
Perhaps not the most inspiring title. But the words are carefully chosen.
Basically, I’m sharing the code I use to correct OCR in my own research. I’ve shared parts of this before, but this is the first time I’ve made any effort to package it so that it will run on other people’s machines. If you’ve got Python 3.x, you should be able to clone this github repository, run OCRnormalizer.py, and point it at a folder of files you want corrected. The script is designed to handle data structures from HathiTrust, so (for instance) if you have zip files contained in a pairtree structure, it will recursively walk the directories to identify all zip files, concatenate pages, and write a file with the suffix “.clean.txt” in the same folder where each zip file lives. But it can also work on files from another source. If you point it at a flat folder of generic text files, it will correct those.
I’m calling this an OCR “normalizer” rather than “corrector” because it’s designed to accomplish very specific goals.
In my research, I’m mainly concerned with the kinds of errors that become problems for diachronic text mining. The algorithms I use can handle a pretty high level of error as long as those errors are distributed in a more-or-less random way. If a word is mistranscribed randomly in 200 different ways, each of those errors may be rare enough to drop out of the analysis. You don’t necessarily have to catch them all.
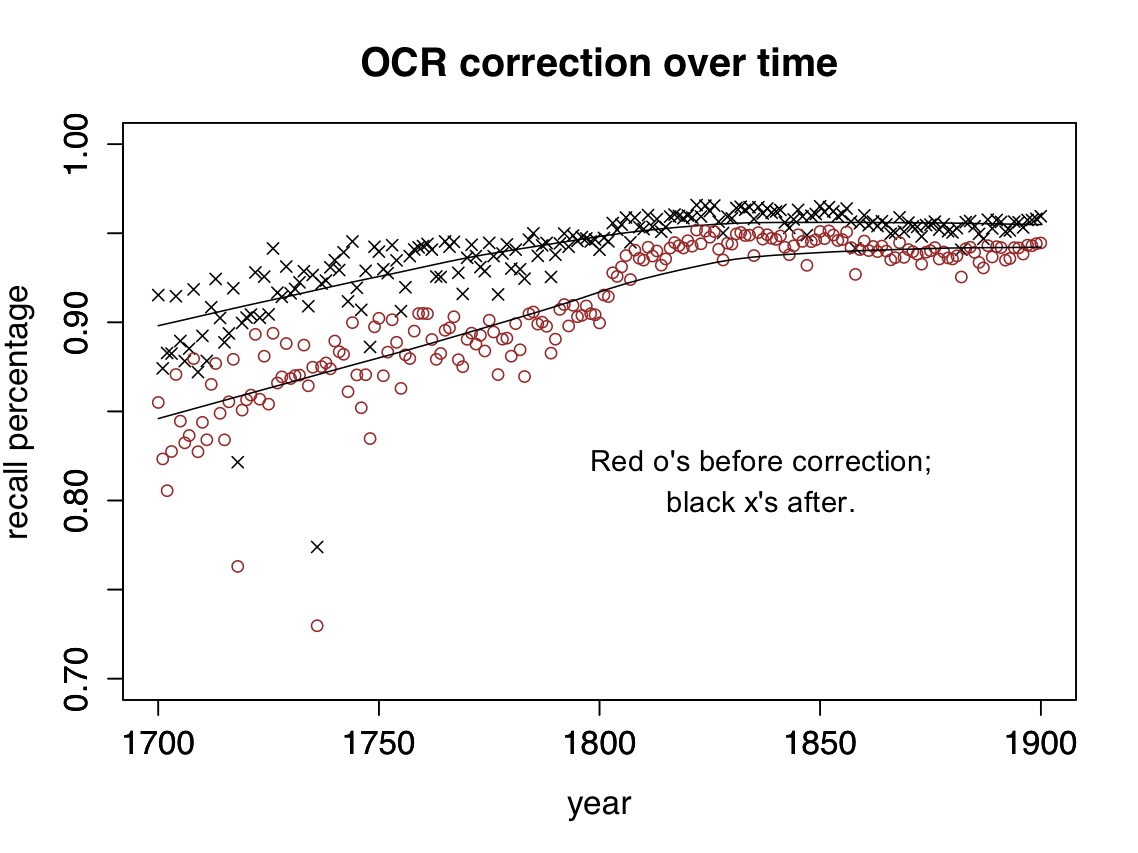
The range of possible OCR errors is close to infinite. It would be impossible to catch them all, and as you can see above, my script doesn’t. For a lot of nineteenth-century texts it produces a pretty small improvement. But it does normalize major variations (like long S) that would otherwise create significant distortions. (In cases like fame/same where a word could be either an OCR error or a real word, it uses the words on either side to disambiguate.)
Moreover, certain things that aren’t “errors” can be just as problematic for diachronic analysis. E.g., it’s a problem that “today” is sometimes written “to day” and sometimes “to-day,” and it’s a problem that eighteenth-century verbs get “condens’d.” A script designed to correct OCR might leave these variants unaltered, but in order to make meaningful diachronic comparisons, I have to produce a corpus where variations of spelling and word division are normalized.
The rulesets contained in the repo standardize (roughly) to modern British practice. Some of the rules about variant spellings were originally drawn, in part, from rules associated with the Wordhoard project, and the some of the rules for OCR correction were developed in collaboration with Loretta Auvil. Subfolders of the repo contain scripts I used to develop new rules.
I’ve called this release version 0.1 because it’s very rough. You can write Python in a disciplined, object-oriented way … but I, um, tend not to. This code has grown by accretion, and I’m sure there are bugs. More importantly, as noted above, this isn’t a generic “corrector” but a script that normalizes in order to permit diachronic comparison. It won’t meet everyone’s needs. But there may be a few projects out there that would find it useful as a resource — if so, feel free to fork it and alter it to fit your project!

