
by Andrew Goldstone and Ted Underwood
Of all our literary-historical narratives it is the history of criticism itself that seems most wedded to a stodgy history-of-ideas approach—narrating change through a succession of stars or contending schools. While scholars like John Guillory and Gerald Graff have produced subtler models of disciplinary history, we could still do more to complicate the narratives that organize our discipline’s understanding of itself.

Topic modeling is a technique that automatically identifies groups of words that tend to occur together in a large collection of documents. It was developed about a decade ago by David Blei among others. Underwood has a blog post explaining topic modeling, and you can find a practical introduction to the technique at the Programming Historian. Jonathan Goodwin has explained how it can be applied to the word-frequency data you get from JSTOR.
Obviously, PMLA is not an adequate synecdoche for literary studies. But, as a generalist journal with a long history, it makes a useful test case to assess the value of topic modeling for a history of the discipline.
Goldstone and Underwood each independently produced several different models of PMLA, using different software, stopword lists, and numbers of topics. Our results overlapped in places and diverged in places. But we’ve reached a shared sense that topic modeling can enrich the history of literary scholarship by revealing trends that are presently invisible.
What is a topic?
A “topic model” assigns every word in every document to one of a given number of topics. Every document is modeled as a mixture of topics in different proportions. A topic, in turn, is a distribution of words—a model of how likely given words are to co-occur in a document. The algorithm (called LDA) knows nothing “meta” about the articles (when they were published, say), and it knows nothing about the order of words in a given document.
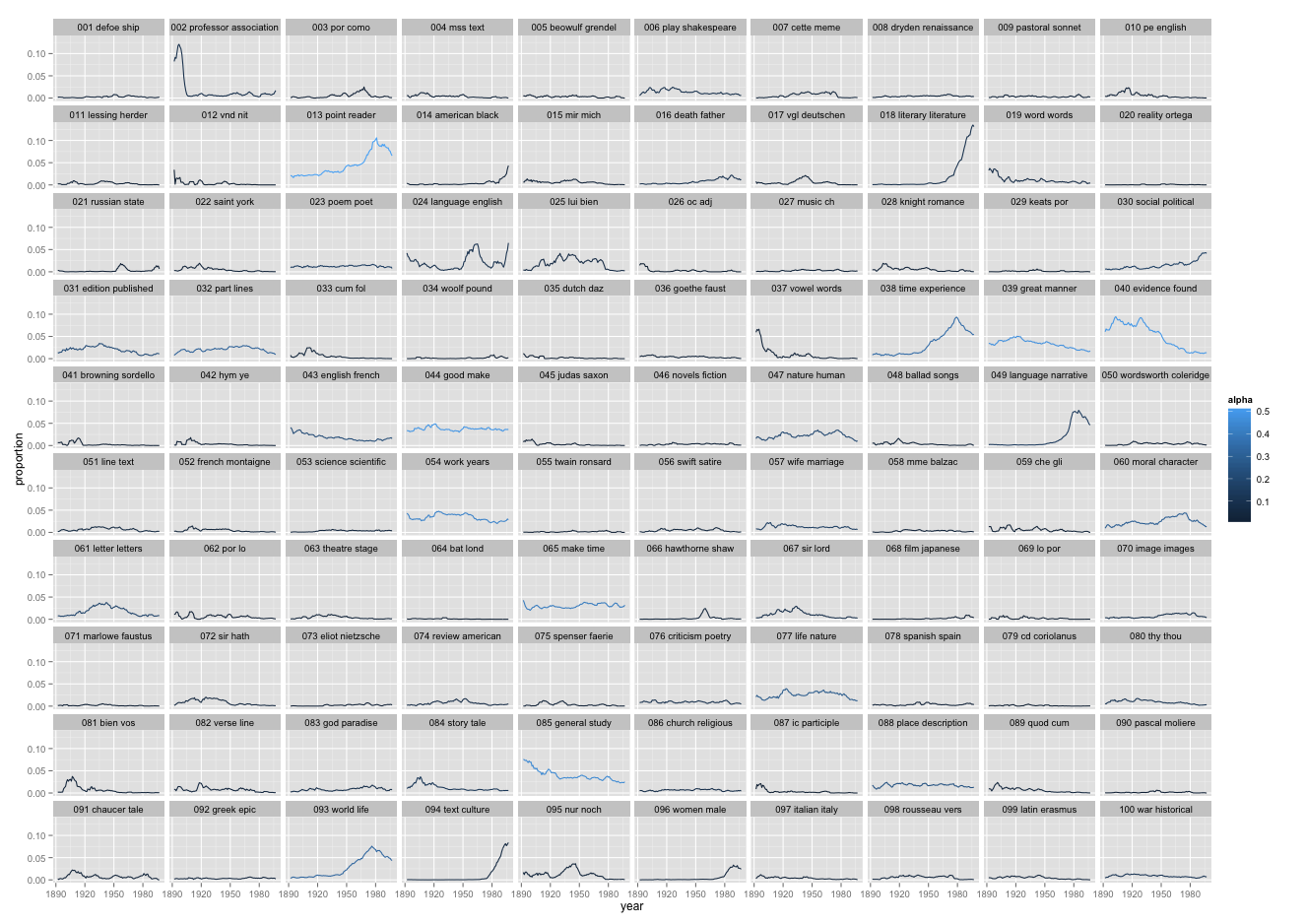
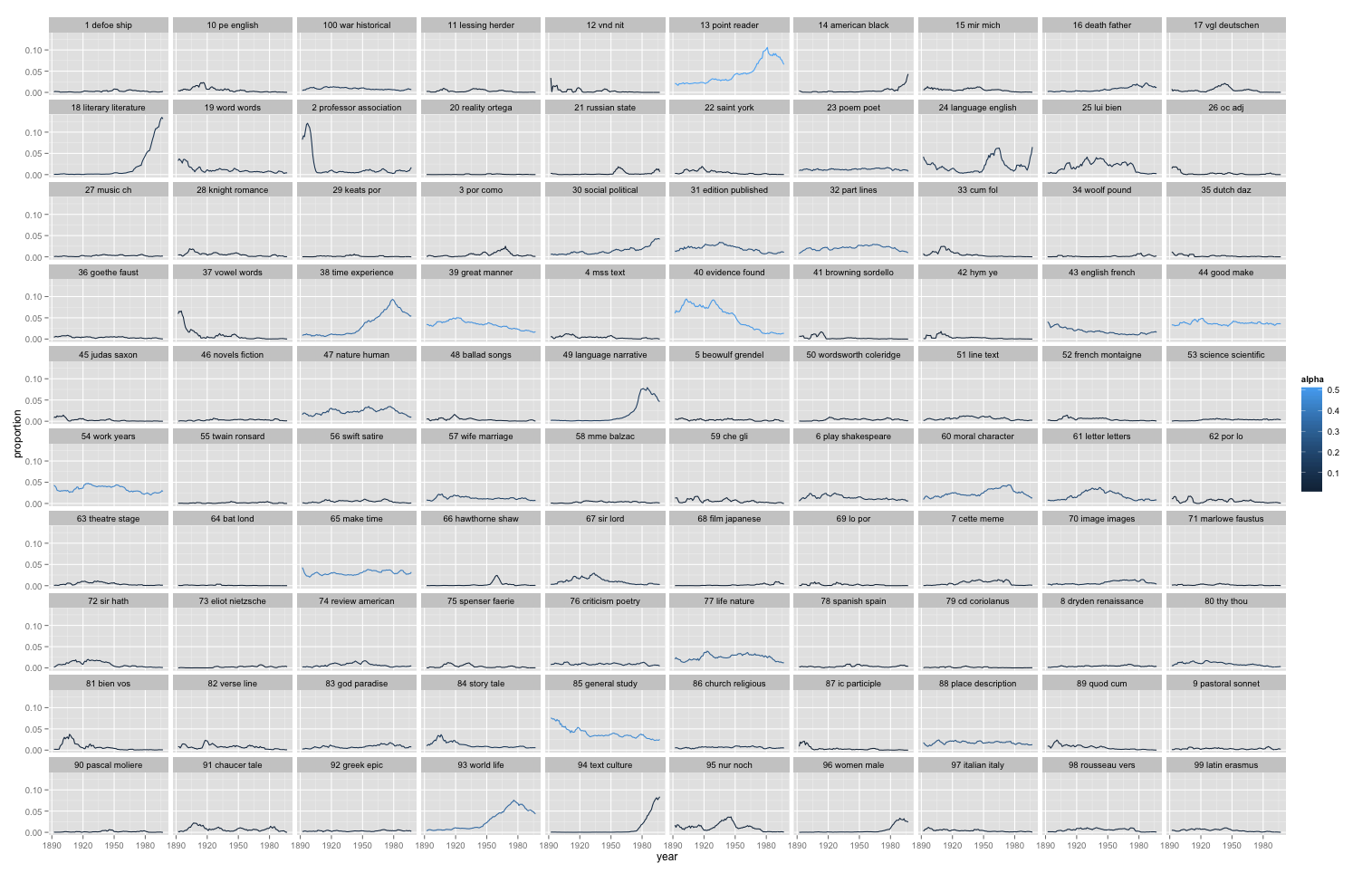
This is a picture of 5940 articles from PMLA, showing the changing presence of each of 100 "topics" in PMLA over time. (Click through to enlarge; a longer list of topic keywords is here.) For example, the most probable words in the topic arbitrarily numbered 59 in the model visualized above are, in descending order:
che gli piu nel lo suo sua sono io delle perche questo quando ogni mio quella loro cosi dei
This is not a “topic” in the sense of a theme or a rhetorical convention. What these words have in common is simply that they’re basic Italian words, which appear together whenever an extended Italian text occurs. And this is the point: a “topic” is neither more nor less than a pattern of co-occurring words.
