Although distant reading always involves work, some parts of the task have an immediate reward. Solving these problems gives you an article with clear disciplinary significance, or at least a sparkly website. You could call these problems the glamorous ones.
Other problems are just nasty. They require a lot of detail work that never sees the light of day, and when you’re done, all you have is an intermediate product that makes further inquiry possible. The research community as a whole benefits, but you don’t get your picture taken with the Mayor. At most, if you’re lucky, you get a couple of data or code citations.
Perspectives vary, of course: problems that look nasty to literary scholars might be glamorous in information science. But untenured scholars understandably want problems that count as glamorous in their home disciplines. Even post-tenure, I only do thankless work in the dead of night if I can get help and/or grant funding, because I’m not a masked billionaire vigilante. For the last several years, I’ve been collaborating with HathiTrust Research Center to create a public dataset of word counts for English-language literature 1800-2000, and we’re only halfway done with that slightly nasty task.
So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
1: Proving how much ngram information is safe to share.
In order to do research beyond the wall of copyright, we often need to share derived data about books, instead of the original text. The question is, how much information can you share, legally, before it becomes possible to reconstruct the book?
There’s already some good research on this problem, and it might be 90% solved. But it’s a Rasputin-like problem that will keep coming back to life if you only kill it 90% dead. We need someone to bury it, which probably means, someone with real CS training, who can produce a specific, confident answer you could show a lawyer. In particular, there are tricky questions about interactions between different levels of aggregation. Suppose (for instance) you had page-level counts of single words, plus volume-level counts of trigrams. How much of a book, at most, could you reconstruct, given real-life variations in book length and page length?
2: Date-of-first-publication metadata.
We’re beginning to assemble large literary collections. But some of them include a lot of reprints, published decades or centuries after the first edition. That’s not necessarily a bad thing, but we will probably also want datasets that are deduplicated, or limited to first editions.
The beautiful, general solution to this problem probably requires linked data, and FRBR protocols, and a great deal of discussion. But see xkcd on solutions to “general problems.”
The solution Gotham City needs right now is probably more like a list of 50,000 titles, associated with dates of first publication.
This may be the next nasty problem I tackle. I suspect it would benefit from a tiered solution, where you produce a small amount of hand-checked data, plus a large amount of scraped or algorithmically-guessed data with a lower level of confidence.
3: A half-decent eighteenth century collection.
OCR problems before 1800 are real, but the universe of English literature before 1800 is also small enough that it’s possible to imagine creating a reasonable sample of hand-corrected texts. The eMOP crowd-sourcing initiative may be the solution here. Or a very modest supplement to ECCO-TCP might be sufficient. I don’t know; I understand nineteenth-century digital collections much better.
***
A post like this one may seem to be encouraging people, generally, to tackle more nasty problems, but that’s not what I intend. Actually, I think scholars who work with computers tend to have a temperament that makes us all too willing to work on unglamorous infrastructure & markup problems, in the faith that they will eventually produce a general solution useful to everyone.
Fields that aren’t yet securely central to a discipline sometimes need to emphasize shorter-term thinking. But maybe distant reading is getting secure enough that a few of us can afford to do vigilante work on the side. Or maybe there are computer scientists out there who just need to see a bat signal.
Feel free to suggest more nasty problems in the comments.
Literary critics have been having a speculative conversation about close and distant reading. It might be premature to call it a debate.
A “debate” is normally a situation where people are free to choose between two paths. “Should I believe Habermas, or Foucault? I’m listening; I could go either way.” Conversation about distant reading is different, first, because there’s not much need to make a choice. Have any critics stopped reading closely? A close reading of The Bourgeois suggests that Franco Moretti hasn’t.
More importantly, this isn’t a debate yet because most of the people involved aren’t free to explore both paths. So far only a tiny number of scholars have actually tried distant reading, and it’s easy to see why. You can wake up tomorrow and try a Foucauldian reading of Frankenstein, but you can’t wake up and trace patterns of change in a thousand novels. In either case, you may need to learn new methods, but in the “distant” case, it can also take years to assemble a collection of texts.
A dataset for distant reading
To reduce barriers to entry, I’ve collaborated with HathiTrust Research Center to create an easier place to start with English-language literature. It’s aimed at scholars studying long-nineteenth-century (1750-1922) fiction and poetry, but it will gradually expand into the twentieth century. This post describes the humanistic uses of the dataset; if you want technical information, there’s more on the page where the data actually lives.
HathiTrust contains more than a million volumes in English between 1700 and 1922. Contractual agreements make it hard to share the texts themselves in bulk, but many of the questions that can be posed “at a distance” can be posed just as well using simpler representations of the texts — for instance, by counting the words they contain. To support this project, HathiTrust Research Center has extracted page-level word counts for 4.8 million volumes; scholars who are interested in the highest level of detail should go directly to their data.
However, many literary scholars are mainly concerned with books in a particular genre — they limit their inquiries, say, to “poetry” or “prose fiction.” Finding those needles in a five-millon-volume haystack is not easy. Many books in this period don’t carry genre tags; even when they do, volumes are heterogenous things. A volume of poetry, for instance, may begin with a prose life of the author and end with publishers’ ads.
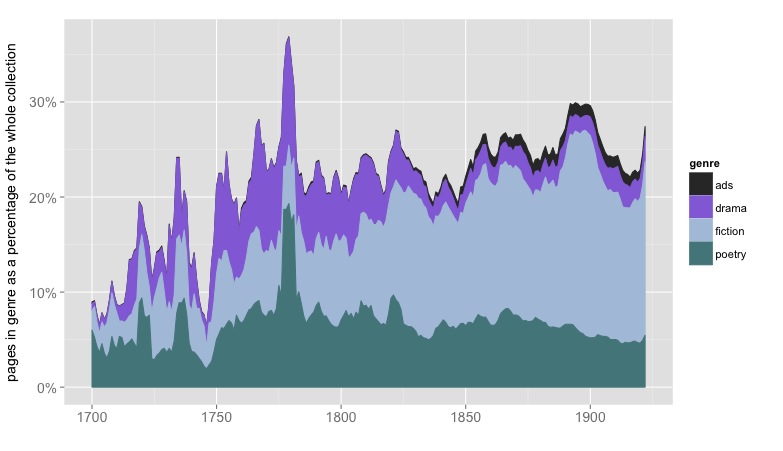
The relative sizes of different genres, represented as a percentage of pages in the English-language portion of HathiTrust. 854,476 volumes are covered. Nonfiction, front matter, and back matter aren’t represented here. Results have been smoothed with a five-year moving average.
To create datasets that reliably track a single genre, we need page-level metadata. The National Endowment for the Humanities and the American Council of Learned Societies funded a year-long project to create that metadata. (The methods involved are described in a white paper on “Understanding Genre,” along with information about accuracy.) Now, by pairing this metadata with HTRC’s page-level wordcounts, I’ve created three genre-specific datasets of word counts covering poetry, fiction, and drama from 1700 to 1922. (Coverage is relatively sparse before 1750; if you need the early eighteenth century, you might want a resource like ECCO-TCP instead of or in addition to this.)
The collection consists of word counts for 101,948 volumes of fiction, 58,724 volumes of poetry, and 17,709 volumes of drama, aggregated at the volume level and including only pages identified as belonging to the relevant genre. I’ve collected these volume-level files in tar.gz chunks by genre and date, and have provided basic metadata for them all. You can use the volume IDs to view the original texts on the HathiTrust website if you need to read them closely. I’m calling this a “collection” rather than a “corpus” because I don’t necessarily recommend that you use the whole thing, as is. The whole thing may or may not represent the sample you need for your research question. What it represents is, “American university and public libraries, insofar as they were digitized in the year 2012 (when the project began).” For some big diachronic questions, that’s a good sample; for other questions, you’ll need to be more selective.
Three big blocks of stone. Like collections, these don’t represent anything in particular. But like a statue, the corpus you want to create might be contained somewhere within them.
