
Perhaps not the most inspiring title. But the words are carefully chosen.
Basically, I’m sharing the code I use to correct OCR in my own research. I’ve shared parts of this before, but this is the first time I’ve made any effort to package it so that it will run on other people’s machines. If you’ve got Python 3.x, you should be able to clone this github repository, run OCRnormalizer.py, and point it at a folder of files you want corrected. The script is designed to handle data structures from HathiTrust, so (for instance) if you have zip files contained in a pairtree structure, it will recursively walk the directories to identify all zip files, concatenate pages, and write a file with the suffix “.clean.txt” in the same folder where each zip file lives. But it can also work on files from another source. If you point it at a flat folder of generic text files, it will correct those.
I’m calling this an OCR “normalizer” rather than “corrector” because it’s designed to accomplish very specific goals.
In my research, I’m mainly concerned with the kinds of errors that become problems for diachronic text mining. The algorithms I use can handle a pretty high level of error as long as those errors are distributed in a more-or-less random way. If a word is mistranscribed randomly in 200 different ways, each of those errors may be rare enough to drop out of the analysis. You don’t necessarily have to catch them all.
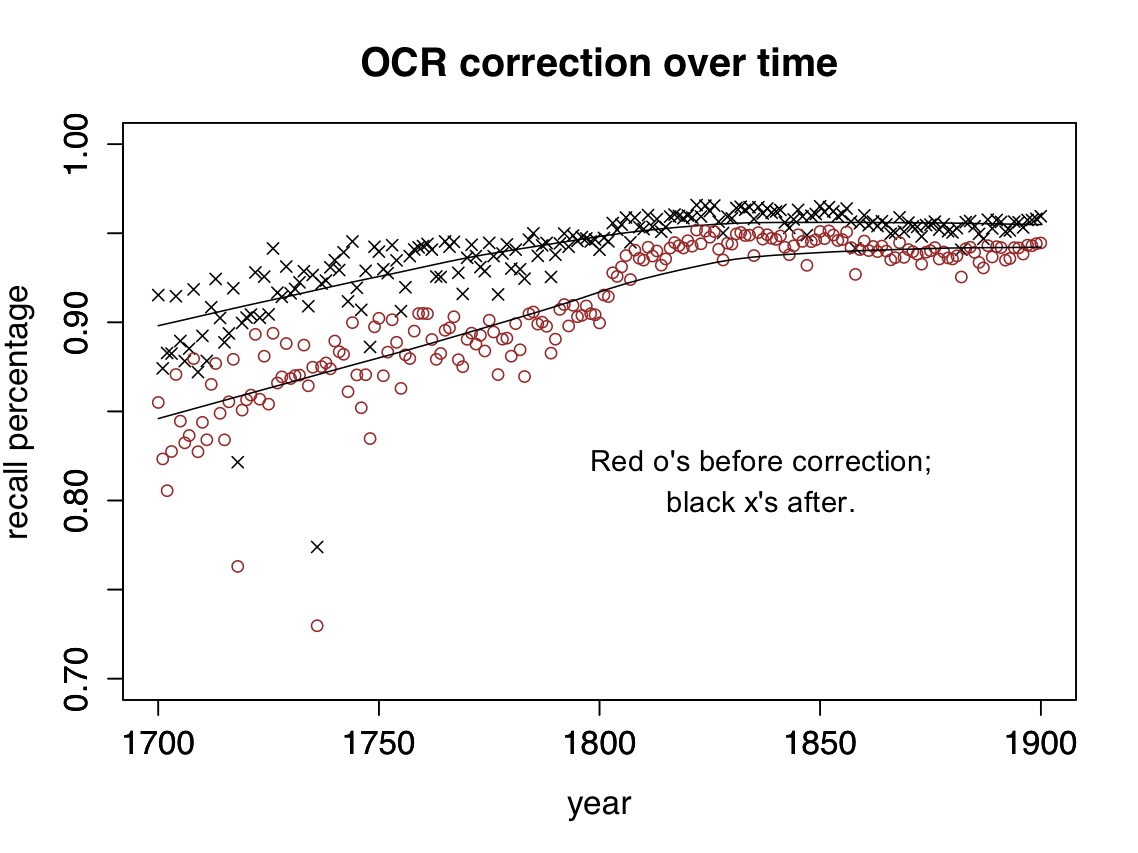
The range of possible OCR errors is close to infinite. It would be impossible to catch them all, and as you can see above, my script doesn’t. For a lot of nineteenth-century texts it produces a pretty small improvement. But it does normalize major variations (like long S) that would otherwise create significant distortions. (In cases like fame/same where a word could be either an OCR error or a real word, it uses the words on either side to disambiguate.)
Moreover, certain things that aren’t “errors” can be just as problematic for diachronic analysis. E.g., it’s a problem that “today” is sometimes written “to day” and sometimes “to-day,” and it’s a problem that eighteenth-century verbs get “condens’d.” A script designed to correct OCR might leave these variants unaltered, but in order to make meaningful diachronic comparisons, I have to produce a corpus where variations of spelling and word division are normalized.
The rulesets contained in the repo standardize (roughly) to modern British practice. Some of the rules about variant spellings were originally drawn, in part, from rules associated with the Wordhoard project, and the some of the rules for OCR correction were developed in collaboration with Loretta Auvil. Subfolders of the repo contain scripts I used to develop new rules.
I’ve called this release version 0.1 because it’s very rough. You can write Python in a disciplined, object-oriented way … but I, um, tend not to. This code has grown by accretion, and I’m sure there are bugs. More importantly, as noted above, this isn’t a generic “corrector” but a script that normalizes in order to permit diachronic comparison. It won’t meet everyone’s needs. But there may be a few projects out there that would find it useful as a resource — if so, feel free to fork it and alter it to fit your project!