Nonetheless, a topic like topic 59 does tell us about the history of PMLA. The articles where this topic achieved its highest proportion were:
Antonio Illiano, “Momenti e problemi di critica pirandelliana: L’umorismo, Pirandello e Croce, Pirandello e Tilgher,” PMLA 83 no. 1 (1968): pp. 135-143
Domenico Vittorini, “I Dialogi ad Petrum Histrum di Leonardo Bruni Aretino (Per la Storia del Gusto Nell’Italia del Secolo XV),” PMLA 55 no. 3 (1940): pp. 714-720
Vincent Luciani, “Il Guicciardini E La Spagna,” PMLA 56 no. 4 (1941): pp. 992-1006
And here’s a plot of the changing proportions of this topic over time, showing moving 1-year and 5-year averages:
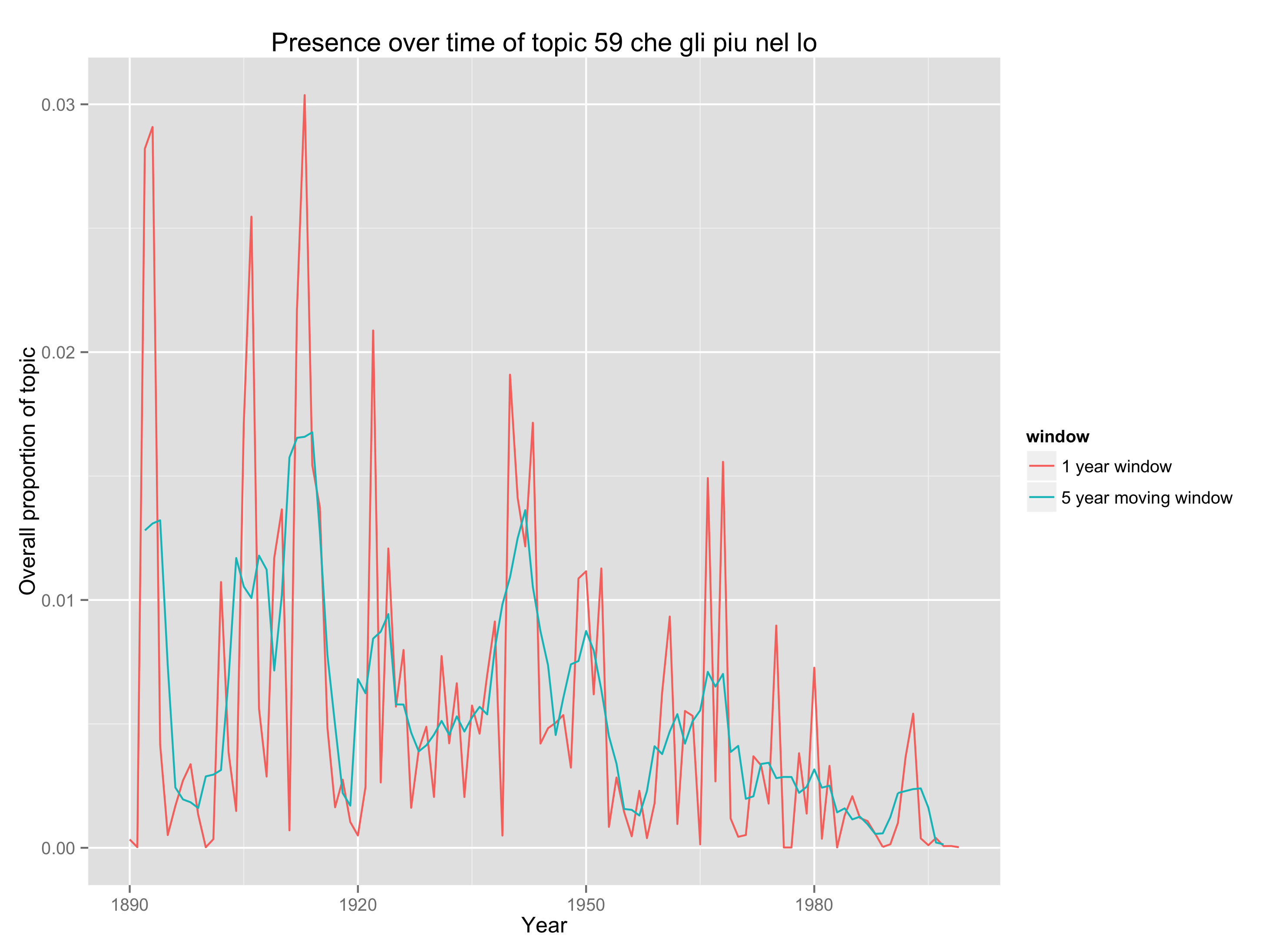 We see something about PMLA that is worth remembering for the history of criticism, namely, that it has embedded Italian less and less frequently in its language since midcentury. (The model shows that the same thing is true of French and German.)
