by Ted Underwood and David Bamman
Last year, we wrote a blog post that posed questions about the differentiation of gendered roles in fiction. In doing that, we skipped over a more obvious question: how equally (or unequally) do stories distribute their attention between men and women?
This year, we’re returning to that simple question, with a richer dataset (supported by ongoing work at HathiTrust Research Center). The full story will come out in an article, but we’d like to share a few big-picture points in advance.
To start with, why have we framed this as a question about “women” and “men”? Gender isn’t a binary phenomenon. But we aren’t inquiring about the truth of gender identity here — just about gross inequalities that have separated conventional public roles. English-language fiction does typically divide characters by calling them “he” or “she,” and that division is a good place to start posing questions.
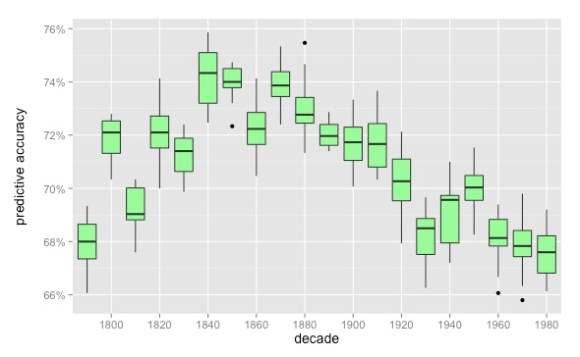
We could measure underrepresentation by counting people, but then we’d have to decide how much weight to give minor characters. A simpler approach is just to ask how many words are used to describe fictional men or women, respectively. BookNLP gave us a way to answer that question; it uses names and honorifics to infer a character’s gender, and then traces grammatical dependencies to identify adjectives that modify a character, nouns she possesses, or verbs she governs. After swinging BookNLP through 93,708 English-language volumes identified as fiction from the HathiTrust Digital Library, we can estimate the percentage of words used in characterization that are used to describe women. (To simplify the task of reading this illustration, we have left out characters coded as “other” or unknown,” so a year with equal representation of men and women would be located on the 50% line.). To help quantify our uncertainty, we present each measurement by year along with a 95% confidence interval calculated using the bootstrap; our uncertainty decreases over time, largely as a function of an increasing number of books being published.
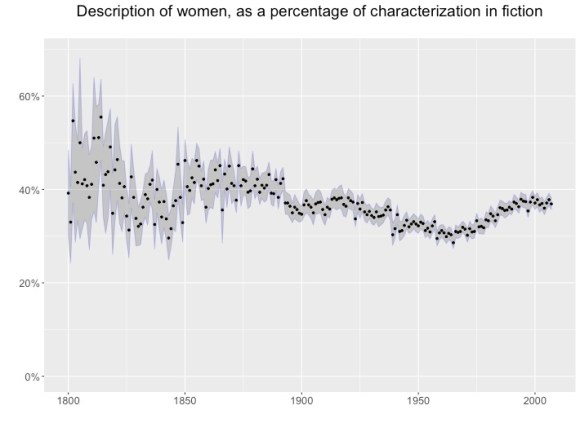
There is a clear decline from the nineteenth century (when women generally take up 40% or more of the “character space” in fiction) to the 1950s and 60s, when their prominence hovers around a low of 30%. A correction, beginning in the 1970s, almost restores fiction to its nineteenth-century state. (One way of thinking about this: second-wave feminism was a desperately-needed rescue operation.)
The fluctuation is not enormous, but also not trivial: women lose roughly a fourth of the space on the page they had possessed in the nineteenth century. Nor is this something we already knew. It might be a mistake to call this pattern a “surprise”: it’s not as if everyone had clearly-formed expectations about “space on the page.” But when we do pose the question, and ask scholars what they expect to see before revealing this evidence, several people have predicted a series of advances toward equality that correspond to e.g. the suffrage movement and World War II, separated by partial retreats. Instead we see a fairly steady decline from 1860 to 1970, with no overall advance toward equality.
What’s the explanation? Our methods do have blind spots. For instance, we aren’t usually able to infer gender for first-person protagonists, so they are left out here. And our inferences about other characters have a known level of error. But after cross-checking the evidence, we don’t believe the level of error is large enough to explain away this pattern (see our github repo for fuller discussion). It is of course possible that our sample of fiction is skewed. For instance, a sample of 93,708 volumes will include a lot of obscure works and works in translation. What if we focus on slightly more prominent works? We have posed that question by comparing our Hathi sample to a smaller (10,000-volume) sample drawn from the Chicago Text Lab, which emphasizes relatively prominent American works, and filters out works in translation.
