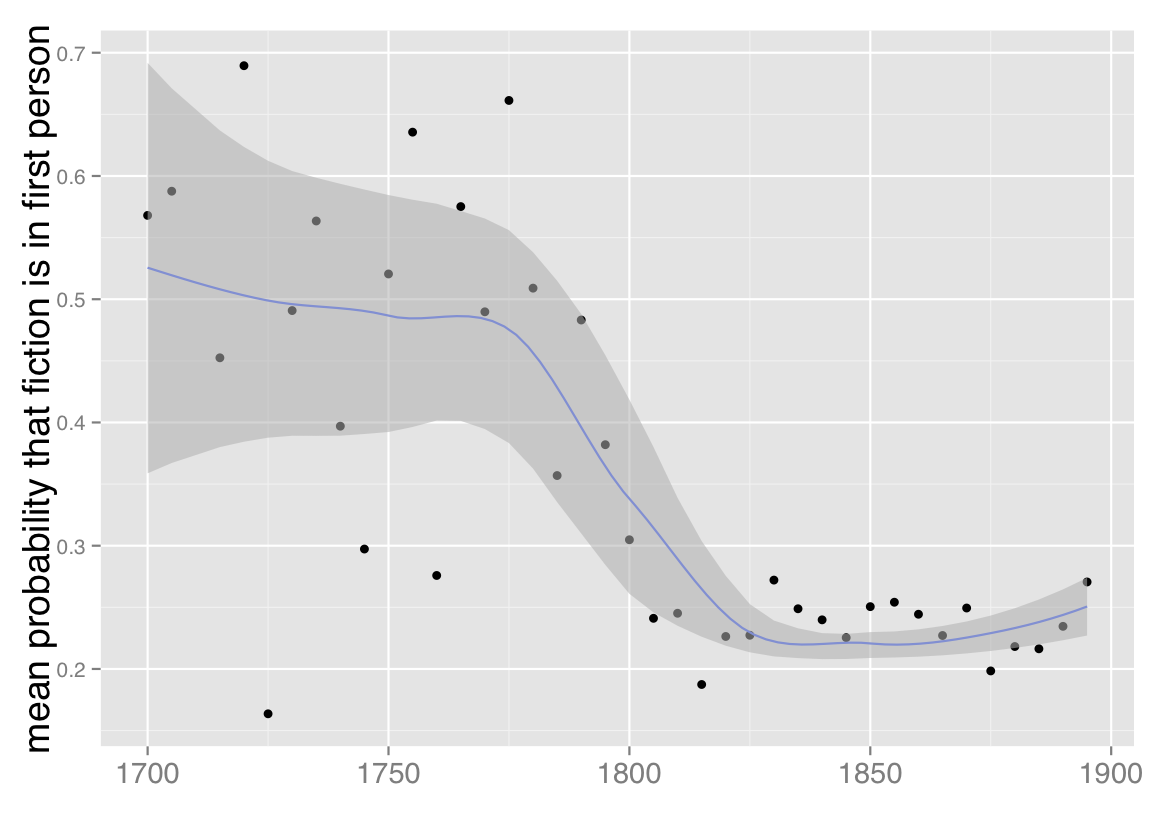
We can also confirm that result in a way I’m finding increasingly useful, which is to test it in a collection of a completely different sort. The HathiTrust collection includes reprints, which means that popular works have more weight in the collection than a novel printed only once. It also means that many volumes carry a date much later than their first date of publication. In some ways this gives a more accurate picture of print culture (an approximation to “what everyone read,” to borrow Scott Weingart’s phrase), but one could also argue for a different kind of representativeness, where each volume would be included only once, in a record dated to its first publication (an attempt to represent “what everyone wrote”).