We see something about PMLA that is worth remembering for the history of criticism, namely, that it has embedded Italian less and less frequently in its language since midcentury. (The model shows that the same thing is true of French and German.)
What can topics tell us about the history of theory?
Of course a topic can also be a subject category—modeling PMLA, we have found topics that are primarily “about Beowulf” or “about music.” Or a topic can be a group of words that tend to co-occur because they’re associated with a particular critical approach.
Here, for instance, we have a topic from Underwood’s 150-topic model associated with discussions of pattern and structure in literature. We can characterize it by listing words that occur more commonly in the topic than elsewhere, or by graphing the frequency of the topic over time, or by listing a few articles where it’s especially salient.
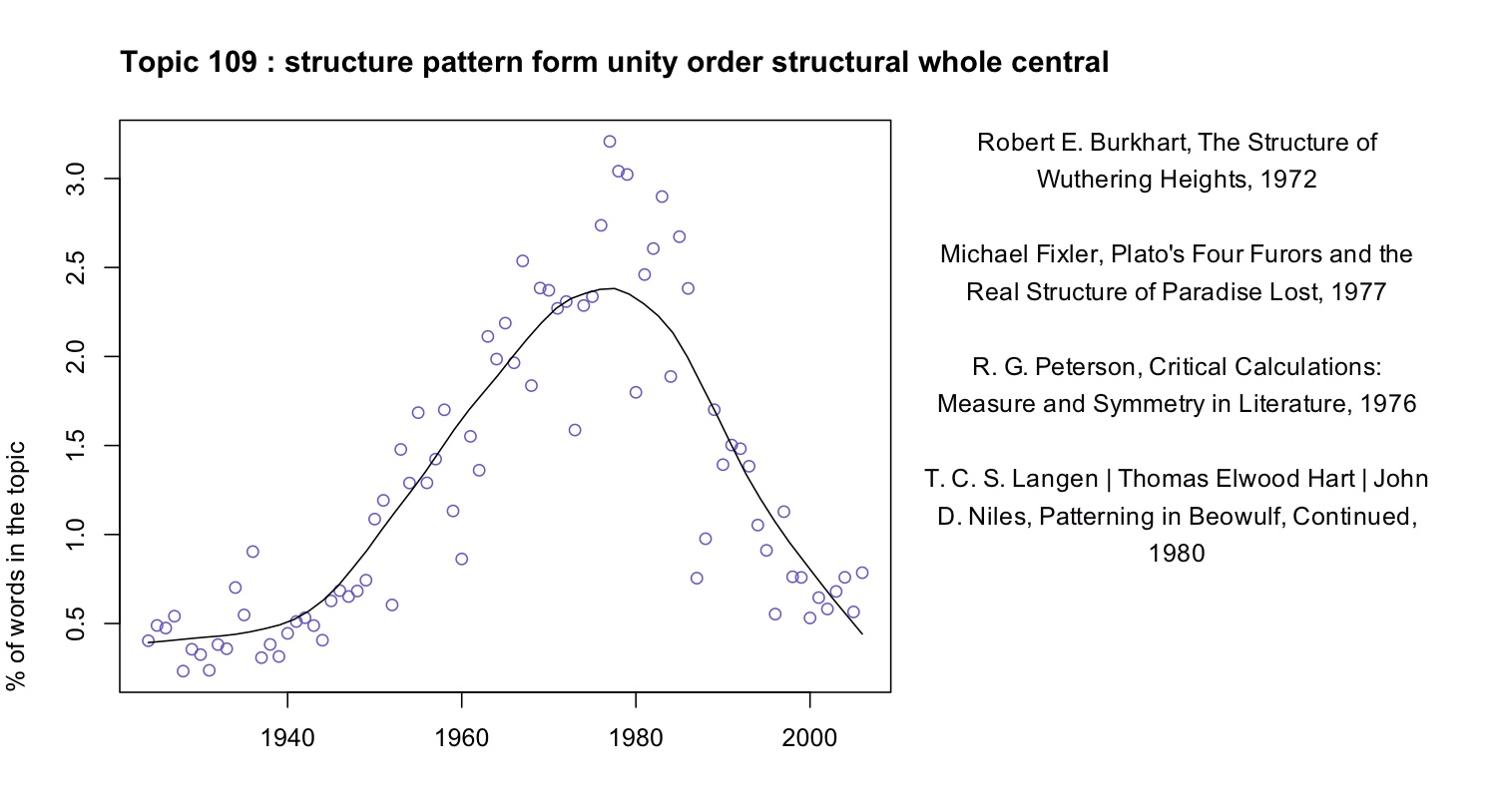
At first glance this topic might seem to fit neatly into a familiar story about critical history. We know that there was a mid-twentieth-century critical movement called “structuralism,” and the prominence of “structure” here might suggest that we’re looking at the rise and fall of that movement. In part, perhaps, we are. But the articles where this topic is most prominent are not specifically “structuralist.” In the top four articles, Ferdinand de Saussure, Claude Lévi-Strauss, and Northrop Frye are nowhere in evidence. Instead these articles appeal to general notions of symmetry, or connect literary patterns to Neoplatonism and Renaissance numerology.
By forcing us to attend to concrete linguistic practice, topic modeling gives us a chance to bracket our received assumptions about the connections between concepts. While there is a distinct mid-century vogue for structure, it does not seem strongly associated with the concepts that are supposed to have motivated it (myth, kinship, language, archetype). And it begins in the 1940s, a decade or more before “structuralism” is supposed to have become widespread in literary studies. We might be tempted to characterize the earlier part of this trend as “New Critical interest in formal unity” and the latter part of it as “structuralism.” But the dividing line between those rationales for emphasizing pattern is not evident in critical vocabulary (at least not at this scale of analysis).
