A transcript of these remarks was sent back via time machine to the Novel Theory conference at Ithaca in 2018, where a panel had been asked to envision what literary studies would look like if data analysis came to be understood as a normal part of the discipline.
I want to congratulate the organizers on their timeliness; 2028 is the perfect time for this retrospective. Even ten years ago I think few of us could have imagined that quantitative methods would become as uncontroversial in literary studies as they are today. (I, myself, might not have believed it.)
But the emergence of a data science option in the undergrad major changed a lot. It is true that the option only exists at a few schools, and most undergrads don’t opt for it. But it has made a few students confident enough to explore further. Today, almost 10% of dissertations in literary studies use numbers in some way.
A tenth of the field is not huge, but even that small foothold has had catalytic effects. One obvious effect has been to give literary studies a warm-water port in the social sciences. Without data science, I’m not sure we would be having the vigorous conversations we’re having today with sociologists, legal scholars, and historians of social media. Increasingly, our fields are bound together by a shared concern with large-scale textual interpretation. That shared conversation, in turn, invites journalists to give literary arguments a different kind of attention. There are examples everywhere. But since we’re all reading it, let me just point to today’s article in The Guardian on the Trump Prison Diaries—which couldn’t have been written ten years ago, for several obvious reasons.
But data analysis has also led to less obvious changes. I think even the recent, widely-discussed return to evaluative criticism—the so-called “new belletrism”—may have had something to do with data.
The conference venue, easily reached by water taxi.
I know this will seem unlikely. These are usually presented as opposing currents in the contemporary scene—one artsy, one mathy; one tending to focus on contemporary literature, the other on the longue durée. But I would argue that quantitative methods have made it easier to treat aesthetic arguments as scholarly questions.
It used to be difficult, after all, to reconcile evaluation with historicism. If you disavowed timeless aesthetic judgments, then it seemed you could only do historical reportage on the peculiar opinions of the 1820s or the 1920s.
Work on the history of reception has created an expansive middle ground between those poles—a way to study judgments that do change, but change in practice very slowly, across century-spanning arcs. Those arcs became visible when we backed up to a distance, but in a sense we can’t get historical distance from them; they sprawl into the present and can’t be relegated to the past. So historical scholars and contemporary critics are increasingly forced onto each other’s turf. Witness the fireworks lately between MFA programs and distant readers arguing that the recent history of the novel is really driven by genre fiction.
Most of these fireworks, I think, are healthy. But there have also been downsides. Ten years ago, none of us imagined that divisions within the data science community could become as deep or bitter as they are today. In a general sense data may be uncontroversial: many literary scholars use, say, a table of sales figures. But machine learning is more controversial than ever.
Ironically, it is often the people most enthusiastic about other forms of data who are rejecting machine learning. And I have to admit they have a point when they call it “subjective.”
It is notoriously true, after all, that learning algorithms absorb the biases implicit in the evidence you give them. So in choosing evidence for our models we are, in a sense, choosing a historical vantage point. Some people see this as appropriate for an interpretive discipline. “We have always known that interpretation was circular,” they say, “and it’s healthy to acknowledge that our inferences start from a situated perspective” (Rosencrantz, 2025). Other people worry that the subjectivity of machine learning is troubling, because it “hides inside a black box” (Guildenstern, 2027). I don’t think the debate is going away soon; I fear literary theorists will still be arguing about it when we meet again in 2038.
I’m not being snarky. Right now, I have several friends writing articles that are largely or partly a critique of interrelated trends that go under the names “data” or “distant reading.” It looks like many other articles of the same kind are being written.
This is good news! I believe fervently in Mae West’s theory of publicity. “I don’t care what the newspapers say about me as long as they spell my name right.” (Though it turns out we may not actually know who said that, so I guess the newspapers failed.)
But I do want to help you “spell our names right.” Andrew Piper has recently pointed out that critiques of data-driven research tend to use a small sample of articles. He expressed that more strongly, but I happen to like the article he was aiming at, so I’m going to soften his expression. However, I don’t disagree with the underlying point! For some reason, critics of numbers don’t feel they need to consider more than one example, or two if they’re in a generous mood.
There are some admirable exceptions to this rule. I’ve argued that a recent issue of Genre was, in general, moving in the right direction. And I’m fairly confident that the trend will continue. A field that has been generating mostly articles and pamphlets is about to shift into a lower gear and publish several books. In literary studies, that tends to be an effective way of reframing debate.