Because this is a very large collection, it’s likely in any case that the sample you need for your research may be contained somewhere within it. To address some questions, you might even select several samples and contrast them. To understand the history of literary prestige, for instance, Jordan Sellers and I gathered 360 prominent books of poetry by finding reviews in literary magazines and extracting the corresponding books from HathiTrust; we then contrasted that to a sample of 360 more obscure volumes selected from the whole HathiTrust collection of poetry. Just using volume-level wordcounts for those two samples, we were able to draw inferences about the way diachronic literary change is related to synchronic prestige.
Well-known texts may be represented in this dataset by dozens of reprints. For some questions, that may be exactly the sort of “weighted” sample you want; for other questions, you’ll want to winnow each title down to a single early example. More datasets may be developed to help you do that.
Distant reading rarely means “big data”
I realize the practice described above (selecting samples of a few hundred or a few thousand books to address particular questions) doesn’t line up with the version of distant reading currently circulating in public imagination. Isn’t the point of distant reading to construct a massive database that includes “everything that has been thought and said”?The Nation recently said so, and also warned us that “in reality, servers powerful enough to process big data can only be located in a highly select number of well-endowed institutions.”
That sounds grim, but I’m happy to report that it’s also malarkey. You can download this dataset, and process it, on your laptop. It’s true that I used our campus cluster to create it (because I had to manage a terabyte of text). But a) managing a terabyte won’t put a hole in most endowments, and b) you don’t need to do that anyway. Once nonfiction is set aside, we’re talking about a smaller group of books (compressed, this whole dataset runs to about 5GB). A well-designed sampling strategy can make it even smaller.
Wait, what’s this about “sampling”? aren’t distant readers supposed to claim to have everything? Not really. In the early days of distant reading, Franco Moretti did frame the project as a challenge to literary historians’ claims about synchronic coverage. (We only discuss a tiny number of books from any given period — what about all the rest?) But even in those early publications, Moretti acknowledged that we would only be able to represent “all the rest” through some kind of sample.
Fifteen years later, it’s becoming clear that distant reading has a lot of applications that aren’t about synchronic completeness at all. Expanding the diachronic scope of our research can be an equally important source of discovery. Certain kinds of change only become visible when you compare many examples across long timelines. Even if we restricted a digital corpus (say) to the academic canon, or to a thousand bestsellers, computational analysis would allow us to see long-term changes that aren’t visible to casual recollection.
It’s true that distant readers will often want to have the biggest possible table of metadata, so that our sampling strategies aren’t unduly constrained. But from that table, we may only sample a few hundred or a few thousand titles to address any single question. This scale of inquiry is not, in any meaningful sense, “big data.” (In fact, I doubt the phrase “big data” is often very meaningful, but that’s another story.) It’s a larger sample than literary scholars have usually attempted to describe, but it would not greatly distress our neighbors in linguistics and sociology.
How hard is this to use?
Of course, we’re not linguists or sociologists, so there is going to be a learning curve involved when we apply quantitative methods on any scale. The main dataset I’m providing here includes 178,381 separate files — one file for each volume. This is not something that can be sliced easily using a tool like Excel. Someone involved with the project needs to be able to program in order to pair the metadata table with the files.
On the other hand, there may be some questions that can be answered with a simple yearly summary, so I’ve also provided yearly_summary tables for each genre that aggregate term frequencies for the 10,000 most common tokens in each genre (selected by document frequency). This is the gentlest on-ramp to the dataset; data in this form probably can be sliced with Excel; to make it even easier I’ve also gone ahead and applied OCR correction and spelling normalization to those tables.
But the yearly_summary table aggregates all the volumes in the collection, and (as I’ve stressed) you may not want all of them. This dataset is a roughly-hewn, but very large, block of stone. You may be able to find the corpus you need somewhere within it, but decisions about selection are yours to make. Over the course of the next two years I hope to extend coverage further into the twentieth century; it is not illegal to share word counts from texts still covered by copyright. If you’re interested in more complex kinds of distant reading where word order matters, you can contact the HathiTrust Research Center; they are creating a workflow that can handle more complex kinds of computational analysis.
Postscript: We’ve done a lot of testing, but this is still a beta release. General estimates about error are summarized in “Understanding Genre”. Precision in these datasets is higher than 97%, but that still means there will be hundreds of volumes and thousands of pages mistakenly included. If you notice systematic problems with the data, please send feedback to the e-mail address provided in the data description. But individual misclassified volumes are not problems we’re likely to fix on a case-by-case basis; that sort of problem will be addressed by improving our methods in our next release.
The relative sizes of different genres, represented as a percentage of pages in the English-language portion of HathiTrust. 854,476 volumes are covered. Nonfiction, front matter, and back matter aren't represented here. Results have been smoothed with a five-year moving average.
Although methods of analysis are more fun to discuss, the most challenging part of distant reading may still be locating the texts in the first place [1].
In principle, millions of books are available in digital libraries. But literary historians need collections organized by genre, and locating the fiction or poetry in a digital library is not as simple as it sounds. Older books don’t necessarily have genre information attached. (In HathiTrust, less than 40% of English-language fiction published before 1923 is tagged “fiction” in the appropriate MARC control field.)
Volume-level information wouldn’t be enough to guide machine reading in any case, because genres are mixed up inside volumes. For instance Hoyt Long, Richard So, and I recently published an article in Slate arguing (among other things) that references to specific amounts of money become steadily more common in fiction from 1825 to 1950.
Frequency of reference to “specific amounts” of money in 7,700 English-language works of fiction. Graphics here and throughout from Wickham, ggplot2 [2].
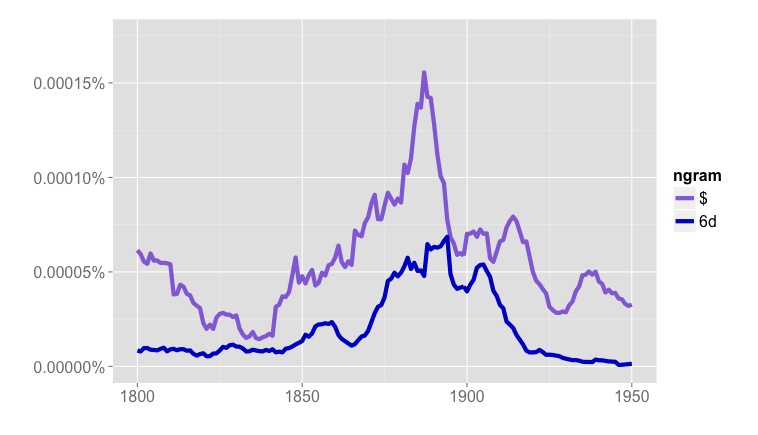
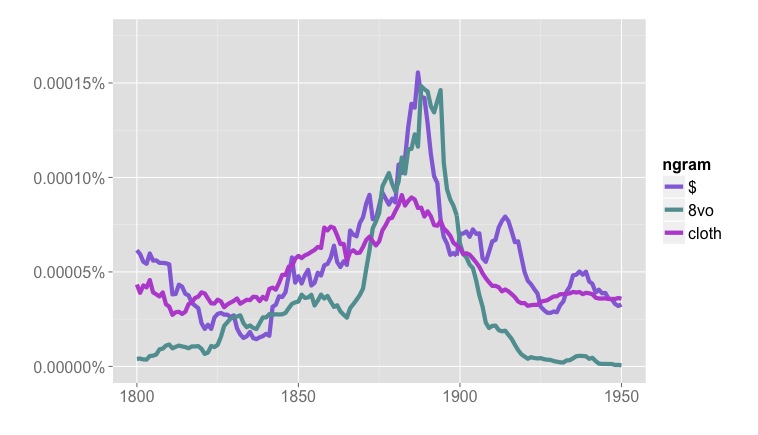
But Google’s “English Fiction” collection tells a very different story. The frequencies of many symbols that appear in prices (dollar signs, sixpence) skyrocket in the late nineteenth century, and then drop back by the early twentieth.
Frequencies of “$” and “6d” in Google’s “English Fiction” collection, 1800-1950.
Frequencies of “$”, “8vo” (octavo) and “cloth” in Google’s “English Fiction” collection, 1800-1950.