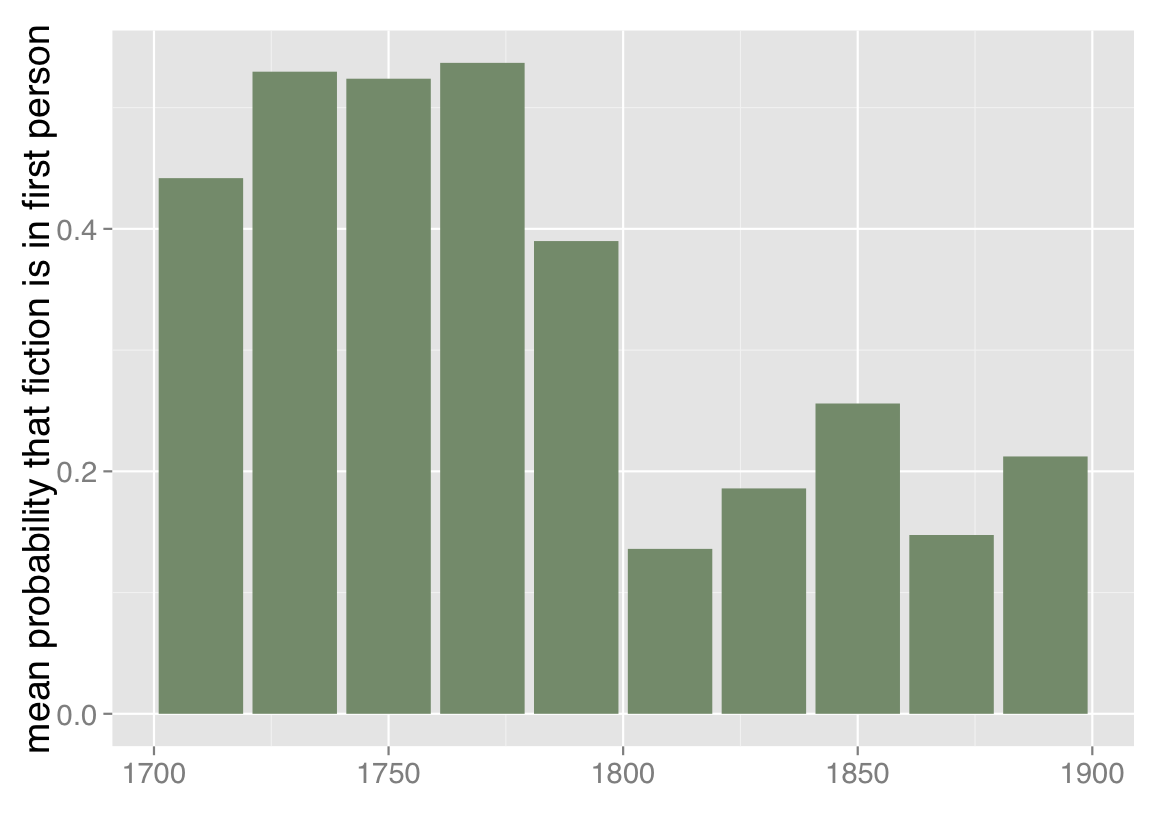
Fortunately, Jordan Sellers and I produced a collection like that a few years ago, and we can run the same point-of-view classifier on this very different set of 774 fiction volumes (metadata available), selected by multiple hands from multiple sources (including TCP-ECCO, the Brown Women Writers Project, and the Internet Archive). Doing that reveals broadly the same trend line we saw in the HathiTrust collection. No collection can be absolutely representative (for one thing, because we don’t agree on what we ought to be representing). But discovering parallel results in collections that were constructed very differently does give me some confidence that we’re looking at a real trend.
4. Gender and point of view. In the process of classifying works of fiction, we stumbled on interesting thematic patterns associated with point of view. Features associated with first-person perspective include first-person pronouns, obviously, but also number words and words associated with sea travel. Some of this association may be explained by the surprising persistence of a particular two-century-long genre, the Robinsonade. A castaway premise obviously encourages first-person narration, but the colonial impulse in the Robinsonade also seems to have encouraged acquisitive enumeration of the objects (goats, barrels, guns, slaves) its European narrators find on ostensibly deserted islands. Thus all the number words. (But this association of first-person perspective with colonial settings and acquisitive enumeration may well extend beyond the boundaries of the Robinsonade to other genres of adventure fiction.)
Third-person perspective, on the other hand, is durably associated with words for domestic relationships (husband, lover, marriage). We’re still trying to understand these associations; they could be consequences of a preference for third-person perspective in, say, courtship fiction. But third-person pronouns correlate particularly strongly with words for feminine roles (girl, daughter, woman) — which suggests that there might also be a more specifically gendered dimension to this question.
Since transmitting our paper to the IEEE I’ve had a chance to investigate this hypothesis in the smaller of the two collections we used for that paper — 774 works of fiction between 1700 and 1899: 521 by men, 249 by women, and four not characterized by gender. (Mike Black and Jordan Sellers recorded this gender data by hand.) In this collection, it does appear that male writers choose first-person perspective significantly more than women do. The gender gap persists across the whole timespan, although it might be fading toward the end of the nineteenth century.
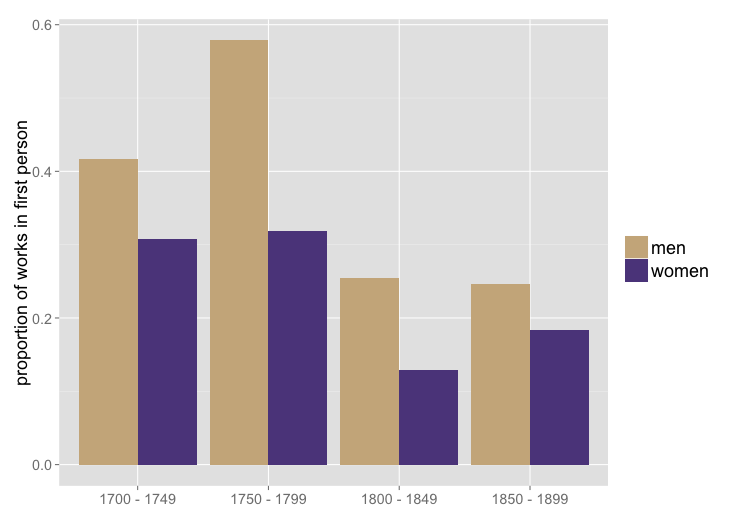
Over the whole timespan, women use first person in roughly 23% of their works, and men use it in roughly 35% of their works.** That’s not a huge difference, but in relative terms it’s substantial. (Men are using first person 52% more than women). The Bayesian mafia have made me wary of p-values, but if you still care: a chi-squared test on the 2×2 contingency table of gender and point of view gives p < 0.001. (Attentive readers may already be wondering whether the decline of first person might be partly explained by an increase in the proportion of women writers. But actually, in this collection, works by women have a distribution that skews slightly earlier than that of works by men.)