But it may be another twelve to eighteen months before those books are out. In the meantime, you’ve got to finish your critique. So let me help with the bibliography.
When you’re tempted to assume that all possible uses of numbers (or “data”) in literary study can be summed up by engaging one or two texts that Franco Moretti wrote in the year 2000, you should resist the assumption. You are actually talking about a long, complex story, and your readers deserve some glimpse of its complexity.
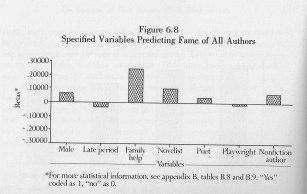
For instance, sociologists,linguists and book historians have been using numbers to describe literature since the middle of the twentieth century. You should make clear whether you are critiquing that work, or just arguing that it is incapable of addressing the inner literariness of literature. The journal Computers and the Humanities started in the 1960s. The 1980s gave rise to a thriving tradition of feminist literary sociology, embodied in books by Janice Radway and Gaye Tuchman, and in the journal Signs. I’ve used one of Tuchman’s regression models as an illustration here.
Variables predicting literary fame in a regression model, from Gaye Tuchman and Nina E. Fortin, Edging Women Out (1989).
<deep breath>
In the 1990s, Mark Olsen (working at the University of Chicago) started to articulate many of the impulses we now call “distant reading.” Around 2000, Franco Moretti gave quantitative approaches an infusion of polemical verve and wit, which raised their profile among literary scholars who had not previously paid attention. (Also, frankly, the fact that Moretti already had disciplinary authority to spend mattered a great deal. Literary scholars can be temperamentally conservative even when theoretically radical.)
But Moretti himself is a moving target. The articles he has written since 2008 aim at different goals, and use different methods, than articles before that date. Part of the point of an experimental method, after all, is that you are forced to revise your assumptions! Because we are actually learning things, this field is changing rapidly. A recent pamphlet from the Stanford Literary Lab conceives the role of the “archive,” for instance, very differently than “Slaughterhouse of Literature” did.
But that pamphlet was written by six authors—a useful reminder that this is a collective project. Today the phrase “distant reading” is often a loose description for large-scale literary history, covering many people who disagree significantly with Moretti. In a recent roundtable in PMLA, for instance, Andrew Goldstone argues for evidence of a more sociological and less linguistic kind. Lisa Rhody and Alison Booth both argue for different scales or forms of “distance.” Richard Jean So argues that the simple measurements which typified much work before 2010 need to be replaced by statistical models, which account for variation and uncertainty in a more principled way.
Not all of these scholars believe that numbers will put literary scholarship on a more objective footing. Few of them believe that numbers can replace “interpretation” with “explanation.” None of them, as far as I can tell, have stopped doing close reading. (I would even claim to pair numbers with close reading in Joseph North’s strong sense of the phrase: not just reading-to-illustrate-a-point but reading-for-aesthetic-cultivation.) In short, the work literary scholars are doing with numbers is not easily unified by a shared set of principles—and definitely isn’t unified by a 17-year-old polemic. The field is unified, rather, by a fast-moving theoretical debate. Literary production versus circulation. Book history versus social science. Sociology versus linguistics. Measurement versus modeling. Interpretation versus explanation versus prediction.
Critics of this work may want to argue that it all nevertheless fails in the same way, because numbers inevitably (flatten time/reduce reading to visualization/exclude subjectivity/fill in the blank). That’s a fair thesis to pursue. But if you believe that, you need to show that your generalization is true by considering several different (recent!) examples, and teasing out the tacit similarities concealed underneath ostensible disagreements. I hope this post has helped with some of the bibliographic legwork. If you want more sources, I recently wrote a “Genealogy of Distant Reading” that will provide more. Now, tear them apart!
A school of yellow-tailed goat fish. CC-BY Dwayne Meadows, 2004.
I think I see an interesting theoretical debate over the horizon. The debate is too big to resolve in a blog post, but I thought it might be narratively useful to foreshadow it—sort of as novelists create suspense by dropping hints about the character traits that will develop into conflict by the end of the book.