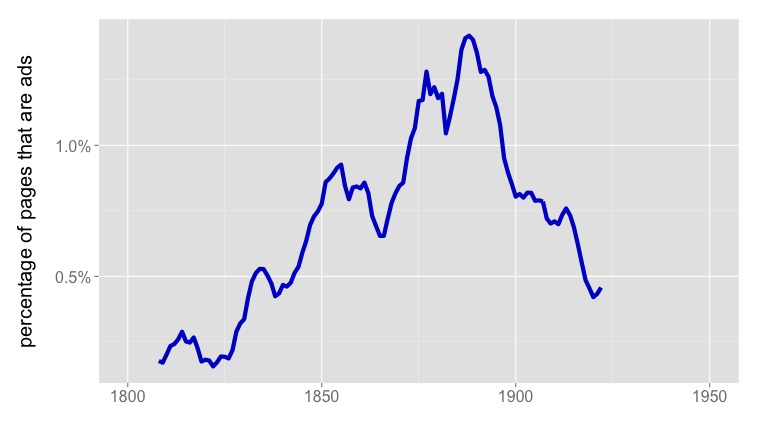
What we see in Google’s “Fiction” collection is something that happens in volumes of fiction, but not exactly in the genre of fiction — the rise and fall of publishers’ catalogs in the backs of books [3]. Individually, these two- or three-page lists of titles for sale may not look like significant noise, but because they often mention prices, and are distributed unevenly across the timeline, they add up to a significant potential pitfall for anyone interested in the role of money in fiction.
I don’t say this to criticize the team behind the Ngram Viewer. Genre wasn’t central to their goals; they provided a rough “fiction” collection merely as a cherry on top of a massively successful public-humanities project. My point is just that genres fail to line up with volume boundaries in ways that can really matter for the questions scholars want to pose. (In fact, fiction may be the genre that comes closest to lining up with volume boundaries: drama and poetry often appear mixed in The Collected Poems and Plays of So-and-So, With a Prose Life of the Author.)
You can solve this problem by selecting works manually, or by borrowing proprietary collections from a vendor. Those are both good, practical solutions, especially up to (say) 1900. But because they rely on received bibliographies, they may not entirely fulfill the promises we’ve been making about dredging the depths of “the great unread,” boldly going where no one has gone before, etc [4]. Over the past two years, with support from the ACLS and NEH, I’ve been trying to develop another alternative — a way of starting with a whole library, and dividing it by genre at the page level, using machine learning.
In researching the Slate article, we relied on that automatic mapping of genre to select pages of fiction from HathiTrust. It helped us avoid conflating advertisements with fiction, and I hope other scholars will also find that it reduces the labor involved in creating large, genre-specific collections. The point of this blog post is to announce the release of a first version of the map we used (covering 854,476 English-language books in HathiTrust 1700-1922).
We identify pages as paratext (front matter, back matter, ads), prose nonfiction, poetry (narrative and lyric are grouped together), drama (including verse drama), or prose fiction. The report discusses the rationale for these choices, but other choices would be possible.
“How accurate is this map?”
Since genres are social institutions, questions about accuracy are relative to human dissensus. Our pairs of human readers agreed about the five categories just mentioned for 94.5% of the pages they tagged [5]. Relying on two-out-of-three voting (among other things), we boiled those varying opinions down to a human consensus, and our model agreed with the consensus 93.6% of the time. So this map is nearly as accurate as we might expect crowdsourcing to be. But it covers 276 million pages. For full details, see the confusion matrices in the report. Also, note that we provide ways of adjusting the tradeoff between recall and precision to fit a researcher’s top priority — which could be catching everything that might belong in a genre, or filtering out everything that doesn’t belong. We provide filtered collections of drama, fiction, and poetry for scholars who want to work with datasets that are 97-98% precise.
The short answer: we can’t. I don’t expect the genre predictions in this dataset to be more than one resource among many. We’ve also designed this dataset to have a certain amount of flexibility. There are confidence metrics associated with each volume, and users can define their collection of, say, poetry more broadly or narrowly by adjusting the confidence thresholds for inclusion. So even this dataset is not really a single map.
“What about divisions below the page level?”
With the exception of divisions between running headers and body text, we don’t address them. There are certainly a wide range of divisions below the page level that can matter, but we didn’t feel there was much to be gained by trying to solve all those problems at the same time as page-level mapping. In many cases, divisions below the page level are logically a subsequent step.
“How would I actually use this map to find stuff?”
There are three different ways — see “How to use this data?” in the interim report. If you’re working with HathiTrust Research Center, you could use this data to define a workset in their portal. Alternatively, if your research question can be answered with word frequencies, you could download public page-level features from HTRC and align them with our genre predictions on your own machine to produce a dataset of word counts from “only pages that have a 97% probability of being prose fiction,” or what have you. (HTRC hasn’t released feature counts for all the volumes we mapped yet, but they’re about to.) You can also align our predictions directly with HathiTrust zip files, if you have those. The pagealigner module in the utilities subfolder of our Github repo is intended as a handy shortcut for people who use Python; it will work both with HT zip files and HTRC feature files, aligning them with our genre predictions and returning a list of pages zipped with genre codes.
Is this sort of collection really what I need for my project?
Maybe not. There are a lot of books in HathiTrust. But as I admitted in my last post, a medium-sized collection based on bibliographies may be a better starting point for most scholars. Library-based collections include things like reprints, works in translation, juvenile fiction, and so on, that could be viewed as giving a fuller picture of literary culture … or could be viewed as messy complicating factors. I don’t mean to advocate for a library-based approach; I’m just trying to expand the range of alternatives we have available.
“What if I want to find fiction in French books between 1900 and 1970?”
Although we’ve made our code available as a resource, we definitely don’t want to represent it as a “tool” that could simply be pointed at other collections to do the same kind of genre mapping. Much of the work involved in this process is domain-specific (for instance, you have to develop page-level training data in a particular language and period). So this is better characterized as a method than a tool, and the report is probably more important than the repo. I plan to continue expanding the English-language map into the twentieth century (algorithmic mapping of genre may in fact be especially necessary for distant reading behind the veil of copyright). But I don’t personally have plans to expand this map to other languages; I hope someone else will take up that task.
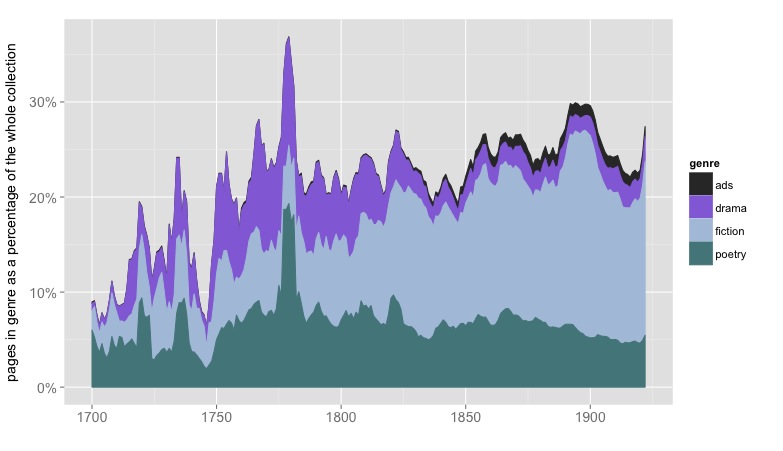
As a reward for reading this far, here’s a visualization of the relative sizes of genres across time, represented as a percentage of pages in the English-language portion of HathiTrust.
The relative sizes of different genres, represented as a percentage of pages in the English-language portion of HathiTrust. 854,476 volumes are covered. Nonfiction, front matter, and back matter aren’t represented here. Results have been smoothed with a five-year moving average. Click through to enlarge.
The blog post above often slips awkwardly into first-person plural, because I’m describing a project that involved a lot of people. Parts of the code involved were written by Michael L. Black and Boris Capitanu. The code also draws on machine learning libraries in Weka and Scikit-Learn [6, 7]. Shawn Ballard organized the process of gathering training data, assisted by Jonathan Cheng, Nicole Moore, Clara Mount, and Lea Potter. The project also depended on collaboration and conversation with a wide range of people at HathiTrust Digital Library, HathiTrust Research Center, and the University of Illinois Library, including but not limited to Loretta Auvil, Timothy Cole, Stephen Downie, Colleen Fallaw, Harriett Green, Myung-Ja Han, Jacob Jett, and Jeremy York. Jana Diesner and David Bamman offered useful advice about machine learning. Essential material support was provided by a Digital Humanities Start-Up Grant from the National Endowment for the Humanities and a Digital Innovation Fellowship from the American Council of Learned Societies. None of these people or agencies should be held responsible for mistakes.