These are very preliminary results. 774 volumes is a small set when you could test 32,209. At the recent HTRC Uncamp, Stacy Kowalczyk described a method for gender identification in the larger HathiTrust corpus, which we will be eager to borrow once it’s published. Also, the mere presence of an association between gender and point of view doesn’t answer any of the questions literary critics will really want to pose about this phenomenon — like, why is point of view associated with gender? Is this actually a direct consequence of gender, or is it an indirect consequence of some other variable like genre? Does this gendering of narrative perspective really fade toward the end of the nineteenth century? I don’t pretend to have answered any of those questions, all I’m doing here is flagging the existence of an interesting open question that will deserve further inquiry.
— — — — —
*Other papers for the panel are beginning to appear online. Here’s “Infectious Texts: Modeling Text Reuse in Nineteenth-Century Newspapers,” by David A. Smith, Ryan Cordell, and Elizabeth Maddock Dillon.
** We don’t actually represent point of view as a binary choice between first person or third person; the classifier reports probabilities as a continuous range between 0 and 1. But for purposes of this blog post I’ve simplified by dividing the works into two sets at the 0.5 mark. On this point, and for many other details of quantitative methodology, you’ll want to consult the paper itself.

28 replies on “Genre, gender, and point of view.”
Representativeness in corpora is much less of an issue than you think it is here – Douglas Biber has written a very influential paper (“Representativeness in Corpus Design”, available here as a PDF: http://t.co/wUsn2o58eY), which is worth a read and more than a passing consideration. I’d highly recommend seeing how others have used this paper and its implications in the past twenty years or so, too – this is not a new problem, and there have been many suggestions about how to handle representativeness.
I’m not really surprised by your results by gender here, but i’m wondering how much your corpus is skewed by male characters/female characters/”other” (though I’m really appreciating your classifying system as a range – i might be borrowing that in the future). That would be very much worth following up on, and critically interrogating why you were so surprised by the results in the first place (it follows some of David Bamman et al’s work on persona, and much of my work on gender in early modern plays.)
Given that you have so many tools to verify and/or cross reference your results (you mention MI scores in the paper) I’m kind of surprised you didn’t do that, as I feel it would be a really productive way to test one machine-learning algorithm against another – but i suppose that can be saved for the follow-up paper!
Thanks, Heather. Just to unpack that point about character for readers who may not make the connection: you’re alluding to excellent work by David Bamman, et. al., and by yourself which shows that there are many more male than female characters in drama and screenplays, from Shakespeare’s time to our own. It’s a pretty safe bet that this is also true in fiction — though counting all the characters in 32,209 volumes of fiction is going to be a non-trivial task any way we approach it!
But if I’m getting this right, the question you’re implicitly posing is how the prevalence of male characters might affect the choice of narrative point of view when an author is female. That seems to me a good question, and a very possible explanation for the gender disparity. We know (anecdotally) that it’s relatively rare for authors to do first-person in the voice of a character of another gender. So if women writers were in some sense compelled to follow the more-male-characters rule, they might have found it hard to write in the first person. It’s hard to be certain about the direction of causality there, but it’s definitely a strong hypothesis, with implications worth exploring.
It seems very reasonable to assume that what David and I have shown would extend into literary fiction as well – and if it doesn’t, well, that would be extremely interesting, and very much worth finding out about. I’m thinking that addressing texts in terms of “how many of them are there” won’t be as useful or productive as asking as “how long is each text, and how many total words do you have, and how can you draw comparisons across them”. I get the sense that considering the texts to be uniform objects (regardless of genre or style) is probably not the best way to do this.
And while that’s an interesting question to pose, I’d be more curious about the co-occurance of female/male characters and their corresponding nouns compared to the cooccurance of 1st person pronouns and their corresponding nouns. I’m not convinced that 1st/3rd person pronouns are completely comparable, as they do a lot of different things syntactically. It’d be worth checking out some studies on grammatical gender before you dive into this more thoroughly – I’d be very curious to see what the larger implications of co-occurance, as verified across several algorithms, might be.