This evidence doesn’t necessarily disprove theses about the history of structuralism. Topic modeling might not reveal varying “rationales” for using a word even if those rationales did vary. The strictly linguistic character of this technique is a limitation as well as a strength: it’s not designed to reveal motivation or conflict. But since our histories of criticism are already very intellectual and agonistic, foregrounding the conscious beliefs of contending critical “schools,” topic modeling may offer a useful corrective. This technique can reveal shifts of emphasis that are more gradual and less conscious than the ones we tend to celebrate.
It may even reveal shifts of emphasis of which we were entirely unaware. “Structure” is a familiar critical theme, but what are we to make of this?
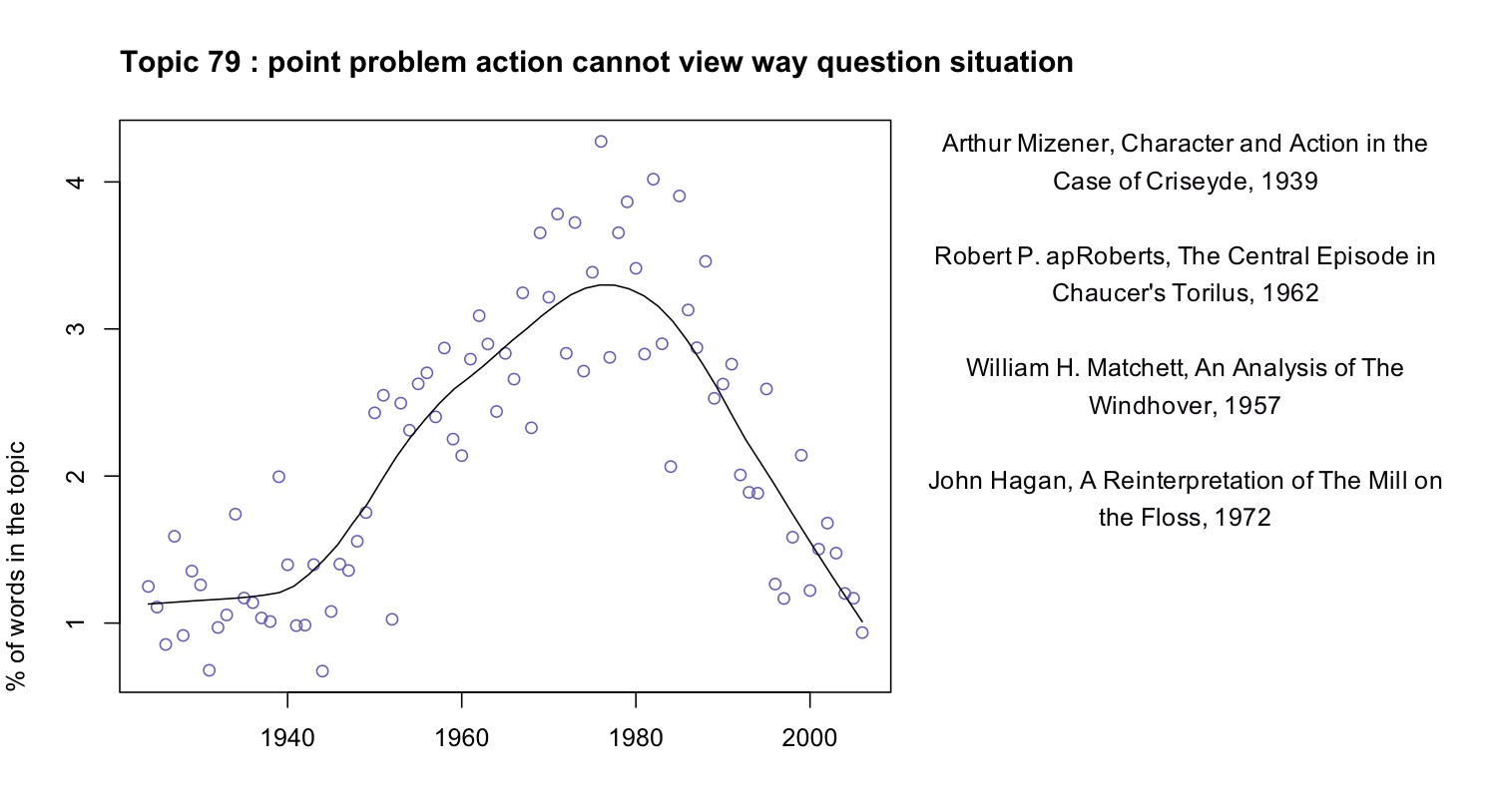 A fuller list of terms included in this topic would include “character”, “fact,” “choice,” “effect,” and “conflict.” Reading some of the articles where the topic is prominent, it appears that in this topic “point” is rarely the sort of point one makes in an argument. Instead it’s a moment in a literary work (e.g., “at the point where the rain occurs,” in Robert apRoberts 379). Apparently, critics in the 1960s developed a habit of describing literature in terms of problems, questions, and significant moments of action or choice; the habit intensified through the early 1980s and then declined. This habit may not have a name; it may not line up neatly with any recognizable school of thought. But it’s a fact about critical history worth knowing.