References
[1] Perhaps it goes without saying, since the phrase has now lost its quotation marks, but “distant reading” is Franco Moretti, “Conjectures on World Literature,” New Left Review 1 (2000).
[2] Hadley Wickham, ggplot2: Elegant Graphics for Data Analysis.http: //had.co.nz/ggplot2/book. Springer New York, 2009.
[3] Having mapped advertisements in volumes of fiction, I’m pretty certain that they’re responsible for the spike in dollar signs in Google’s “English Fiction” collection. The collection I mapped overlaps heavily with Google Books, and the number of pages of ads in fiction volumes tracks very closely with the frequency of dollars signs, “8vo,” and so on.
Percentage of pages in mostly-fiction volumes that are ads. Based on a filtered collection of 102,349 mostly-fiction volumes selected from a larger group of 854,476 volumes 1700-1922. Five-year moving average.
[4] “The great unread” comes from Margaret Cohen, The Sentimental Education of the Novel (Princeton NJ: Princeton University Press, 1999), 23.
[5] See the interim report (subsection, “Evaluating Confusion Matrices”) for a fuller description; it gets complicated, because we actually assessed accuracy in terms of the number of words misclassified, although the classification was taking place at a page level.
[6] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
[7] Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, Peter Reutemann, and Ian H. Witten. The WEKA data mining software: An update. SIGKDD Explorations, 11(1), 2009.
There are basically two different ways to build collections for distant reading. You can build up collections of specific genres, selecting volumes that you know belong to them. Or you can take an entire digital library as your base collection, and subdivide it by genre.
Most people do it the first way, and having just spent two years learning to do it the second way, I’d like to admit that they’re right. There’s a lot of overhead involved in mining a library. The problem becomes too big for your desktop; you have to schedule batch jobs; you have to learn to interpret MARC records. All this may be necessary eventually, but it’s not the ideal place to start.
But some of the problems I’ve encountered have been interesting. In particular, the problem of “dividing a library by genre” has made me realize that literary studies is constituted by exclusions that are a bit larger and more arbitrary than I used to think.
First of all, why is dividing by genre even a problem? Well, most machine-readable catalog records don’t say much about genre, and even if they did, a single volume usually contains multiple genres anyway. (Think introductions, indexes, collected poems and plays, etc.) With support from the ACLS and NEH, I’ve spent the last year wrestling with that problem, and in a couple of weeks I’m going to share an imperfect page-level map of genre for English-language books in HathiTrust 1700-1923.
But the bigger thing I want to report is that the ambiguity of genre may run deeper than most scholars who aren’t librarians currently imagine. To be sure, we know that subgenres like “detective fiction” are social institutions rather than natural forms. And in a vague way we also accept that broader categories like “fiction” and “poetry” are social constructs with blurry edges. We can all point to a few anomalies: prose poems, eighteenth-century journalistic fictions like The Spectator, and so on.
But somehow, in spite of knowing this for twenty years, I never grasped the full scale of the problem. For instance, I knew the boundary between fiction and nonfiction was blurry in the 18c, but I thought it had stabilized over time. By the time you got to the Victorians, surely, you could draw a circle around “fiction.” Exceptions would just prove the rule.
Selecting volumes one by one for genre-specific collections didn’t shake my confidence. But if you start with a whole library and try to winnow it down, you’re forced to consider a lot of things you would otherwise never look at. I’ve become convinced that the subset of genre-typical cases (should we call them cis-genred volumes?) is nowhere near as paradigmatic as literary scholars like to imagine. A substantial proportion of the books in a library don’t fit those models. This is both a photograph of a real, unnamed mother and baby, and a picture of a fictional character named Shinkah. Frontispiece to Shinkah, The Osage Indian (1916).
Consider the case of Shinkah, the Osage Indian, published in 1916 by S. M. Barrett. The preface to this volume informs us that it’s intended as a contribution to “the sociology of the Osage Indians.” But it’s set a hundred years in the past, and the central character Shinkah is entirely fictional (his name just means “child.”) On the other hand, the book is illustrated with photographs of real contemporary people, who stand for the characters in an ethnotypical way.
After wading though 872,000 volumes, I’m sorry to report that odd cases of this kind are more typical of nineteenth- and early twentieth-century fiction than my graduate-school training had led me to believe. There’s a smooth continuum for instance between Shinkah and Old Court Life in France (1873), by Frances Elliot. This book has a bibliography, and a historiographical preface, but otherwise reads like a historical novel, complete with invented dialogue. I’m not sure how to distinguish it from other historical novels with real historical personages as characters.
Literary critics know there’s a problem with historical fiction. We also know about the blurry boundary between fiction, journalism, and travel writing represented by the genre of the “sketch.” And anyone who remembers James Frey being kicked out of Oprah Winfrey’s definition of nonfiction knows that autobiographies can be problematic. And we know that didactic fiction blurs into philosophical dialogue. And anyone who studies children’s literature knows that the boundary between fiction and nonfiction gets especially blurry there. And probably some of us know about ethnographic novels like Shinkah. But I’m not sure many of us (except for librarians) have added it all up. When you’re sorting through an entire library you’re forced to see the scale of it: in the period 1700-1923, maybe 10% of the volumes that could be cataloged as fiction present puzzling boundary cases.
You run into a lot of these works even if you browse or select titles at random; that’s how I met Shinkah. But I’ve also been training probabilistic models of genre that report, among other things, how certain or uncertain they are about each page. These models are good at identifying clear cases of our received categories; I found that they agreed with my research assistants almost exactly as often as the research assistants agreed with each other (93-94% of the time, about broad categories like fiction/nonfiction). But you can also ask a model to sift through several thousand volumes looking for hard cases. When I did that I was taken aback to discover that about half the volumes it had most trouble with were things I also found impossible to classify. The model was most uncertain, for instance, about The Terrific Register (1825) — an almanac that mixes historical anecdote, urban legend, and outright fiction randomly from page to page. The second-most puzzling book was Madagascar, or Robert Drury’s Journal (1729), a book that offers itself as a travel journal by a real person, and was for a long time accepted as one, although scholars have more recently argued that it was written by Defoe.
Of course, a statistical model of fiction doesn’t care whether things “really happened”; it pays attention mostly to word frequency. Past-tense verbs of speech, personal names, and “the,” for instance, are disproportionately common in fiction. “Is” and “also” and “mr” (and a few hundred other words) are common in nonfiction. Human readers probably think about genre in a more abstract way. But it’s not particularly miraculous that a model using word frequencies should be confused by the same examples we find confusing. The model was trained, after all, on examples tagged by human beings; the whole point of doing that was to reproduce as much as possible the contours of the boundary that separates genres for us. The only thing that’s surprising is that trawling the model through a library turns up more books right in the middle of the boundary region than our habits of literary attention would have suggested.
A lot of discussions of distant reading have imagined it as a move from canonical to popular or obscure examples of a (known) genre. But reconsidering our definitions of the genres we’re looking for may be just as important. We may come to recognize that “the novel” and “the lyric poem” have always been islands floating in a sea of other texts, widely read but never genre-typical enough to be replicated on English syllabi.
In the long run, this may require us to balance two kinds of inclusiveness. We already know that digital libraries exclude a lot. Allen Riddell has nicely demonstrated just how much: he concludes that there are digital scans for only about 58% of the novels listed in bibliographies as having been published between 1800 and 1836.
One way to ensure inclusion might be to start with those bibliographies, which highlight books invisible in digital libraries. On the other hand, bibliographies also make certain things invisible. The Terrific Register (1825), for instance, is not in Garside’s bibliography of early-nineteenth-century fiction. Neither is The Wonder-Working Water Mill (1791), to mention another odd thing I bumped into. These aren’t oversights; Garside et. al. acknowledge that they’re excluding certain categories of fiction from their conception of the novel. But because we’re trained to think about novels, the scale of that exclusion may only become visible after you spend some time trawling a library catalog.