Basically, the problem is that scholars who use numbers to understand literary history have moved on from Stanley Fish’s critique, without much agreement about why or how. In the early 1970s, Fish gave a talk at the English Institute that defined a crucial problem for linguistic analysis of literature. Later published as “What Is Stylistics, and Why are They Saying Such Terrible Things About It?”, the essay focused on “the absence of any constraint” governing the move “from description to interpretation.” Fish takes Louis Milic’s discussion of Jonathan Swift’s “habit of piling up words in series” as an example. Having demonstrated that Swift does this, Milic concludes that the habit “argues a fertile and well stocked mind.” But Fish asks how we can make that sort of inference, generally, about any linguistic pattern. How do we know that reliance on series demonstrates a “well stocked mind” rather than, say, “an anal-retentive personality”?
The problem is that isolating linguistic details for analysis also removes them from the context we normally use to give them a literary interpretation. We know what the exclamation “Sad!” implies, when we see it at the end of a Trumpian tweet. But if you tell me abstractly that writer A used “sad” more than writer B, I can’t necessarily tell you what it implies about either writer. If I try to find an answer by squinting at word lists, I’ll often make up something arbitrary. Word lists aren’t self-interpreting.
Thirty years passed; the internet got invented. In the excitement, dusty critiques from the 1970s got buried. But Fish’s argument was never actually killed, and if you listen to the squeaks of bats, you hear rumors that it still walks at night.
Or you could listen to blogs. This post is partly prompted by a blogged excerpt from a forthcoming work by Dennis Tenen, which quotes Fish to warn contemporary digital humanists that “a relation can always be found between any number of low-level, formal features of a text and a given high-level account of its meaning.” Without “explanatory frameworks,” we won’t know which of those relations are meaningful.
Ryan Cordell’s recent reflections on “machine objectivity” could lead us in a similar direction. At least they lead me in that direction, because I think the error Cordell discusses—over-reliance on machines themselves to ground analysis—often comes from a misguided attempt to solve the problem of arbitrariness exposed by Fish. Researchers are attracted to unsupervised methods like topic modeling in part because those methods seem to generate analytic categories that are entirely untainted by arbitrary human choices. But as Fish explained, you can’t escape making choices. (Should I label this topic “sadness” or “Presidential put-downs”?)
I don’t think any of these dilemmas are unresolvable. Although Fish’s critique identified a real problem, there are lots of valid solutions to it, and today I think most published research is solving the problem reasonably well. But how? Did something happen since the 1970s that made a difference? There are different opinions here, and the issues at stake are complex enough that it could take decades of conversation to work through them. Here I just want to sketch a few directions the conversation could go.
Dennis Tenen’s recent post implies that the underlying problem is that our models of form lack causal, explanatory force. “We must not mistake mere extrapolation for an account of deep causes and effects.” I don’t think he takes this conclusion quite to the point of arguing that predictive models should be avoided, but he definitely wants to recommend that mere prediction should be supplemented by explanatory inference. And to that extent, I agree—although, as I’ll say in a moment, I have a different diagnosis of the underlying problem.
It may also be worth reviewing Fish’s solution to his own dilemma in “What Is Stylistics,” which was that interpretive arguments need to be anchored in specific “interpretive acts” (93). That has always been a good idea. David Robinson’s analysis of Trump tweets identifies certain words (“badly,” “crazy”) as signs that a tweet was written by Trump, and others (“tomorrow,” “join”) as signs that it was written by his staff. But he also quotes whole tweets, so you can see how words are used in context, make your own interpretive judgment, and come to a better understanding of the model. There are many similar gestures in Stanford LitLab pamphlets: distant readers actually rely quite heavily on close reading.
My understanding of this problem has been shaped by a slightly later Fish essay, “Interpreting the Variorum” (1976), which returns to the problem broached in “What Is Stylistics,” but resolves it in a more social way. Fish concludes that interpretation is anchored not just in an individual reader’s acts of interpretation, but in “interpretive communities.” Here, I suspect, he is rediscovering an older hermeneutic insight, which is that human acts acquire meaning from the context of human history itself. So the interpretation of culture inevitably has a circular character.
One lesson I draw is simply, that we shouldn’t work too hard to avoid making assumptions. Most of the time we do a decent job of connecting meaning to an implicit or explicit interpretive community. Pointing to examples, using word lists derived from a historical thesaurus or sentiment dictionary—all of that can work well enough. The really dubious moves we make often come from trying to escape circularity altogether, in order to achieve what Alan Liu has called “tabula rasa interpretation.”