Although we didn’t report these particular findings, it’s worth pointing out that in the data analysis for http://llc.oxfordjournals.org/content/28/3/404.full, Jorgensen and I found that in 230 fairytales, Female tale tellers used female protagonists about 58% of the time, and male tellers spoke of male protagonists about 55% of the time. Of the ~10,000 mentions of people/bodies in the tales, female tellers referenced women and female bodies 59% of the time, and male tellers referenced men and male bodies 46% of the time (although their protagonists were more often male, they more often discussed women and their bodies).
I know the genre is quite different, but regarding point-of-view particularly, women were referred to as women (using gendered language) more than expected, and were described with various adjectives more than expected. Men were described as men, and described, less than expected. We hypothesized that this meant that the default gender for the teller or audience was male: if someone’s a guy, it’s not worth mentioning they’re a guy. I feel like there may be an interplay with POV here, but because of the nature of the genre, it would be hard to compare.
We didn’t extract the data automatically; Jorgensen did this by hand as part of her dissertation work. If this could be done automatically (and it increasingly seems likely, at least with probabilities attached as Underwood describes), it might provide a slightly different angle to analyze these data, esp. concerning the gender of the protagonist, whether in first or third person, as it relates to the gender of the author.
Thanks, Scott. I think the evidence you’re describing may complicate some assumptions about gender we would otherwise use by default. And that kind of complication is why I’m comfortable just casually sharing the evidence about gender and point of view without trying to answer the “why” question first myself. I think explaining this evidence is likely to be difficult, and likely to take a long time.
Re “representativeness,” I think we’re simply working in different disciplines, Heather, with different rhetorical practices. Corpus linguistics is a quantitative discipline that views representation as a relatively straightforward problem. “First, define the population you want to represent …” I appreciate that, and it’s possible that literary scholars should develop a similar consensus. But I know from long experience that we don’t work that way. We love arguing about representation way too much to define it.
In literary studies, the way these conversations play out in practice is this: no matter what population you attempt to represent, a critic will materialize to point out that you could be representing a different object. If your sample is stratified, you’re neglecting the reality that different groups had different levels of access to print. If your corpus is organized around dates of composition, you’re neglecting the question of reading. And so on. I don’t think I’m being cynical when I say that the real point of these interventions is not to more sharply define a population, but to dramatize our collective disciplinary uneasiness with any quantitative model of representation.
That’s why I’ve come to the conclusion that I always have to be working with at least two differently-organized collections. It’s a solution to a rhetorical problem as much as an intellectual one. Rhetorically, I can’t treat representation as a settled question, because literary scholars just won’t go for it. In fact, the clearer I am about definitions of representation, the less they’ll go for it. 🙂
I disagree with the dichotomy you’re setting up here, mostly because i’m unconvinced that what you’re doing is completely alien to corpus linguistics, and that corpus linguistics is completely alien to literary studies. I’m loathe to invoke the “if digital humanities is truly interdisciplinary…” debate here, but I think a strong willingness acknowledge what has come before in any kind of computationally aided form of lexical analysis is necessary if you want to fully make your work accessible across a spectrum of scholars (not just siloing in LITERARY STUDIES, LINGUISTICS, COMPUTER SCIENCE…) but that’s just me.
I think it’s incredibly important to keep in mind that representativeness can be measured in a huge number of ways – by date, by author, by publication place, by genre, etc, as you point out above. Choosing one (or several) categories to measure representativeness by is not just a rhetorical but editorial choice, which i think many humanities scholars will accept. I agree that there’s a certain uneasiness amongst non-quantitative people about “what we’re missing” when we elect to privilege certain categories over others, but then, “completeness” isn’t really possible either. What you can show in a representational model should be suggestive of what the “complete” picture might show – after all, it’s why we have let literary studies which close read one author or one text stand as acceptable scholarship for year.
Well, as you know, I agree with you on the broader point of interdisciplinarity — as the publication venue for this IEEE paper might hint. We do cite A. Kilgarriff’s corpus-linguistic model of representation in that paper, as well as a number of literary scholars and people from different subfields of computer science. But there is always more work to be done: thanks for the Biber citation!
Did you control for the difference between epistolary and first-person narration?
OK, I’ve read the paper and I see where you do gesture towards this. You write,
“Explaining the decline of first-person perspective is proba- bly too large a task for a single article: this is a new piece of evidence for literary scholars, and it may take a few years for us to process it. But we do already know that eighteenth- century novelists enjoyed formal experiments that allowed fiction to masquerade as a real journal or autobiography or collection of letters. According to Ian Watt’s timeworn but durable thesis, the novel was in fact distinguished from earlier forms of fiction by this pretense of documenting arbitrary slices of individual experience [14]. And of course novels imitating autobiography and correspondence would need to rely heavily on first-person perspective. The change at the end of the eighteenth century is harder to explain. But there’s some consensus that this period saw significant advances in the management of third-person narration, arguably culminating in Jane Austen’s use of free indirect discourse, which allows readers to see through a character’s eyes while retaining a third-person narrator’s distanced judgment. These technical advances might have made third-person narration flexible enough that it could become a default norm in the nineteenth century. But this is speculative: there’s room here for much more discussion.”