A fuller list of terms included in this topic would include “character”, “fact,” “choice,” “effect,” and “conflict.” Reading some of the articles where the topic is prominent, it appears that in this topic “point” is rarely the sort of point one makes in an argument. Instead it’s a moment in a literary work (e.g., “at the point where the rain occurs,” in Robert apRoberts 379). Apparently, critics in the 1960s developed a habit of describing literature in terms of problems, questions, and significant moments of action or choice; the habit intensified through the early 1980s and then declined. This habit may not have a name; it may not line up neatly with any recognizable school of thought. But it’s a fact about critical history worth knowing.
Note that this concern with problem-situations is embodied in common words like “way” and “cannot” as well as more legible, abstract terms. Since common words are often difficult to interpret, it can be tempting to exclude them from the modeling process. It’s true that a word like “the” isn’t likely to reveal much. But subtle, interesting rhetorical habits can be encoded in common words. (E.g. “itself” is especially common in late-20c theoretical topics.)
We don’t imagine that this brief blog post has significantly contributed to the history of criticism. But we do want to suggest that topic modeling could be a useful resource for that project. It has the potential to reveal shifts in critical vocabulary that aren’t well described, and that don’t fit our received assumptions about the history of the discipline.
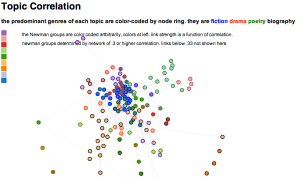
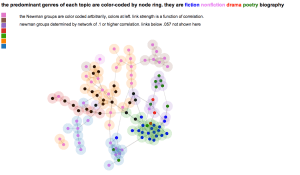
Why browse topics as a network?
The fact that a word is prominent in topic A doesn’t prevent it from also being prominent in topic B. So certain generalizations we might make about an individual topic (for instance, that Italian words decline in frequency after midcentury) will be true only if there’s not some other “Italian” topic out there, picking up where the first one left off.
For that reason, interpreters really need to survey a topic model as a whole, instead of considering single topics in isolation. But how can you browse a whole topic model? We’ve chosen relatively small numbers of topics, but it would not be unreasonable to divide literary scholarship into, say, 500 topics. Information overload becomes a problem.