8 replies on “A half-decent OCR normalizer for English texts after 1700.”
[…] Read the full post here. […]
Dear Ted,
Thank you for this blog! It is with great pleasure that I learn I am not the sole person in the world to attempt to clean up or normalize collections of digitized texts.
The main paper describing my efforts is here, in Open Access: http://link.springer.com/article/10.1007%2Fs10032-010-0133-5#page-1
The problem of evaluating one’s attempts has fascinated (and frustrated at times) me for years (cf. http://www.lrec-conf.org/proceedings/lrec2008/summaries/477.html ).
I do think you have chosen the words in your title very carefully. But for me to properly appraise them I have to ask you to elucidate a few points about the graph you provide.
The caption to your graph states “The percentage of tokens in the HathiTrust corpus that are recognized as words”.
What exactly does each data point in the graph represent? Is it the cumulative result of your system’s achievements on perhaps one book published in the particular year? Or is this on all the Hathi books in English? I have recently had occasion to take a closer look at the Hathi collections and a lot of books seemed not accessible.
Also, how do you determine a word is correct? Is this in reference to a validated lexicon? Is this lexicon perhaps available? Sure what is correct or not depends on the coverage of the lexicon one uses?
Or do you actually have OCR ground truths or OCR post-correction gold standards for so many books? I do not quite see how else one can evaluate whether a word in context (‘it uses the words on either side to disambiguate’) was properly corrected. Would these ground truths then be available to others for research?
Thank you for sharing your tool! I will definitely try it.
Looking forward for any additional information you can give!
Best regards,
Martin Reynaert
Postdoc Researcher
TiCC – Tilburg University
CSLT – Radboud University
The Netherlands
Hi Martin — Thanks for those links. I’m collaborating with a couple of other people on the problem of OCR evaluation, and these leads will be very helpful.
The graph is based on 470,000 volumes from HathiTrust 1700-1899; it’s the majority of English non-serial volumes in that period. (Illinois has signed an agreement with HathiTrust, which gives me access to public-domain works for research purposes.) So each data point is the average percentage of tokens recognized as words in a given year.
It’s a pretty big corpus, but I haven’t tried to do a thorough, systematic, evaluation of accuracy yet. As you rightly note in your paper, evaluation requires attention to both “recall” and “precision,” and I’m not attempting that yet. The graph above is just “the number of tokens recognized as words,” and you’re absolutely right that this figure will depend on dictionary coverage. I use a multi-lingual dictionary, but no dictionary includes all possible languages, all possible proper nouns, etc. Moreover, by its very nature, this isn’t a metric that can be used to evaluate contextual spellchecking of pairs like “fame/same.” To evaluate that part of the workflow, you’re right, I would need to use manually-entered ground truth (e.g. the TCP-ECCO corpus.)
In short, I’m not making strong claims about accuracy here. The word “half-decent” in the title is very deliberately chosen. This is not a publication: it’s a patch that I’ve created, largely on my own time, because I needed *some* patch for this problem. In research on the corrected corpus, I have found in practice that it lacks the large obvious distortions that previously made diachronic analysis impossible. But I haven’t made an effort to rigorously quantify the level of error that remains. I think some of the people I’m collaborating with will produce quantitative accuracy metrics fairly soon. But for me the key is this: even if I had a figure based on ground truth (e.g. “90% precision”), it wouldn’t tell me what I actually need to know — which is whether the errors (and accurate variants) that remain are distributed in a way that becomes problematic for a particular historical problem or kind of algorithmic analysis. That question is the decisive one for me, and it’s still going to require case-by-case attention.
A great blog post and thanks for sharing the code.
There is definitely a need for more research on quantitative accuracy metrics for OCRed text, especially when it comes to using it for any kind of text processing. So I’ll be looking forward to see more work in this area.
In your comment above you mention that each data point represents the average percentage of tokens recognised as a word in a given year. You might just have used the wrong expression as you can’t average percentage unless the document lengths are the same. You need to compute one percentage of words found in the dictionary for all documents in the same year. The reason being is that averaging percentages will skew the results if the length of documents varies much across years.
For example, if you have three documents for year 1: with 50/100, 300/600 and 500/1500 words in the dictionary. The average percentage would be 44.4444444. The percentage across all documents is 850/2200*100=38.6363636363636. You have another three documents for year 2: with 400/800, 600/1200 and 500/1500 words in the dictionary. The first 2 documents are longer but have the same percentage of words in the dictionary as the first two documents in year 1. The average percentage is still 44.4444444. However, the recall percentage across all documents is 1500/3500*100=42.8571428571429.
I’d also be really interested to know what’s going on for the outliers in your graph.
Beatrice Alex
School of Informatics, University of Edinburgh
Yep — you’re quite correct that there’s a difference. The graph above is based on calculations that don’t weight documents by length; for simplicity’s sake, I’ve treated each document as an equivalent data point.
But I’m really not aiming to evaluate accuracy with any finesse here: the point of the illustration is purely to show the gross difference between the way correction works in the 18th century and the way it works in the 19th century. The end of “long s” is a very significant change that dwarfs a lot of subtler issues — that’s all the illustration is meant to reveal.
[…] Possibly helpful for cleaning 18th C OCR, @ihoffman. https://tedunderwood.com/2013/12/10/a-half-decent-ocr-normalizer-for-english-texts-after-1700/ […]
Are you still maintaining this? Have just started using it and found a couple of bugs.
John
[…] https://tedunderwood.com/2013/12/10/a-half-decent-ocr-normalizer-for-english-texts-after-1700/ […]