I don’t want to present this as an aporia that makes it impossible to know where to start. It’s not. Most people attempting distant reading are already starting in the right place — which is to build up medium-sized collections of familiar generic categories like “the novel.” The boundaries of those categories may be blurrier than we usually acknowledge. But there’s also such a thing as fretting excessively about the synchronic representativeness of your sample. A lot of the interesting questions in distant reading are actually trends that involve relative, diachronic differences in the collection. Subtle differences of synchronic coverage may more or less drop out of questions about change over time.
On the other hand, if I’m right that the gray areas between (for instance) fiction and nonfiction are bigger and more persistently blurry than literary scholarship usually mentions, that’s probably in the long run an issue we should consider! When I release a page-level map of genre in a couple of weeks, I’m going to try to provide some dials that allow researchers to make more explicit choices about degrees of inclusion or exclusion.
Predictive models that report probabilities give us a natural way to handle this, because they allow us to characterize every boundary as a gradient, and explicitly acknowledge our compromises (for instance, trade-offs between precision and recall). People who haven’t done much statistical modeling often imagine that numbers will give humanists spuriously clear definitions of fuzzy concepts. My experience has been the opposite: I think our received disciplinary practices often make categories seem self-evident and stable because they teach us to focus on easy cases. Attempting to model those categories explicitly, on a large scale, can force you to acknowledge the real instability of the boundaries involved.
References and acknowledgments
Training data for this project was produced by Shawn Ballard, Jonathan Cheng, Lea Potter, Nicole Moore and Clara Mount, as well as me. Michael L. Black and Boris Capitanu built a GUI that helped us tag volumes at the page level. Material support was provided by the National Endowment for the Humanities and the American Council of Learned Societies. Some information about results and methods is online as a paper and a poster, but much more will be forthcoming in the next month or so — along with a page-level map of broad genre categories and types of paratext.
The project would have been impossible without help from HathiTrust and HathiTrust Research Center. I’ve also been taught to read MARC records by librarians and information scientists including Tim Cole, M. J. Han, Colleen Fallaw, and Jacob Jett, any of whom could teach a course on “Cursed Metadata in Theory and Practice.”
I mention Garside’s bibliography of early nineteenth-century fiction. This is Garside, Peter, and Rainer Schöwerling. The English novel, 1770-1829 : a bibliographical survey of prose fiction published in the British Isles. Ed. Peter Garside, James Raven, and Rainer Schöwerling. 2 vols. Oxford: Oxford University Press, 2000.
Perhaps not the most inspiring title. But the words are carefully chosen.
Basically, I’m sharing the code I use to correct OCR in my own research. I’ve shared parts of this before, but this is the first time I’ve made any effort to package it so that it will run on other people’s machines. If you’ve got Python 3.x, you should be able to clone this github repository, run OCRnormalizer.py, and point it at a folder of files you want corrected. The script is designed to handle data structures from HathiTrust, so (for instance) if you have zip files contained in a pairtree structure, it will recursively walk the directories to identify all zip files, concatenate pages, and write a file with the suffix “.clean.txt” in the same folder where each zip file lives. But it can also work on files from another source. If you point it at a flat folder of generic text files, it will correct those.
I’m calling this an OCR “normalizer” rather than “corrector” because it’s designed to accomplish very specific goals.
In my research, I’m mainly concerned with the kinds of errors that become problems for diachronic text mining. The algorithms I use can handle a pretty high level of error as long as those errors are distributed in a more-or-less random way. If a word is mistranscribed randomly in 200 different ways, each of those errors may be rare enough to drop out of the analysis. You don’t necessarily have to catch them all.
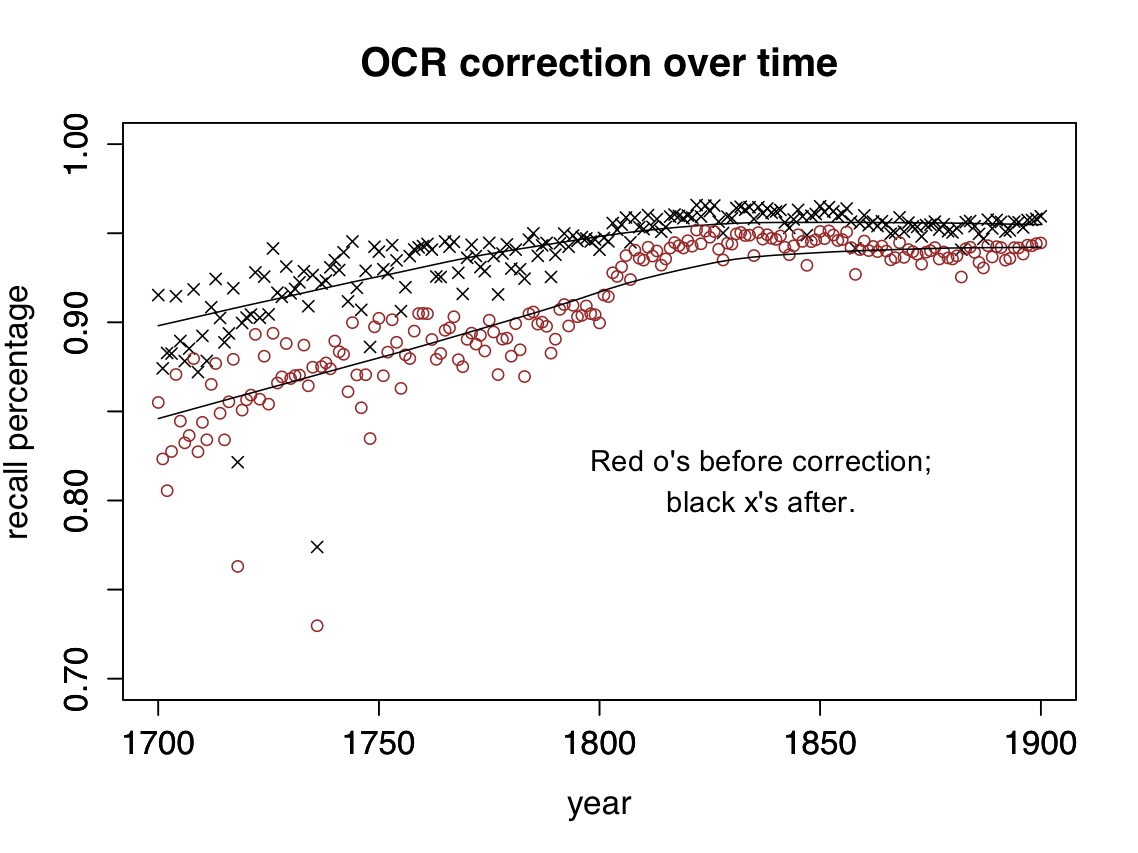
The percentage of tokens in the HathiTrust corpus that are recognized as words before (red) and after (black) correction by my script. Technically this is not “recall” but a count of (true and false) “positives.”The errors that become problems are the ones that cluster in particular words or periods. The notorious example is eighteenth-century “long S,” which caufes subftantial diflortions before 1820. Other errors caused by ligaturcs and worn typc also tend to cluster toward the early end of the timeline. But as you can see in the illustration above, long S is a particularly big issue; there’s a major improvement in OCR transcription shortly after 1800 as it gets phased out.
The range of possible OCR errors is close to infinite. It would be impossible to catch them all, and as you can see above, my script doesn’t. For a lot of nineteenth-century texts it produces a pretty small improvement. But it does normalize major variations (like long S) that would otherwise create significant distortions. (In cases like fame/same where a word could be either an OCR error or a real word, it uses the words on either side to disambiguate.)
Moreover, certain things that aren’t “errors” can be just as problematic for diachronic analysis. E.g., it’s a problem that “today” is sometimes written “to day” and sometimes “to-day,” and it’s a problem that eighteenth-century verbs get “condens’d.” A script designed to correct OCR might leave these variants unaltered, but in order to make meaningful diachronic comparisons, I have to produce a corpus where variations of spelling and word division are normalized.
The rulesets contained in the repo standardize (roughly) to modern British practice. Some of the rules about variant spellings were originally drawn, in part, from rules associated with the Wordhoard project, and the some of the rules for OCR correction were developed in collaboration with Loretta Auvil. Subfolders of the repo contain scripts I used to develop new rules.