This is a bit slippery. It seems you understate the case here pretty significantly. I wouldn’t say there’s “some consensus that this period saw significant advances in the management of third-person narration.” That seems to be an overwhelming consensus and even a kind of shoot-from-the-hip history of the novel we lay out for undergraduates on the first day of an introductory survey. A decline in first-person word groups in the shape of your graphs is exactly what we’d expect to see, just based on a cursory familiarity with novels of the period. That seems good, in that it demonstrates the viability of the quantitative approach, but it doesn’t seem to me at first glance that you’ve found anything yet that will take “years for us to process.” Quite the contrary. The divisions you describe by gender also seem to hew very closely to commonly accepted generalizations. Even though you’d have to tone down some of the declarations of “surprise,” I think the argument would be stronger if you included a more robust review of the secondary literature. Watt’s great, but that book’s now going on 60 years old. Other than him, I don’t see a single reference to any scholarship on the history of the novel — the putative subject of your research. I’d recommend McKeon, Davis, Armstrong, Gallagher, Spencer, Duncan, and others — but surely you know them and decided to exclude them. Why? That’s just strange. This is a common issue with interdisciplinary work, I suppose, and it might have to do with your sense of your audience and the *perceived* constraints of the article format. But why wouldn’t you want historians of the novel to be included in your conversation?
Anyway, I suppose this is just my own background in 18C literature skewing my reaction. It seems, though, that this method if followed through could be very effective with that messy dataset we anachronistically refer to as early novels. One of the interesting things about early novels, versus, say, those of the Romantic era and later, is that they appear in radically different forms, forms that should be readily apparent to your rigorous statistical methods.
I wonder what the next step is. Wouldn’t it be fairly easy to use your methodology to pull out epistolary novels from the dataset as a whole? Word groups around letters and numbers would pop out, I’d bet, as would the uses of the second person and the future tense. (I think you mention your surprise in the article that first-person narration depends less on “I” and “me” than on numbers. This seems, too, like what historians of the novel would expect.) What kinds of categories could we find? And how might they overlap with / conflict with our preexisting categories?
This seems like a very promising line of work, and a very exciting new methodology.
I can’t speak to the literary history, but regarding your last point, Michael, I think one of the issues here is the benefit of hindsight for justification. When you look at the results it is easy to say “yes, this would have been what historians would expect.” The problem is, you put 5 historians in a room to make predictions, and you’ll get 10 different ideas of what the most-likely first person narration signal might be (numbers being among them). The benefit of Ted’s method is the removal of that speculation.
“The benefit of Ted’s method is the removal of that speculation.” — Perhaps. Except, the method is also the only occasion for the speculation, so as a benefit that seems like pretty thin gruel. We need a better basis than that. But that’s beside the point. I’m not opposed to the method at all. I’m saying that DHers need to step up their game and cite scholarship. Anything can sound surprising if you don’t cite the scholars who made the point before you in a different way–and there’s always someone who did. This is just the fundamentals of scholarly work. DH is like a football team with a really flashy, high scoring offense, but a defense that often forgets how to tackle. You gotta wrap up!
That’s certainly a fair critique that can be applied to most of us. That said, it also reveals a fundamental issue with longitudinal distant reading: if we’re looking at 200 years of cross-sectional history at a distance, it would be implausible for one researcher or even a small team to have the complete expertise for analysis, data issues, and the gamut of historical moments under consideration. Maybe this is a case for a more crowd-based structure of scholarly development (CERN/LHC model) in DH?
Well, Scott, it sounds like our discussion has moved well beyond the occasion of this one essay, written under whatever constraints dictated its form and content. But I will say that, as a general rule not applied to any specific case, I don’t think your excuse holds up. What you describe as implausible is really just the process of preparing for comprehensive exams or, if you’re beyond the dissertation stage, preparing a literature review. As I said before, it’s just the fundamentals of scholarly work. You need to review what others have said. You need to explain where your findings support or challenge their conclusions. If other scholarship on your topic isn’t in your bibliography, you’ve got a real credibility problem. If you’re working in teams, somebody in the group needs to do the work. This isn’t a step you can skip, at least not if your goal is to make an actual contribution to an ongoing field of scholarly inquiry.
(yes, I agree that this has moved well beyond the scope of this blog post, but until either of us write a blog post it I suppose this’ll have to be the forum of discussion!) Michael, I’m sympathetic to your point, and I (as well, I think, as everyone else in this conversation) have called out others for not doing their due diligence in their review of related work. I think it’s vitally important, and it’s fairly easy to see where things go wrong when that diligence doesn’t take place (eg many of the culturomics claims).