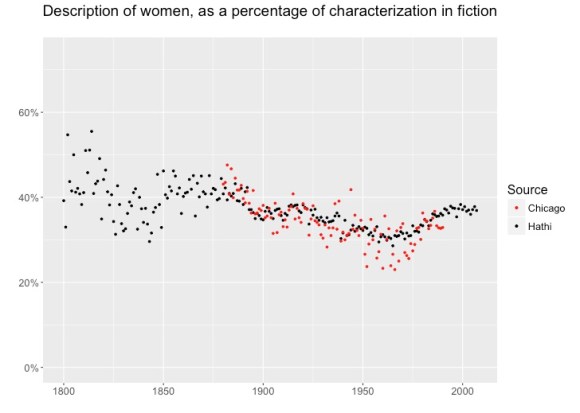
As you can see, the broad outlines of the trend don’t change. If anything, the decline from 1860 to 1970 is slightly more marked in the Chicago corpus (perhaps because it does a better job of filtering out reprints, which tend to muffle change). This doesn’t prove that we will see the same pattern in every sample. There are many ways to sample the history of fiction! Some scholars will want to know about paperbacks that tend to be underrepresented in university libraries; others will only be interested in a short list of hypercanonical authors. We can’t exhaust all possible modes of sampling, but we can say at least that this trend is not an artefact of a single sampling strategy. Nor is it an artefact of our choice to represent characters by counting words syntactically associated with them: we see the same pattern of decline to different degrees when measuring the amount of dialogue spoken by men and women, and in simply counting the number of characters as well.
So what does explain the declining representation of women? We don’t yet know. But the trend seems too complex to dismiss with a single explanation. For instance, it can be partly — but only partly — explained by a decline in the proportion of fiction writers who were women.
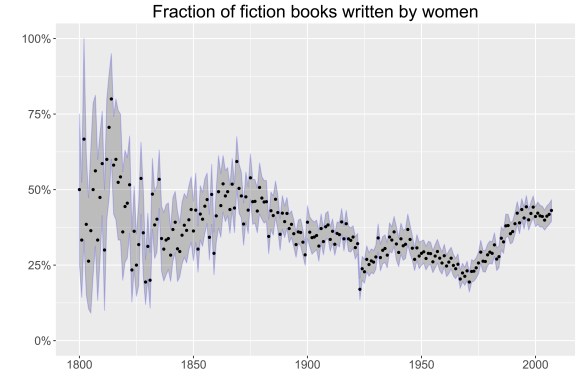
Take specific dots with a grain of salt; there are sources of error here, especially because the wall of copyright at 1923 may change digitization practices or throw off our own data pipeline. (Note the outlier right at 1923.) But the general pattern above is echoed also in the Chicago sample of American fiction, so we feel confident that there was really a decline in the fraction of fiction writers who were women. As far as we know, Chris Forster was the first person to gather broad quantitative evidence of this decline. But many scholars have grasped pieces of the story: for instance, Anne E. Boyd takes The Atlantic around 1890 as a case study of a process whereby the professionalization and canonization of American fiction tended to push out women who had previously been prominent. [See also Tuchman and Fortin 1989 in references below.]
But this is not necessarily a story about the marginalization of women writers in general. (On the contrary, the prominence of women rose throughout this period in several nonfiction genres.) The decline was specific to fiction — either because the intellectual opportunities open to women were expanding beyond belles lettres, or because the rising prestige of fiction attracted a growing number of men.
Men are overrepresented in books by men, so a decline in the number of women novelists will also tend to reduce the number of characters who are women. But that doesn’t completely explain the marginalization of feminine characters from 1860 to 1970. For instance, we can also divide authors by gender, and look at shifting patterns of attention within works by women or by men.