I’ve called this release version 0.1 because it’s very rough. You can write Python in a disciplined, object-oriented way … but I, um, tend not to. This code has grown by accretion, and I’m sure there are bugs. More importantly, as noted above, this isn’t a generic “corrector” but a script that normalizes in order to permit diachronic comparison. It won’t meet everyone’s needs. But there may be a few projects out there that would find it useful as a resource — if so, feel free to fork it and alter it to fit your project!
The Artist in Despair Over the Magnitude of Antique Fragments, by Henry Fuseli.Just a quick note here to acknowledge a collaborative project that I hope will generate some useful resources for scholars interested in text mining. We don’t have many resources up on the website yet, but watch this space.
The principal investigators most actively involved in Uses of Scale are Ted Underwood (University of Illinois, Urbana-Champaign), Robin Valenza (University of Wisconsin, Madison), and Matt Wilkens (Notre Dame). All of us have been mining large collections of printed books, ranging from the early modern period to the twentieth century. We’ll be joining forces this year to reflect critically on problems of scale in literary research — including the questions that arise when we try to connect different scales of analysis. But we also hope to generate a few resources that are immediately and practically useful for scholars attempting to “scale up” their research projects (resources, for instance, for correcting OCR). There’s already a bare-bones list of OCR-correction rules on the website, as well a description of a more ambitious project now underway.
This post is an outline of discussion topics I’m proposing for a workshop at NASSR2012 (a conference of Romanticists). I’m putting it on the blog since some of the links might be useful for a broader audience.
In the morning I’ll give a few examples of concrete literary results produced by text mining. I’ll start the afternoon workshop by opening two questions for discussion: first, what are the obstacles confronting a literary scholar who might want to experiment with quantitative methods? Second, how do those methods actually work, and what are their limits?
I’ll also invite participants to play around with a collection of 818 works between 1780 and 1859, using an R program I’ve provided for the occasion. Links for these materials are at the end of this post.
I. HOW DIFFICULT IS IT TO GET STARTED?
There are two kinds of obstacles: getting the data you need, and getting the digital skills you need.
1. Is it really necessary to have a large collection of texts?
This is up for debate. But I tend to think the answer is “yes.”
Not because bigger is better, or because “distant reading” is the new hotness. It’s still true that a single passage, perceptively interpreted, may tell us more than a thousand volumes.
But if you want to interpret a single passage, you fortunately already have a wrinkled protein sponge that will do a better job than any computer. Quantitative analysis starts to make things easier only when we start working on a scale where it’s impossible for a human reader to hold everything in memory. Your mileage may vary, but I’d say, more than ten books?
And actually, you need a larger collection than that, because quantitative analysis tends to require context before it becomes meaningful. It doesn’t mean much to say that the word “motion” is common in Wordsworth, for instance, until we know whether “motion” is more common in his works than in other nineteenth-century poets. So yes, text-mining can provide clues that lead to real insights about a single author or text. But it’s likely that you’ll need a collection of several hundred volumes, for comparison, before those clues become legible.
Words that are consistently more common in works by William Wordsworth than in other poets from 1780 to 1850. I’ve used Wordle’s graphics, but the words have been selected by a Mann-Whitney test, which measures overrepresentation relative to a context — not by Wordle’s own (context-free) method. See the R script at the end of this post.
This isn’t to deny that there are interesting things that can be done digitally with a single text: digital editing, building timelines and maps, and so on. I just doubt that quantitative analysis adds much value at that scale. (And to give credit where it’s due: Mark Olsen was saying all this back in the 90s — see References.)
2. So, where do I get all those texts?
That’s what I was asking myself 18 months ago. A lot of excitement about digital humanities is premised on the notion that we already have large collections of digitized sources waiting to be used. But it’s not true, because page images are not the same thing as clean, machine-readable text.
If you’re interested in twentieth-century secondary sources, the JSTOR Data for Research API can probably get you what you need. Primary sources are a harder problem. In our own (Romantic) era, optical character recognition (OCR) is unreliable. The ratio of words transcribed accurately ranges from around 80% to around 98%, depending on print quality and typographical quirks like the notorious “long s.” For a lot of text-mining purposes, 95% might be fine, if the errors were randomly distributed. But they’re not random: errors cluster in certain words and periods.
What you see in a page image.
The problem can be addressed in several different ways. There are a few collections (like ECCO-TCP and the Brown Women Writers Project) that transcribe text manually. That’s an ideal solution, but coverage of that kind is stronger in the eighteenth than the nineteenth century.
What you may see as OCR.
So Jordan Sellers and I have supplemented those collections by automatically correcting 19c OCR that we got from the Internet Archive. Our strategy involved statistically cautious, period-specific spellchecking, combined with enough reasoning about context to realize that “mortal fin” is probably “mortal sin,” even though “fin” is a correctly spelled word. It’s not a perfect solution, but in our period it works well enough for text-mining purposes. We have corrected about 2,000 volumes this way, and are happy to share our texts and metadata, as well as the spellchecker itself (once I get it packaged well enough to distribute). I can give you either a zip file containing the 19c texts themselves, or a tab-separated file containing docIDs, words, and word counts for the whole collection. In either scheme, the docIDs are keyed to this metadata file.
Of course, selecting titles for a collection like this raises intractable questions about representativeness. We tried to maximize diversity while also selecting volumes that seemed to have reached a significant audience. But other scholars may have other priorities. I don’t think it would be useful to seek a single right answer about representativeness; instead, I’d like to see multiple scholars building different kinds of collections, making them all public, and building on each other’s work. Then we would be able to test a hypothesis against multiple collections, and see whether the obvious caveats about representativeness actually make a difference in any given instance.
3. Is it necessary to learn how to program?
I’m not going to try to answer that question, because it’s complex and better addressed through discussion.
I will tell a brief story. I went into this gig thinking that I wouldn’t have to do my own programming, since there were already public toolsets for text-mining (Voyant, MONK, MALLET, TAPoR, SEASR) and for visualization (Gephi). I figured I would just use those.
But I rapidly learned otherwise. Tools like MONK and Voyant taught me what was possible, but they weren’t well adapted for managing a very large collection of texts, and didn’t permit me to make my own methodological innovations. When you start trying to do either of those things, you rapidly need “nonstandard parts,” which means that someone in the team has to be able to program.
That doesn’t have to be a daunting prospect, because the programming involved is of a relatively forgiving sort. It’s not easy, but it’s also not professional software development. So if you want to do it yourself, that’s a plausible aspiration. Alternately, if you want to collaborate with someone, you don’t necessarily need to find “a computer scientist.” A graduate student or fellow humanist who can program will do just fine.
If you do want to learn to program, I would recommend starting with either Python or R. Of the two languages, Python is certainly easier. It’s intuitive, and well-documented, and great for working with text. If you expect to use existing tools (like MALLET), and just need some “glue” to connect them to each other, Python is probably the way to go. R is a more specialized and less intuitive language. But it happens to be specialized in some ways that are useful for text mining. In particular, it has built-in statistical functions, and a built-in plotting/graphing capacity. I’ve used it for the sample exercise that accompanies this post. But if you’re learning to program for the first time, Python might be a better all-around choice, and you could in principle extend it to do everything R does. [Later addition: You could do worse than start with The Programming Historian.]
II. WHAT CAN WE ACTUALLY DO WITH QUANTITATIVE METHODS?
What follows is just a list of elements. Interesting research projects tend to combine several of these elementary operations in ad-hoc ways suited to a particular question. The list of elements runs a little long, so let me cut to the chase: the overall theme I’m trying to convey is that you can build complex arguments on a very simple foundation. Yes, at bottom, text mining is often about counting words. But a) words matter and b) they hang together in interesting ways, like individual dabs of paint that together start to form a picture.
So, to return to the original question: what can we do?
1) Categorize documents. You can “categorize” in several different senses.
a) Information retrieval: retrieve documents that match a query. This is what you do every time you use a search engine.
b) (Supervised) classification: a program can learn to correctly distinguish texts by a given author, or learn (with a bit more difficulty) to distinguish poetry from prose, tragedies from history plays, or “gothic novels” from “sensation novels.” (See “Quantitative Formalism,” Pamphlet 1 from the Stanford Literary Lab.) The researcher has to provide examples of different categories, but doesn’t have to specify how to make the distinction: algorithms can learn to recognize a combination of features that is the “fingerprint” of a given category.