Of course, if you pursue that approach systematically enough, it will lead you away from topic modeling toward methods that rely more explicitly on human judgment. I have been leaning on supervised algorithms a lot lately—not because they’re easier to test or more reliable than unsupervised ones—but because they explicitly acknowledge that interpretation has to be anchored in human history.
At a first glance, this may seem to make progress impossible. “All we can ever discover is which books resemble these other books selected by a particular group of readers. The algorithm can only reproduce a category someone else already defined!” And yes, supervised modeling is circular. But this is a circularity shared by all interpretation of history, and it never merely reproduces its starting point. You can discover that books resemble each other to different degrees. You can discover that models defined by the responses of one interpretive community do or don’t align with models of another. And often you can, carefully, provisionally, draw explanatory inferences from the model itself, assisted perhaps by a bit of close reading.
I’m not trying to diss unsupervised methods here. Actually, unsupervised methods are based on clear, principled assumptions. And a topic model is already a lot more contextually grounded than “use of series == well stocked mind.” I’m just saying that the hermeneutic circle is a little slipperier in unsupervised learning, easier to misunderstand, and harder to defend to crowds of pitchfork-wielding skeptics.
In short, there are lots of good responses to Fish’s critique. But if that critique is going to be revived by skeptics over the next few years—as I suspect—I think I’ll take my stand for the moment on supervised machine learning, which can explicitly build bridges between details of literary language and social contexts of reception. There are other ways to describe best practices: we could emphasize a need to seek “explanations,” or avoid claims of “objectivity.” But I think the crucial advance we have made over the 1970s is that we’re no longer just modeling language; we can model interpretive communities at the same time.
Photo credit: A school of yellow-tailed goatfish, photo for NOAA Photo Library, CC-BY Dwayne Meadows, 2004.
Five years ago it was easy to check on new digital subfields of the humanities. Just open Twitter. If a new blog post had dropped, or a magazine had published a fresh denunciation of “digital humanities,” academics would be buzzing.
In 2017, Stanley Fish and Leon Wieseltier are no longer attacking “DH” — and if they did, people might not care. Twitter, unfortunately, has bigger problems to worry about, because the Anglo-American political world has seen some changes for the worse.
But the world of digital humanities, I think, has seen changes for the better. It seems increasingly taken for granted that digital media and computational methods can play a role in the humanities. Perhaps a small role — and a controversial one — and one without much curricular support. But still!
In place of journalistic controversies and flame wars, we are finally getting a broad scholarly conversation about new ideas. Conversations of this kind take time to develop. Many of us will recall Twitter threads from 2013 anxiously wondering whether digital scholarship would ever have an impact on more “mainstream” disciplinary venues. The answer “it just takes time” wasn’t, in 2013, very convincing.
But in fact, it just took time. Quantitative methods and macroscopic evidence, for instance, are now a central subject of debate in literary studies. (Since flame wars may not be entirely over, I should acknowledge that I’m now moving to talk about one small subfield of DH rather than trying to do justice to the whole thing.)
The participants in this conversation don’t all identify as digital humanists or distant readers. But they are generally open-minded scholars willing to engage ideas as ideas, whatever their disciplinary origin. Some are still deeply suspicious of numbers, but they are willing to consider both sides of that question. Many recent essays are refreshingly aware that quantitative analysis is itself a mode of interpretation, guided by explicit reflection on interpretive theory. Instead of reifying computation as a “tool” or “skill,” for instance, Robert Mitchell engages the intellectual history of Bayesian statistics in Genre.
Recent essays also seem aware that the history of large-scale quantitative approaches to the literary past didn’t begin and end with Franco Moretti. References to book history and the Annales School mix with citations of Tanya Clement and Andrew Piper. Although I admire Moretti’s work, this expansion of the conversation is welcome and overdue.
If “data” were a theme — like thing theory or the Anthropocene — this play might now have reached its happy ending. Getting literary scholars to talk about a theme is normally enough.
In fact, the play could proceed for several more acts, because “data” is shorthand for a range of interpretive practices that aren’t yet naturalized in the humanities. At most universities, grad students still can’t learn how to do distant reading. So there is no chance at all that distant reading will become the “next big thing” — one of those fashions that sweeps departments of English, changing everyone’s writing in a way that is soon taken for granted. We can stop worrying about that. Adding citations to Geertz and Foucault can be done in a month. But a method that requires years of retraining will never become the next big thing. Maybe, ten years from now, the fraction of humanities faculty who actually use quantitative methods may have risen to 5% — or optimistically, 7%. But even that change would be slow and deeply controversial.