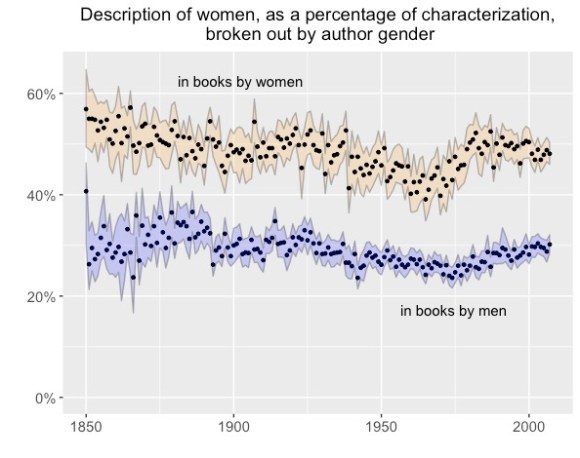
There are several interesting details here. The inequality of attention in books by men is depressingly durable (men rarely give more than 30% of their attention to fictional women). But it’s also interesting that the fluctuations we saw earlier remain visible even when works are divided by author gender: both trend lines above show a slight decline in the space allotted to women, from 1860 to 1970. In other words, it’s not just that there were fewer works of fiction written by women; even inside books written by women, feminine characters were occupying slightly less space on the page.
Why? The rise of genres devoted to “action” and “adventure” might play a role, although we haven’t found clear evidence yet that it makes a difference. (Genre boundaries are too blurry for the question to be answered easily.) Or fiction might have been masculinized in some broader sense, less tied to specific genre categories (see Suzanne Clark, for instance, on modernism as masculinization.)
But listing possible explanations is the easy part. Figuring out which are true — and to what extent — will be harder.
We will continue to explore these questions, in collaboration with grad students, but we also want to draw other scholars’ attention to resources that can support this kind of inquiry (and invite readers to share useful secondary sources in the comments).
HathiTrust Research Center’s Extracted Features Dataset doesn’t permit the syntactic parsing performed by BookNLP, but even authors’ names and the raw frequencies of gendered pronouns can tell you a lot. Working just with that dataset, Chris Forster was able to catch significant patterns involving gender.
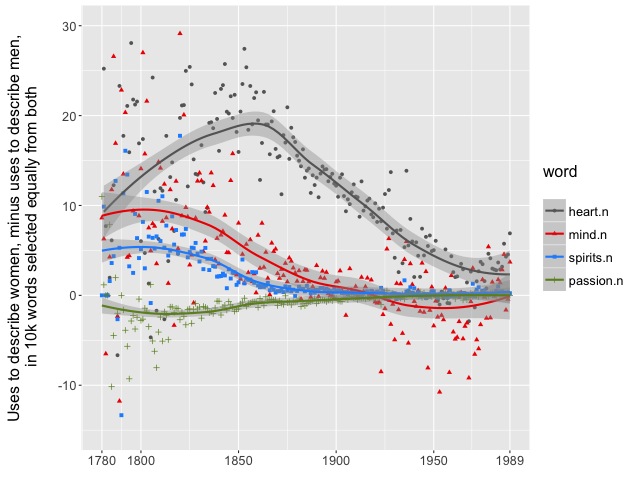
When we publish our article, we will also share data produced by BookNLP about specific characters across a collection of 93,708 books. HTRC is also building a “Data Capsule” that will allow other scholars to produce similar data themselves. In the meantime, in collaboration with Nikolaus N. Parulian, we have produced an interactive visualization that allows you to explore changes in the gendering of words used in characterization. (Compare, for instance, “grin” to “smile,” or “house” to “room.”) We have also made available the metadata and yearly summaries behind the visualization.
Acknowledgments. The work described here has been supported by NovelTM, funded by the Canadian Social Sciences and Humanities Research Council, and by the WCSA+DC grant at HathiTrust Research Center, funded by the Andrew W. Mellon Foundation. We thank Hoyt Long, Teddy Roland, and Richard Jean So for permission to use the Chicago Novel Corpus. The project often relied on GenderID.py, by Bridget Baird and Cameron Blevins (2014). Boris Capitanu helped parallelize BookNLP across hundreds of thousands of volumes. Attendees at the 2016 NovelTM meeting, and Justine Murison in Illinois, provided valuable advice about literary history.
References.
Boyd, Anne E. “‘What, Has She Got into the Atlantic?’ Women Writers, The Atlantic Monthly, and the Formation of the American Canon,” American Studies 39.3 (1998): 5-36.
Clark, Suzanne. Sentimental Modernism: Women Writers and the Revolution of the Word (Indianapolis: Indiana University Press, 1992).
Forster, Chris. “A Walk Through the Metadata: Gender in the HathiTrust Dataset.” September 8, 2015. http://cforster.com/2015/09/gender-in-hathitrust-dataset/
Tuchman, Gaye, with Nina E. Fortin. Edging Women Out: Victorian Novelists, Publishers, and Social Change. New Haven: Yale University Press, 1989.