An example of clustering from “Quantitative Formalism,” Allison, Heuser, Jockers, Moretti, and Witmore, Stanford Literary Lab.
c) (Unsupervised) clustering: a program can subdivide a group of documents using general measures of similarity instead of predetermined categories. This may reveal patterns you don’t expect.
All three of these techniques can achieve amazing results armed with what seems like very crude information about the documents they’re categorizing. We know, intuitively, that merely counting words is not enough to distinguish a tragedy from a history play. But our intuitions are simply wrong — see the lit lab pamphlet I cited above. It turns out that there’s an enormous amount of information contained in relative word frequencies, even if you know nothing about sequence or syntax. As you consider other aspects of text mining, it’s useful to keep this intuitive misfire in mind. Relatively simple statistical techniques often characterize discourse a good deal better than our intuitions would predict.
2) Contrast the vocabulary of different corpora. In a way, this reverses the logic of classifying documents (1b). Instead of using features to sort documents into categories, you start with two categories of documents and contrast them to identify distinctive features.
For instance, you can discover which words (or phrases) are overrepresented in one author or genre (relative to, say, the rest of nineteenth-century literature). It can admittedly be a challenge to interpret the results: this is a kind of evidence we aren’t accustomed to yet. But lists of overrepresented words can be a fruitful source of critical leads to pursue in more traditional ways.
3) Trace the history of particular features (words or phrases) over time. This could be viewed as a special category of corpus comparison, where you’re comparing corpora segmented on the time axis.
The best-known example here would be Google’s ngram viewer. Digital humanists love to criticize the ngram viewer, partly for valid reasons (there’s no way to know what texts are being used). But it has probably been the single most influential application of text mining, so clearly people are finding this simple kind of diachronic visualization useful. A couple of other projects have built on the same dataset, slicing it in different ways. Mark Davies of BYU built an interface that lets you survey the history of collocations. Our team at Illinois built an interface that mines 18-19c correlations in the ngram dataset; it turns out that correlated words have a high likelihood of being related in other ways as well, and these can be intriguing leads: see what words correlate with “delicacy” in our period, for instance. Harvard has built Bookworm, which can be understood as a smaller but more flexible and better-documented version of the ngram viewer (built on the Open Library instead of Google Books).
Words whose frequencies correlate strongly over time are often related in other ways as well. Ngram viewer by Auvil, Capitanu, Heuser and Underwood, based on corrected Google dataset.
Of special interest to Romanticists: a project that isn’t built on the ngram dataset but that does use diachronic correlation-mining as a central methodology. In Stanford Lit Lab Pamphlet 4, Ryan Heuser and Long Le-Khac have traced some very interesting, strongly correlated changes in novelistic diction over the course of the 19th century.
Finally, anyone who wants to make a diachronic argument about diction should read Ben Schmidt’s simple, elegant experiment peeling apart two different components of change: generational succession and historical change within the diction of a single age-cohort.
4) Cluster features that tend to be associated in a given corpus of documents (aka topic modeling). In a way, this reverses the logic of clustering documents (1c). Instead of grouping documents that tend to share the same words, you group words that tend to appear in the same documents, or parts of documents. This produces something that looks like a semantic map of the period or corpus you’re studying. (It would be more accurate to call it a discursive map, because topics don’t actually have to be unified semantically. They are more analogous to “discourses.”)
There are a lot of ways to cluster features, ranging from older approaches (Latent Semantic Analysis), to the new, hip approach — “Bayesian topic modeling,” which has the advantage that it clusters individual occurrences of words (tokens) instead of word types. As a result, it can distinguish different senses of a word. (Scott Weingart has written a clear and comprehensive introduction to topic modeling for humanists.)
Topic modeling has become justifiably popular for several reasons. First and foremost, a “discursive map” can be a nice thing to have; it lends itself easily to interpretation. Also, frankly, this approach doesn’t require a whole lot of improvisation. You just pour text files into a tool like MALLET, and out come a list of topics, looking meaningful and authoritative. It’s important to remember that topic-modeling is in fact an imprecise process. Slightly different inputs (for instance, a different stopword list) can produce very different outputs.
5) Entity extraction. If you’re mainly interested in proper nouns (personal names or place names, or dates and prices) there are tools like OpenNLP that can extract these from text, using syntactic patterns as clues.
6) Visualization. Perhaps this isn’t technically a form of analysis, but in practice it’s important enough that it deserves to be treated as a separate analytical step. It’s impractical to list all possible forms of visualization here, but for instance, results can be visualized:
a) Geographically — to reflect, for instance, density of references to different parts of the world. (See
b) As a network graph — to reflect strength of affinity between different entities (characters, or topics, or what have you).
c) Through “Principal Component Analysis,” if you have multidimensional data that need to be flattened to two dimensions for ease of comprehension.
Putting things together.
There’s no limit to the number of ways you can combine these different operations. Matt Wilkens has extracted references to named entities from fiction, and then visualized their density geographically. Robert K. Nelson has performed topic modeling on the print run of a Civil-War-era newspaper, and then graphed the frequency of each topic over time. You could go a step further and look for correlations between topics (either over time, or in terms of their distribution over documents). Then you could visualize the relationships between topics as a network.
What’s the goal uniting all this experimentation? I suspect there are two different but equally valid goals. In some cases, we’re going to find patterns that actually function as evidence to support literary-historical arguments. (In a number of the examples cited above, I think that’s starting to happen.) In other cases, text mining may work mainly as an exploratory technique, revealing clues that need to be fleshed out and written up using more traditional critical methods. The boundary between those two applications will be hotly debated for years, so I won’t attempt to define it here.
III. SAMPLE DATA AND SCRIPT FOR EXPLORATION.
I don’t know whether we’ll really have time for this, but I ought to at least offer you a chance to do hands-on stuff. So here’s a medium-sized project.
Finally, I’ve provided an R script that will let you define different chunks of the collection and compare them against each other, to identify words that are significantly overrepresented in a given author, genre, or period. The script will try two different measures of “overrepresentation”: the first, “log-likelihood,” is based on the aggregate frequency of words in the corpus you selected, adding all the volumes in the corpus together. The second, “Mann-Whitney rho,” tries to locate words that are consistently more common in corpus X by paying attention to individual volumes. For more on how that works, see this blog post.
Of course, the R script won’t work until you download R and open it from within R. Please understand that this is a very rough, ad-hoc piece of work for this one occasion, not a polished piece of software that I expect people to use for the long term.
Postscript about the word “mining.”
I know it has an industrial sound; I know humanists like “analysis” more. But I’m sticking with the mining metaphor on the principle of truth in advertising. I think that word accurately conveys the scale of this enterprise, and the fact that it’s often more exploratory than probative. Besides, “mining” is vivid, and that has its own sort of humanistic value.
References (that aren’t already implicit in links)
Mark Olsen, “Signs, Symbols, and Discourses: A New Direction for Computer-Aided Literature Studies” Computers and the Humanities 27 (1993): 309-314.
NYPL, photo courtesy Alex ProimosA fair number of scholars would like to work on large digital collections, but aren’t entirely sure where to get them.
For people who work on text after, say, 1700, I’d like to briefly make a case for HathiTrust. I’m a few months into a project based on 800,000 volumes — collaborating with Mike Black, an English Ph.D student and extraordinary Python programmer. We decided to get our collection from HathiTrust, and it’s a decision I haven’t regretted. In terms of sheer numbers, I don’t know whether they’re larger than, say, the Internet Archive. But their collection has some subtle details that I’ve come to greatly appreciate.
For one thing, they divide documents into individual page files. At first this may seem like a pain (you want a file, right, not a folder of files?) But in fact it’s a significant advantage to have that hard-coded representation of page breaks. It has made it possible for Mike to design a Python script that a) recognizes running headers at the tops of pages b) uses them to make a reasonable guess about chapters and other document divisions and then c) removes the headers, which can otherwise throw a wrench in your topic model.