With that said, I’m also not convinced that complete due diligence is plausible any longer when it comes to distant reading. The majority of the epistemological and rhetorical force of distant reading is its ability to blur the trees for the forest. That is a very different means to knowledge than traditional humanistic inquiry, which tends to work in the reverse. Claims about and questions of the forest of necessarily of a slightly different nature than those of the trees, and with the size of the ecosystem in every forest (I am so sorry for beating this metaphor beyond death), it’s not only unrealistic but possibly unnecessary for study of the whole to require a detailed knowledge of all constituent parts.
It’d be like a chemist needing to maintain a working knowledge of the sum of modern physics to make sure none of her chemical models disagree with the most cutting edge physical ones that underlie it: in theory, that’s the goal, but in practice, the chemists and the physicists realize they can’t each spend the time to get the equivalent of several phds worth of knowledge. Instead, they publish their research, release it to the world, and wait for their counterparts in other disciplines to poke holes in or improve the original models. Or like the Large Hadron Collider, where each publication has to go through several rounds of editing and reviewing, and occasionally hundreds of experts, before getting published.
Both cases, I think, are indicative of disciplines where the network sum of knowledge about a subject is no longer feasibly attainable within a human lifespan. Publication and authorship become more diffuse, and iterative publication, preprints, and collaboration become required in their search for consilient (or at least accurate) knowledge.
As some humanists shift toward more wide-angle approaches, the inability to exhaustively review and reference details of every constituent part seems inevitable. It’s no longer simply a matter of qualifying exams or lit reviews, but requires a shift in practice along with a shift in the epistemological claim-to-truth embedded in the single authorship expertise model that humanities is used to. What comes with it is a willingness to publish results that aren’t air-tight “all the way down” the knowledge chain to each constituent detail, but have some gaps that other people are more familiar with can then notice and amend.
In short: I agree with you that due diligence is necessary, but I also think several claims in the new methodology render that traditional humanistic depth unfeasible; but what it lacks in depth, it gains in breadth that was, until recently, similarly unfeasible. A balance needs to be drawn, but perhaps instead of putting that brunt of that balance on the authors of some research, we can distribute that balance among the original researchers and the readers in a publish-early-and-often model, with iterative development by contributing experts.
The only thing is, Scott, I’m a scholar of eighteenth- and nineteenth-century British literature. If I didn’t know the literature Michael is describing, I would actually be negligent. But I do know it quite thoroughly and just chose not to discuss it in detail. Watt seemed to me to do the job.
What a succinct reply to my long-winded message! That’s fair, though I still stand by the methodological point (even if it doesn’t require invoking in this case).
I teach eighteenth- and nineteenth- British literature, so I have no desire to pass the buck here to anyone else on the team. I’m thoroughly familiar with the secondary literature you describe. But I only cited Watt because Watt’s the person who has actually shaped my thinking on this issue, and because I chose only to spend one paragraph on the whole question of literary explanation. (Other people are of course free to write their own articles on that question, if they think these results need explaining.) The article also doesn’t claim that these are particularly surprising results; just that this is “a new piece of evidence.” It could be surprising or self-evident: I leave that up to readers. (I do agree that there’s quite a lot of consensus that the run-up to Austen involved advances in the management of third-person p.o.v.; that’s why I say “consensus,” and treat it as a matter of common knowledge.)
But fundamentally, Michael, the question you’re posing seems to me a question about the balance of attention I chose to give different disciplines in the article. It’s an article to appear in the Proceedings of the IEEE, and I chose to make it mostly about digital methods rather than mostly about literary history. I’ve already published a number of other articles that are mostly about literary history. But readers are welcome to critique the disciplinary balance in the article; I have no objection to that. The article could have included much more literary history, or more linguistics, or more library science (I brush over MARC records very quickly). Also, I could have used support vector machines instead of logistic regression, or conditional random fields instead of hidden Markov models. I think those are all valid critiques, and I expect to get other critiques not yet included in that list. I’m not going to respond to all of them, but it’s all fair. If I wanted my work not to be controversial, I wouldn’t trespass on so many disciplines at once!
Re: “next steps”: at this point I hope the question fans out in a whole lot of different directions. I’ve published the metadata for the workset, so other scholars can request this list of fiction volumes from HathiTrust or HTRC and pose their own literary questions about it.
I may pose some specific literary questions myself about fiction (e.g., I’m intrigued by those number words). But I’ve promised granting agencies to create genre metadata that other scholars can use, so a large part of my time has to be spent simply creating metadata for other genres (e.g., different kinds of poetry and drama), and doing it all in a more granular, page-level way, so other scholars know where they can get a list of pages that are really fiction or poetry rather than front matter or publishers’ ads. (In the case of poetry we’re going to have to take it down to the line level, because — as you know — 18c/Romantic-era poetry has a lot of prose footnotes!) I think that’s going to take at least another six months.
Sounds very interesting, very difficult, and potentially very valuable. I look forward to hearing more about it soon.
One general invitation about gender and point of view. If you’re not surprised that women used first-person narration less than men in the period 1700-1899, please say precisely why you’re not surprised.
I’d like to understand the reason for this, and I don’t think I have a compelling explanation for it yet. But if this is a result you expected, presumably there’s a specific reason why you expected it. Please share that reason: I’d like to gather a full range of hypotheses.