So we might as well enjoy the current situation. The initial wave of utopian promises and enraged jeremiads about “DH” seems to have receded. Scholars have realized that new objects, and methods, of study are here to stay — and that they are in no danger of taking over. Now it’s just a matter of doing the work. That, also, takes time.
Accounts of the history of the humanities are being strongly shaped, right now, by stances for or against something called “digital humanities.” I have to admit I avoid the phrase when I can. The good thing about DH is, it creates a lively community that crosses disciplinary lines to exchange ideas. The bad thing is, it also creates a community that crosses disciplinary lines to fight pointlessly over the meaning of “digital humanities.” Egyptologists and scholars of game studies, who once got along just fine doing different things, suddenly understand themselves as advancing competing, incompatible versions of DH.
The desire to defend a coherent tradition called DH can also lead to models of intellectual history that I find bizarre. Sometimes, for instance, people trace all literary inquiry using computers back to Roberto Busa. That seems to me an oddly motivated genealogy: it would only make sense if you thought the physical computers themselves were very important. I tend to trace the things people are doing instead to Janice Radway, Roman Jakobson, Raymond Williams, or David Blei.
On the other hand, we’ve recently seen that a desire to take a stand against digital humanities can lead to equally unpersuasive genealogies. I’m referring to a recent critique of digital humanities in LARB by Daniel Allington, Sarah Brouillette, and David Golumbia. The central purpose of the piece is to identify digital humanities as a neoliberal threat to the humanities.
I’m not going to argue about whether digital humanities is neoliberal; I’ve already said that I fear the term is becoming a source of pointless fights. So I’m not the person to defend the phrase, or condemn it. But I do care about properly crediting people who contributed to the tradition of literary history I work in, and here I think the piece in LARB leads to important misunderstandings.
The argument is supported by two moves that I would call genealogical sleight-of-hand. On the one hand, it unifies a wide range of careers that might seem to have pursued different ends (from E. D. Hirsch to Rita Felski) by the crucial connecting link that all these people worked at the University of Virginia. On the other hand, it needs to separate various things that readers might associate with digital humanities, so if any intellectual advances happen to take place in some corner of a discipline, it can say “well, you know, that part wasn’t really related; it had a totally different origin.”
I don’t mean to imply that the authors are acting in bad faith here; nor do I think people who over-credit Roberto Busa for all literary work done with computers are motivated by bad faith. This is just an occupational hazard of doing history. If you belong to a particular group (a national identity, or a loose social network like “DH”), there’s always a danger of linking and splitting things so history becomes a story about “the rise of France.” The same thing can happen if you deeply dislike a group.
So, I take it as a sincere argument. But the article’s “splitting” impulses are factually mistaken in three ways. First, the article tries to crisply separate everything happening in distant reading from the East Coast — where people are generally tarnished (in the authors’ eyes) by association with UVA. Separating these traditions allows the article to conclude “well, Franco Moretti may be a Marxist, but the kind of literary history he’s pursuing had nothing to do with those editorial theory types.”
That’s just not true; the projects may be different, but there have also been strong personal and intellectual connections between them. At times, the connections have been embodied institutionally in the ADHO, but let me offer a more personal example: I wouldn’t be doing what I’m doing right now if it weren’t for the MONK project. Before I knew how to code — or, code in anything other than 1980s-era Basic — I spent hours playing with the naive Bayes feature in MONK online, discovering what it was capable of. For me, that was the gateway drug that led eventually to a deeper engagement with sociology of literature, book history, machine learning, and so on. MONK was created by a group centered at our Graduate School of Library and Information Science, but the dark truth is that several of those people had been trained at UVA (I know Unsworth, Ramsay, and Kirschenbaum were involved — pardon me if I’m forgetting others).
MONK is also an example of another way the article’s genealogy goes wrong: by trying to separate anything that might be achieved intellectually in a field like literary history from the mere “support functions for the humanities” provided by librarians and academic professionals. Just as a matter of historical fact, that’s not a correct account of how large-scale literary history has developed. My first experiment with quantitative methods — before MONK — took shape back in 1995, when my first published article, in Studies in Romanticism (1995). used quantitative methods influenced by Mark Olsen, a figure who deserves a lot more credit than he has received. Olsen had already sketched out the theoretical rationale for a research program you might call “distant reading” in 1989, arguing that text analysis would only really become useful for the humanities when it stopped trying to produce readings of individual books and engaged broad social-historical questions. But Olsen was not a literature professor. He had a Ph.D in French history, and was working off the tenure track with a digital library called ARTFL at the University of Chicago.