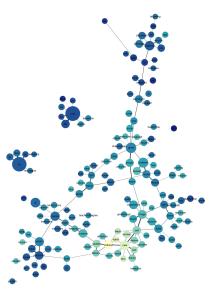
The structure of the network makes a loose kind of sense. Topics in French and German form separate networks floating free of the main English structure. Recent topics tend to cluster at the bottom of the page. And at the bottom, historical and pedagogical topics tend to be on the left, while formal, phenomenological, and aesthetic categories tend to be on the right.
But while it’s a little eerie to see patterns like this emerge automatically, we don’t advise readers to take the network structure too seriously. A topic model isn’t a network, and mapping one onto a network can be misleading. For instance, topics that are physically distant from each other in this visualization are not necessarily unrelated. Connections below a certain threshold go unrepresented.

How did our models differ?
The two models we’ve examined so far in this post differ in several ways at once. They’re based on different spans of PMLA‘s print run (1890–1999 and 1924–2006). They were produced with different software. Perhaps most importantly, we chose different numbers of topics (100 and 150).
But the models we’re presenting are only samples. Goldstone and Underwood each produced several models of PMLA, changing one variable at a time, and we have made some closer apples-to-apples comparisons.
Broadly, the conclusion we’ve reached is that there’s both a great deal of fluidity and a great deal of consistency in this process. The algorithm has to estimate parameters that are impossible to calculate exactly. So the results you get will be slightly different every time. If you run the algorithm on the same corpus with the same number of topics, the changes tend to be fairly minor. But if you change the number of topics, you can get results that look substantially different.
On the other hand, to say that two models “look substantially different” isn’t to say that they’re incompatible. A jigsaw puzzle cut into 100 pieces looks different from one with 150 pieces. If you examine them piece by piece, no two pieces are the same—but once you put them together you’re looking at the same picture. In practice, there was a lot of overlap between our models; on the older end of the spectrum you often see a topic like “evidence fact,” while the newer end includes topics that foreground narrative, rhetoric, and gender. Some of the more surprising details turned out to be consistent as well. For instance, you might expect the topic “literary literature” to skew toward the older end of the print run. But in fact this is a relatively recent topic in both of our models, associated with discussion of canonicity. (Perhaps the owl of Minerva flies only at dusk?)
Contrasting models: a short example
While some topics look roughly the same in all of our models, it’s not always possible to identify close correlates of that sort. As you vary the overall number of topics, some topics seem to simply disappear. Where do they go? For example, there is no exact counterpart in Goldstone’s model to that “structure” topic in Underwood’s model. Does that mean it is a figment? Underwood isolated the following article as the most prominent exemplar:
Robert E. Burkhart, The Structure of Wuthering Heights, Letter to the Editor, PMLA 87 no. 1 (1972): 104–5. (Incidentally, jstor has miscategorized this as a “full-length article.”)
Goldstone’s model puts more than half of Burkhart’s comment in three topics:
0.24 topic 38 time experience reality work sense form present point world human process structure concept individual reader meaning order real relationship
0.13 topic 46 novels fiction poe gothic cooper characters richardson romance narrator story novelist reader plot novelists character reade hero heroine drf
0.12 topic 13 point reader question interpretation meaning make reading view sense argument words word problem makes evidence read clear text readers
The other prominent documents in Underwood’s 109 are connected to similar topics in Goldstone’s model. The keywords for Goldstone’s topic 38, the top topic here, immediately suggest an affinity with Underwood’s topic 109. Now compare the time course of Goldstone’s 38 with Underwood’s 109 (the latter is above):

It is reasonable to infer that some portion of the words in Underwood’s “structure” topic are absorbed in Goldstone’s “time experience” topic. But “time experience reality work sense” looks less like vocabulary for describing form (although “form” and “structure” are included in it, further down the list; cf. the top words for all 100 topics), and more like vocabulary for talking about experience in generalized ways—as is also suggested by the titles of some articles in which that topic is substantially present:
“The Vanishing Subject: Empirical Psychology and the Modern Novel”
“Metacommentary”
“Toward a Modern Humanism”
“Wordsworth’s Inscrutable Workmanship and the Emblems of Reality”
This version of the topic is no less “right” or “wrong” than the one in Underwood’s model. They both reveal the same underlying evidence of word use, segmented in different but overlapping ways. Instead of focusing our vision on affinities between “form” and “structure”, Goldstone’s 100-topic model shows a broader connection between the critical vocabulary of form and structure and the keywords of “humanistic” reflection on experience.