In a really casual, unexamined way it didn’t surprise me — because I assume men are full of themselves and likely to say “I” a lot. But it turns out that in some genres of contemporary writing women are actually more likely to use the first-person singular: see Shlomo Argamon, Moshe Koppel, Jonathan Fine, and Anat Rachel Shimoni, “Gender, Genre, and Writing Style in Formal Written Texts,” Text, 23(3), August 2003.
Some of my literary-historical priors would have pointed in the other direction as well. For instance, going on Nancy Armstrong’s thesis in Desire and Domestic Fiction, I believed that modern fictive subjectivity was expressed earliest and most strongly in works of domestic fiction (many of them by women). “The modern individual,” famously, “was a woman.” And, since Armstrong discusses e.g. Samuel Richardson, I might casually have associated “domestic subjectivity” with first-person narration. But apparently that association turns out not to hold. In both collections I’ve examined, the language of domesticity is associated with third-person narration, which is also favored by women writers.
I’m willing to believe that this association of gender and point of view was predictable. But if so, I want to understand why exactly we should have predicted it.
Well, we can talk about this more when we meet. As I’ve already pointed out, the category “first person novel from 1700-1899” is not a valid category. It’s like you’re lumping dolphins with fish and then asking me to explain the differences you’ve noticed between girl fish and boy fish. I have nothing else to say about those charts.
What felt obvious to me were your general comments — why do DHers think their charts are more important than their conclusions?– about the association between domesticity, femininity, and third-person narration in novels. I won’t copy and paste it here, but somewhere you say something to the effect of “there might be a gender dimension to this, but that’s speculative, we can’t be sure.” On that point I’d just say you should allow your thinking on the topic to be shaped by scholars other than Watt, then refer you back to Armstrong (whom you cite above but whose conclusions you admit you haven’t synthesized with your own thinking) and invite you to re-read her, along with pretty much anyone who’s worked on the history of the domestic novel in the last thirty years, in particular on its shift from epistolary to third-person form. I mean, seriously, c’mon. This is well-traveled terrain. You’re not discovering life on Mars, here. This might be “new evidence,” as you say, but your phrasing in both the blog and the article misrepresents the field of scholarship to which you are contributing. You said that your thinking hasn’t been shaped by any scholarship on the topic since Watt. I’m pointing out that this shows in the work. That’s what’s happening here.
Now, of course, you’re an expert in the field and more experienced than I am. All the more reason why you are responsible, unlike Scott perhaps, for connecting these dots and not leaving them to your readers to connect. (It’s not my job to tell you how your results relate to the conclusions of our peers!) I’ll give Scott a pass on not citing his sources, because all of us draw from a deep social well of common knowledge, and reconstructing the textual history of that well is difficult work, which might be too much to expect of a DH graduate student trying to master two or three disciplines at once. [Editorial note from Ted Underwood: Scott Weingart is not accused here of failure to cite any source. He was making a general, hypothetical argument about appropriate levels of detail in distant reading.] However, that’s also why I do say it’s negligent for established scholars to choose not to engage the work of their peers, especially when communicating outside one’s home discipline. You’ve gotta represent! (And, by the way, this can be done in a single, well-crafted paragraph. Bill Clinton can explain the global economy in five minutes. The article genre is no excuse!)
Anyway, like I said, I think this is all very promising work. I’m not opposed to the methodology, I’m Team Underwood. I think your book is great, even brilliant at some points. My own work on historical simulation is, if anything, more deeply problematic than your data-driven approach. I don’t want anything I’ve said here to be interpreted as hostile to the field of DH or humanities computing. But at some point soon the “promising” moniker is going to seem as ill-fitting as a thrift-shop suit, and it’s going to be expected that the conclusions we draw be as compelling as the charts we draw.
Fair enough. I’m not going to return to the questions we discussed earlier (i.e., whether I have an obligation to “represent” — nicely put), because I’ve already responded to that, and fully understand that many literary scholars won’t like my answer. And I certainly don’t want to spend any time defending “digital humanities” (nowhere mentioned in the article, you’ll notice).
But if I’m understanding your answer to my question, “why is the association of gender with point of view predictable?” — the central point is that, for you, the category of “first-person narration” is too internally diverse to be treated as a coherent historical category. So when it comes to the apparent association with gender, it’s not so much that this is an expected association; rather, it’s a meaningless association — or at least, an association that hasn’t yet been defined precisely enough to require an explanation. That’s a coherent perspective, and it’s one I hadn’t heard yet. Thanks — and thanks for the kind words about the book!
Yes, that’s right. I would want to see the genre definitions you’re working on to be a little finer before committing myself to an explanation. That said, the gender bias is also prevalent in the canonical 18c literature: early novels of amatory intrigue and later novels of domestic life tend to be in third-person. The traditional male canon tends to be in first-person or epistolary form. Obviously this isn’t a hard and fast rule, but I’d have been surprised if the results came out differently. If you just glance over the works of Behn, Manley, Haywood, Burney and Austen, on the one side, and Defoe, Richardson, Fielding, Sterne, Smollett, on the other, the bias seems clear. Off hand, I don’t know the 19c canon well enough to say.