Really at every step of the way — from ARTFL, to MONK, to the Stanford Literary Lab, to HathiTrust Research Center — my thinking about this field has been shaped by projects that were organized and led by people with appointments in libraries and/or in library science. You may like that, or feel that it’s troubling — up to you — but it’s the historical fact.
Personally, I take it as a sign that, in historical disciplines, libraries and archives really matter. A methodology, by itself, is not enough; you also need material, and the material needs to be organized in ways that are far from merely clerical. Metadata is a hard problem. The organization of the past is itself an interpretive act, and libraries are one of the institutional forms it takes. I might not have realized that ten years ago, but after struggling to keep my head above water in a sea of several million books, I feel it very sincerely.
This is why I think the article is also wrong to treat distant reading as a mere transplantation of social-science methods. I suspect the article has seen this part of disciplinary history mainly through the lens of Daniel Allington’s training in linguistics, so I credit it as a good-faith understanding: if you’re trained in social science, then I understand, large-scale literary history will probably look like sociology and linguistics that happen to have gotten mixed in some way and then applied to the past.
But the article is leaving out something that really matters in this field, which is turning methods into historical arguments. To turn social-scientific methods into literary history, you have to connect the results of a model, meaningfully, to an existing conversation about the literary past. For that, you need a lot of things that aren’t contained in the original method. Historical scholarship. Critical insight, dramatized by lively writing. And also metadata. Authors’ dates of birth and death; testimony about perceived genre categories. A corpus isn’t enough. Social-scientific methods can only become literary history in collaboration with libraries.
I know nothing I have said here will really address the passions evoked on multiple sides by the LARB article. I expect this post will be read by some as an attempt to defend digital humanities, and by others as a mealy-mouthed failure to do so. That’s okay. But from my own (limited) perspective, I’m just trying to write some history here, giving proper credit to people who were involved in building the institutions and ideas I rely on. Those people included social scientists, humanists, librarians, scholars in library and information science, and people working off the tenure track in humanities computing.
Postscript: On the importance of libraries, see Steven E. Jones, quoting Bethany Nowviskie about the catalytic effect of Google Books (Emergence 8, and “Resistance in the Materials”). Since metadata matters, Google Books became enormously more valuable to scholars in the form of HathiTrust. The institutional importance I attribute to libraries is related to Alan Liu’s recent observations about the importance of critically engaging infrastructure.
References
Jones, Steven E. The Emergence of the Digital Humanities. New York: Routledge, 2014.
Olsen, Mark. “The History of Meaning: Computational and Quantitative Methods in Intellectual History,” Joumal of History and Politics 6 (1989): 121-54.
As Jim English remarked in 2010, literary scholars have tended to use sociology “for its conclusions rather than its methods.” We might borrow a term like “habitus” from Bourdieu, but we weren’t interested in borrowing correspondence analysis. If we wanted to talk about methodology with social scientists at all, we were more likely to go to the linguists. (A connection to linguistics in fact almost defined “humanities computing.”)
Conveniently, several articles in Big Data and Society are trying to explain the reasons for growing methodological overlap between these disciplines. I think it’s interesting that the sociologists and literary scholars involved are telling largely the same story (though viewing it, perhaps, from opposite sides of a mirror).
First, the perspective of social scientists. In “Toward a computational hermeneutics,” John W. Mohr, Robin Wagner-Pacifici, and Ronald L. Breiger (who collectively edited this special issue of BDS) suggest that computational methods are facilitating a convergence between the social-scientific tradition of “content analysis” and kinds of close reading that have typically been more central to the humanities.
Close reading? Well, yes, relative to what was previously possible at scale. Content analysis was originally restricted to predefined keywords and phrases that captured the “manifest meaning of a textual corpus” (2). Other kinds of meaning, implicit in “complexities of phrasing” or “rhetorical forms,” had to be discarded to make text usable as data. But according to the authors, computational approaches to text analysis “give us the ability to instead consider a textual corpus in its full hermeneutic complexity,” going beyond the level of interpretation Kenneth Burke called “semantic” to one he considered “poetic” (3-4). This may be interpretation on a larger scale than literary scholars are accustomed to, but from the social-scientific side of the border, it looks like a move in our direction.