The most striking contrast to these postwar themes is provided by a topic which dominates in the prewar period, then gives way before “time experience” takes hold. Here are box plots by ten-year intervals of the proportions of another topic, Goldstone’s topic 40, in PMLA articles:

Underwood’s model shows a similar cluster of topics centering on questions of evidence and textual documentation, which similarly decrease in frequency. The language of PMLA has shown a consistently declining interest in “evidence found fact” in the era of the postwar research university.
So any given topic model of a corpus is not definitive. Each variation in the modeling parameters can produce a new model. But although topic models vary, models of the same corpus remain fundamentally consistent with each other.
Using LDA as evidence
It’s true that a “topic model” is simply a model of how often words occur together in a corpus. But information of that kind has a deeper significance than we might at first assume. A topic model doesn’t just show you what people are writing about (a list of “topics” in our ordinary sense of the word). It can also show you how they’re writing. And that “how” seems to us a strong clue to social affinities—perhaps especially for scholars, who often identify with a methodology or critical vocabulary. To put this another way, topic modeling can identify discourses as well as subject categories and embedded languages. Naturally we also need other kinds of evidence to produce a history of the discipline, including social and institutional evidence that may not be fully manifest in discourse. But the evidence of topic modeling should be taken seriously.
As you change the number of topics (and other parameters), models provide different pictures of the same underlying collection. But this doesn’t mean that topic modeling is an indeterminate process, unreliable as evidence. All of those pictures will be valid. They are taken (so to speak) at different distances, and with different levels of granularity. But they’re all pictures of the same evidence and are by definition compatible. Different models may support different interpretations of the evidence, but not interpretations that absolutely conflict. Instead the multiplicity of models presents us with a familiar choice between “lumping” or “splitting” cultural phenomena—a choice where we have long known that multiple levels of analysis can coexist. This multiplicity of perspective should be understood as a strength rather than a limitation of the technique; it is part of the reason why an analysis using topic modeling can afford a richly detailed picture of an archive like PMLA.
Appendix: How did we actually do this?
The PMLA data obtained from JSTOR was independently processed by Goldstone and Underwood for their different LDA tools. This created some quantitative subtleties that we’ve saved for this appendix to keep this post accessible to a broad audience. If you read closely, you’ll notice that we sometimes talk about the “probability” of a term in a topic, and sometimes about its “salience.” Goldstone used MALLET for topic modeling, whereas Underwood used his own Java implementation of LDA. As a result, we also used slightly different formulas for ranking words within a topic. MALLET reports the raw probability of terms in each topic, whereas Underwood’s code uses a slightly more complex formula for term salience drawn from Blei & Lafferty (2009). In practice, this did not make a huge difference.
MALLET also has a “hyperparameter optimization” option which Goldstone’s 100-topic model above made use of. Before you run screaming, “hyperparameters” are just dials that control how much fuzziness is allowed in a topic’s distribution across words (beta) or across documents (alpha). Allowing alpha to vary allows greater differentiation between the sizes of large topics (often with common words), and smaller (often more specialized) topics. (See “Why Priors Matter,” Wallach, Mimno, and McCallum, 2009.) In any event, Goldstone’s 100-topic model used hyperparameter optimization; Underwood’s 150-topic model did not. A comparison with several other models suggests that the difference between symmetric and asymmetric (optimized) alpha parameters explains much of the difference between their structures when visualized as networks.
Goldstone’s processing scripts are online in a github repository. The same repository includes R code for making the plots from Goldstone’s model. Goldstone would also like to thank Bob Gerdes of Rutgers’s Office of Instructional and Research Technology for support for running mallet on the university’s apps.rutgers.edu server, Ben Schmidt for helpful comments at a THATCamp Theory session, and Jon Goodwin for discussion and his excellent blog posts on topic-modeling jstor data.
Underwood’s network graphs were produced by measuring Pearson correlations between topic distributions (across documents) and then selecting the strongest correlations as network edges using an algorithm Underwood has described previously. That data structure was sent to Gephi. Underwood’s Java implementation of LDA, as well as his PMLA model, and code for translating a model into a network, are on github, although at this point he can’t promise a plug-and-play workflow. Underwood would like to thank Matt Jockers for convincing him to try topic modeling (see Matt’s impressive, detailed model of the nineteenth-century novel) and Michael Simeone for convincing him to try force-directed network graphs. David Mimno kindly answered some questions about the innards of MALLET.
[Cross-posted: andrewgoldstone.com, Arcade (to appear).]
[Edit (AG) 12/12/16: 10×10 grid image now with topics in numerical order. Original version still available: overview.png.]












{kind=link}