Also, the HathiTrust API is solid and well documented. If you request a large dataset from them, you will get metadata with it. But the availability of the bibliographic API can still be a significant benefit. (By the way, re: metadata — ask them to give you the complete .json record, not just the marc-record part of the json.)
For small numbers of texts, you could in fact get the text itself from the data API. But this is not recommended for a big collection. Instead you’re going to want to write Hathi and request that they construct a dataset for you, based on facets that would be available in their Advanced Search feature. Once they build it — which could take a few weeks to a month — you can send them a hard drive or download data through rsync. (I initially found rsync perplexing, but after the nice people at Hathi gave me precise instructions, it was easy.) Using rsync through my campus office connection, it took about two days to transfer 800,000 volumes, which consumed a little less than 1TB of disk space. It would have been slower if I had tried to do it at home through commercial broadband and an AirPort.
There is a lot of time involved simply in moving data around, and in part I’m writing this post to warn people about that. One really basic point that took me a while to figure out: do not try to unzip the files. Part of the reason why it’s slow to move a large collection is that separate files require your i/o to do a lot of starting and stopping. That’s hard enough with (say) 500,000 separate zipped document folders. If you unzip those documents and get 165 million separate page files, it becomes very hard indeed. I actually spent more than a week unzipping the collection, and about a week trying to move it from one drive to another — only to get a disk error halfway through the process that required reformat.
Mothers, teach your children not to do as I have done. Just use the Python module zipfiles that works directly with the .zip file. It takes Python a few tenths of a second to extract the data, but it’s much better than trying to move 165 million individual pages. H/t to Loretta Auvil, by the way, for convincing me that this was simpler.
I’m going to try to make available the Python scripts and lexica that Mike and I design for working with the collection. There are
a) Simple logistical issues, like navigating the pairtree folder structure where files are stored and extracting them from .zip.
b) Metadata issues, like normalizing dates of publication that can be “1871” or “[18–]”.
c) Document-format issues, like running headers and page numbers.
d) OCR issues, which are the really fun ones as far as I’m concerned.
We’ve written pieces of all of this, and (a) through (c) are working, but it’s not yet in beta (to put it mildly). However, if you’re grappling with a similar problem, drop me a line and I’ll send you our code, such as it is. Development of this code was supported by the Andrew W. Mellon Foundation.
I’d also like to encourage everyone who’s interested in these kinds of problems to attend the HathiTrust Research Center UnCamp in Indiana this September (pre-register by August 1). This should be particularly useful if you’re interested in working on collections after 1923. HTRC has begun to design an infrastructure that will permit non-consumptive or non-expressive research on texts without transmitting the text itself to the researcher — obviously a crucial part of the solution to the problem of research on copyrighted text. They hope to demo parts of that infrastructure in September — but if you show up, you also have a fair chance of getting input on the design of the final version.
I’m still fairly new at this gig, so take the following with a grain of salt. But the more I explore the text-mining side of DH, the more I wonder whether we need to rethink our priorities.
Over the last ten years we’ve been putting a lot of effort into building tools and cyberinfrastructure. And that’s been valuable: projects like MONK and Voyant play a crucial role in teaching people what’s possible. (I learned a lot from them myself.) But when I look around for specific results produced by text-mining, I tend to find that they come in practice from fairly simple, ad-hoc tools, applied to large datasets.
Ben Schmidt’s blogSapping Attention is a good source of examples. Ben has discovered several patterns that really have the potential to change disciplines. For instance, he’s mapped the distribution of gender in nineteenth-century collections, and assessed the role of generational succession in vocabulary change. To do this, he hasn’t needed natural language processing, or TEI, or even topic modeling. He tends to rely on fairly straightforward kinds of corpus comparison. The leverage he’s getting comes ultimately from his decision to go ahead and build corpora as broad as possible using existing OCR.
I think that’s the direction to go right now. Moreover, before 1923 it doesn’t require any special agreement with publishers. There’s a lot of decent OCR in the public domain, because libraries can now produce cleaner copy than Google used to. Yes, some cleanup is still needed: running headers need to be removed, and the OCR needs to be corrected in period-sensitive ways. But it’s easier than people think to do that reliably. (You get a lot of clues, for instance, from cleaning up a whole collection at once. That way, the frequency of a particular form across the collection can help your corrector decide whether it’s an OCR error or a proper noun.)
In short, I think we should be putting a bit more collective effort into data preparation. Moreover, it seems to me that there’s a discernible sweet spot between vast collections of unreliable OCR and small collections of carefully-groomed TEI. What we need are collections in the 5,000 – 500,000 volume range, cleaned up to at least (say) 95% recall and 99% precision. Precision is more important than recall, because false negatives drop out of many kinds of analysis — as long as they’re randomly distributed (i.e. you can’t just ignore the f/s problem in the 18c). Collections of that kind are going to generate insights that we can’t glimpse as individual readers. They’ll be especially valuable once we enrich the metadata with information about (for instance) genre, gender, and nationality. I’m not confident that we can crowdsource OCR correction (it’s an awful lot of work), but I am confident that we could crowdsource some light enrichment of metadata.
So this is less a manifesto than a plan of action. I don’t think we need a center or a grant for this kind of thing: all we need is a coalition of the willing. I’ve asked HathiTrust for English-language OCR in the 18th and 19th centuries; once I get it, I’ll clean it up and make the cleaned version publicly available (as far as legally possible, which I think is pretty far). Then I’ll invite researchers to crowdsource metadata in some fairly low-tech way, and share the enriched metadata with everyone who participated in the crowdsourcing.
I would eagerly welcome suggestions about the kinds of metadata we ought to be recording (for instance, the genre categories we ought to use). Questions about selection/representativeness are probably better handled by individual researchers; I don’t think it’s possible to define a collective standard on that point, because people have different goals. Instead, I’ll simply take everything I can get, measure OCR quality, and allow people to define their own selection criteria. Researchers who want to produce a specific balance between X and Y can always do that by selecting a subset of the collection, or by combining it with another collection of their own.
I love Karen Coyle’s idea that we should make OCR usable by identifying the best-available copy of each text. It’s time to start thinking about this kind of thing. Digital humanists have been making big claims about our ability to interpret large collections. But — outside of a few exemplary projects like EEBO-TCP — we really don’t have free access to the kind of large, coherent collections that our rhetoric would imply. We’ve got feet of clay on this issue. Do you think the 'ct' ligature looks a little like an ampersand? Well, so do OCR engines.
Moreover, this wouldn’t be a difficult problem to address. I think it can be even simpler than Coyle suggests. In many cases, libraries have digitized multiple copies of a single edition. The obvious, simple thing to do is just:
Measure OCR quality — automatically, using a language model rather than ground truth — and associate a measurement of OCR quality with each bibliographic record.
This simple metric would save researchers a huge amount of labor, because a scholar could use an API to request “all the works you have between 1790 and 1820 that are above 90% probable accuracy” or “the best available copy of each edition in this period,” making it much easier to build a meaningfully normalized corpus. (This may be slightly different from Coyle’s idea about “urtexts,” because I’m talking about identifying the best copy of an edition rather than the best edition of a title.) And of course a metric destroys nothing: if you want to talk about print culture without filtering out poor OCR, all that metadata is still available. All this would do is empower researchers to make their own decisions.
One could go even further, and construct a “Frankenstein” edition by taking the best version of each page in a given edition. Or one could improve OCR with post-processing. But I think those choices can be left to individual research projects and repositories. The only part of this that really does need to be a collective enterprise is an initial measurement of OCR quality that gets associated with each bibliographic record and exposed to the API. That measurement would save research assistants thousands of hours of labor picking “the cleanest version of X.” I think it’s the most obvious thing we’re lacking.
[Postscript: Obviously, researchers can do this for themselves by downloading everything in period X, measuring OCR quality, and then selecting copies accordingly. In fact, I’m getting ready to build that workflow this summer. But this is going to take time and consume a lot of disk space, and it’s really the kind of thing an API ought to be doing for us.]


 So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.

![Frequency of reference to "specific amounts" of money in 7,700 English-language works of fiction. Graphics from Wickham, ggplot2 [2].](https://tedunderwood.com/wp-content/uploads/2014/12/finalfreq.jpeg)