Jari Schroderus, “Through the Looking Glass,” 2006, CC BY-NC-ND 2.0.The essay I contributed to BDS tells a mirror image of this story. I think twentieth-century literary scholars were largely right to ignore quantitative methods. The problems that interested us weren’t easy to represent, for exactly the reason Mohr, Wagner-Pacifici, and Breiger note: the latent complexities of a text had to be discarded in order to treat it as structured data.
But that’s changing. We can pour loosely structured qualitative data into statistical models these days, and that advance basically blurs the boundary we have taken for granted between the quantitative social sciences and humanities. We can create statistical models now where loosely structured texts sit on one side of an equals sign, and evidence about social identity, prestige, or power sits on the other side.
For me, the point of that sort of model is to get beyond one of the frustrating limitations of “humanities computing,” which was that it tended to stall out at the level of linguistic detail. Before we could pose questions about literary form or social conflict, we believed we had to first agree on a stopword list, and a set of features, and a coding scheme, and … in short, if social questions can only be addressed after you solve all the linguistic ones, you never get to any social questions.
But (as I explain at more length in the essay) new approaches to statistical modeling are less finicky about linguistic detail than they used to be. Instead of fretting endlessly about feature selection and xml tags, we can move on to the social questions we want to pose — questions about literary prestige, or genre, or class, or race, or gender. Text can become to some extent a space where we trace social boundaries and study the relations between them.
In short, the long-standing (and still valuable) connection between digital literary scholarship and linguistics can finally be complemented by equally strong connections to other social sciences. I think those connections are going to have fruitful implications, beginning to become visible in this issue of Big Data and Society, and (just over the horizon) in work in progress sponsored by groups like NovelTM and the Chicago Text Lab.
A final question raised by this interdisciplinary conversation involves the notion of big data foregrounded in the journal title. For social scientists, “big data” has a fairly clear meaning — which has less to do with scale, really, than with new ways of gathering data without surveys. But of course surveys were never central to literary study, and it may be no accident that few of the literary scholars involved in this issue of BDS are stressing the bigness of big data. We’ve got terabytes of literature in digital libraries, and we’re using them. But we’re not necessarily making a fuss about “bigness” as such.
Rachel Buurma’s essay on topic-modeling Trollope’s Barsetshire novels explicitly makes a case for the value of topic-modeling at an intermediate scale — while, by the way, arguing persuasively that a topic model is best understood as an “uncanny, shifting, temporary index,” or “counter-factual map” (4). In my essay I discuss a collection of 720 books. That may sound biggish relative to what literary scholars ordinarily do, but it’s explicitly a sample rather than an attempt at coverage, and I argue against calling it big data.
There are a bunch of reasons for that. I’ve argued in the past that the term doesn’t have a clear meaning for humanists. But my stronger objection is that it distracts readers from more interesting things. It allows us to imagine that recent changes are just being driven by faster computers or bigger disks — and obscures underlying philosophical developments that would fascinate humanists if we knew about them.
[This is an updated version of a blog post I wrote three years ago, which organized introductory resources for a workshop. Getting ready for another workshop this summer, I glanced back at the old post and realized it’s out of date, because we’ve collectively covered a lot of ground in three years. Here’s an overhaul.]
Why are humanists using computers to understand text at all?
Part of the point of the phrase “digital humanities” is to claim information technology as something that belongs in the humanities — not an invader from some other field. And it’s true, humanistic interpretation has always had a technological dimension: we organized writing with commonplace books and concordances before we took up keyword search [Nowviskie, 2004; Stallybrass, 2007].
But framing new research opportunities as a specifically humanistic movement called “DH” has the downside of obscuring a bigger picture. Computational methods are transforming the social and natural sciences as much as the humanities, and they’re doing so partly by creating new conversations between disciplines. One of the main ways computers are changing the textual humanities is by mediating new connections to social science. The statistical models that help sociologists understand social stratification and social change haven’t in the past contributed much to the humanities, because it’s been difficult to connect quantitative models to the richer, looser sort of evidence provided by written documents. But that barrier is dissolving. As new methods make it easier to represent unstructured text in a statistical model, a lot of fascinating questions are opening up for social scientists and humanists alike [O’Connor et. al. 2011].