That rings true to me as well.
Of course, the boundary we’re walking here between “unsurprising” and “incoherent” is going to be a constitutive dilemma with distant reading. I think the notion that distant reading is going to help just by uncovering unread texts has been slightly oversold (though it becomes truer and truer as you go forward in time.)
But in a period like the 18c, I think the leverage of distant reading (if any — and I’m genuinely not sure it has much) is going to depend almost entirely on forcing us to make generalizations we’re uncomfortable with. If we consider genres and authors individually, they’re going to confirm what we already know. As we back up … we’re going to see patterns that are either “incoherent assemblages of distinct phenomena, each already well explained on its own” or “unexplained questions,” depending on your perspective. That’s more or less what I’m trying to say in the last chapter of the book.
Ted, thank you for that editorial note. I was just about to alert you to this. I would like to publicly apologize to Scott for the confusion. I meant to say in general that I was very sympathetic to the concerns Scott raised, and that people evaluating the scholarly work of digital humanists, junior digital humanists in particular, should recognize that a full literature review of all pertinent topics will not always be possible, for the reasons Scott said. Thank you for clarifying, and allowing me to do the same.
I am going to echo Michael’s comments but take them in a slightly different direction.
I don’t see any discussion in the paper of the meaning of “point of view” as that’s described throughout literary studies scholarship. Instead, that term is presented as an obvious given. Yet what the paper picks out is not, as far as I can tell, literary point of view. It picks out the subject and object positions in sentences. These are not the same thing. Among other things, from what I’ve read, you have not tried to distinguish dialogue from other forms of narration. So a novel with a lot of dialogue, in which first-person pronouns occur a lot, would seem to get registered as mostly first-person, but that doesn’t necessarily correspond to “first-person narration” as a literary critic would define it. But dialogue is a special case; I suspect it would be easy to find examples of novels with first-person narration (in literary terms) that have many more third-person sentences than first-person, and vice versa.
In fact, the more I think about it, the less clear I am about what the relationship between pronoun frequency and type of narration is or would be in any general sense. Given that this paper will be understood in part as a contribution to literary criticism, it seems important to be very clear about this distinction. Further, it obscures a variety of techniques that are understood as not to be first-person in literary terms. A novel which has multiple first-person narrators, as in some of the epistolary novels Michael mentions, would be classes as “first person,” but are typically thought of in literary terms as some variety of third-person omniscient narration due to the (sometimes) silent “organizer” of the letters or documents. Further, I’m really unclear about how one would algorithmically determine point of view in the sense literary criticism typically uses that term.
Some of the things you’re saying here are true, David, and some of them are based on a misunderstanding of the way algorithmic classification works. E.g., the classification algorithm isn’t about subject and object positions, nor is it just about pronouns.
I can’t fully explain the principles of machine learning in a blog thread. But the key is this: I haven’t designed a specific clever recipe to identify first-person narration. I identify novels that I believe are written in the first person, and train a model to recognize those novels. It doesn’t restrict itself to pronouns: for instance, if dialogue were a major complication, some learning algorithms could identify speech cues like “said” as a necessary counterweight. (That doesn’t actually turn out to be necessary here.) Then we present the model with novels it hasn’t seen, and ask “How good a job does it actually do classifying them?”
Your worries about dialogue are, in effect, addressed automatically when we test the model. If there’s a problem, we’ll know, because the model will fail to correctly identify the new examples it’s presented. But in fact our model does very well. Now, “very well” in the algorithmic world is, e.g., 96% (see the article for details of the metric). I realize humanists are accustomed to lower error tolerances; if you find 4% error unacceptable, you probably won’t want to use algorithmic strategies.
Some of your other questions require a different sort of answer, because they’re questions about the categories human investigators have used to train and test the models. E.g., should we distinguish epistolary narration from first person? I haven’t tried that yet, but it would clearly be useful, and I suspect it won’t be hard. Epistolary address leaves its own lexical clues in a text: I doubt it’s much harder to identify than drama. We should be able to break epistolary narration out as a separate category and see how that changes the picture.
However, there’s no doubt that point of view also involves a rich range of phenomena that an algorithm will find hard to register. Multiple narrators, degrees of distance, focalization, etc. The first person/third person spectrum I’m offering is a deliberate simplification — a “model.” No model reproduces every detail of reality. The question to ask is, Is it useful? Do we learn anything interesting from it? People are welcome to their own opinions on that. I think this model has already shown me several things I didn’t know before, and has turned up clues that point toward even more interesting questions. It sounds like you believe the model will be too simple to be useful. That’s okay, and I’m sure you won’t be alone. But I’m not going to spend a great deal of time trying to persuade skeptics at this point — I’d rather check out these clues, and see where they lead.