In short, computational analysis of text is not a specific new technology or a subfield of digital humanities; it’s a wide-open conversation in the space between several different disciplines. Humanists often approach this conversation hoping to find digital tools that will automate familiar tasks. That’s a good place to start: I’ll mention tools you could use to create a concordance or a word cloud. And it’s fair to stop there. More involved forms of text analysis do start to resemble social science, and humanists are under no obligation to dabble in social science.
But I should also warn you that digital tools are gateway drugs. This thing called “text analysis” or “distant reading” is really an interdisciplinary conversation about methods, and if you get drawn into the conversation, you may find that you want to try a lot of things that aren’t packaged yet as tools.
What can we actually do?
The image below is a map of a few things you might do with text (inspired by, though different from, Alan Liu’s map of “digital humanities”). The idea is to give you a loose sense of how different activities are related to different disciplinary traditions. We’ll start in the center, and spiral out; this is just a way to organize discussion, and isn’t necessarily meant to suggest a sequential work flow.
1) Visualize single texts.
Text analysis is sometimes represented as part of a “new modesty” in the humanities [Williams]. Generally, that’s a bizarre notion. Most of the methods described in this post aim to reveal patterns hidden from individual readers — not a particularly modest project. But there are a few forms of analysis that might count as surface readings, because they visualize textual patterns that are open to direct inspection.
A concordance also, in a sense, tells us nothing we couldn’t learn by reading on our own. But critics nevertheless find them useful. If you want to make a concordance for a single work (or for that matter a whole library), AntConc is a good tool.
2) Choose features to represent texts.
A scholar undertaking computational analysis of text needs to answer two questions. First, how are you going to represent texts? Second, what are you going to do with that representation once you’ve got it? Most what follows will focus on the second question, because there are a lot of equally good answers to the first one — and your answer to the first question doesn’t necessarily constrain what you do next.
In practice, texts are often represented simply by counting the various words they contain (they are treated as so-called “bags of words”). Because this representation of text is radically different from readers’ sequential experience of language, people tend to be surprised that it works. But the goal of computational analysis is not, after all, to reproduce the modes of understanding readers have already achieved. If we’re trying to reveal large-scale patterns that wouldn’t be evident in ordinary reading, it may not actually be necessary to retrace the syntactic patterns that organize readers’ understanding of specific passages. And it turns out that a lot of large-scale questions are registered at the level of word choice: authorship, theme, genre, intended audience, and so on. The popularity of Google’s Ngram Viewer shows that people often find word frequencies interesting in their own right.
But there are lots of other ways to represent text. You can count two-word phrases, or measure white space if you like. Qualitative information that can’t be counted can be represented as a “categorical variable.” It’s also possible to consider syntax, if you need to. Computational linguists are getting pretty good at parsing sentences; many of their insights have been packaged accessibly in projects like the Natural Language Toolkit. And there will certainly be research questions — involving, for instance, the concept of character — that require syntactic analysis. But they tend not to be questions that are appropriate for people just starting out.
3) Identify distinctive vocabulary.
It can be pretty easy, on the other hand, to produce useful insights on the level of diction. These are claims of a kind that literary scholars have long made: The Norton Anthology of English Literature proves that William Wordsworth emblematizes Romantic alienation, for instance, by saying that “the words ‘solitary,’ ‘by one self,’ ‘alone’ sound through his poems” [Greenblatt et. al., 16].
Of course, literary scholars have also learned to be wary of these claims. I guess Wordsworth does write “alone” a lot: but does he really do so more than other writers? “Alone” is a common word. How do we distinguish real insights about diction from specious cherry-picking?
Corpus linguists have developed a number of ways to identify locutions that are really overrepresented in one sample of writing relative to others. One of the most widely used is Dunning’s log-likelihood: Ben Schmidt has explained why it works, and it’s easily accessible online through Voyant or downloaded in the AntConc application already mentioned. So if you have a sample of one author’s writing (say Wordsworth), and a reference corpus against which to contrast it (say, a collection of other poetry), it’s really pretty straightforward to identify terms that typify Wordsworth relative to the other sample. (There are also other ways to measure overrepresentation; Adam Kilgarriff recommends a Mann-Whitney test.) And in fact there’s pretty good evidence that “solitary” is among the words that distinguish Wordsworth from other poets.Words that are consistently more common in works by William Wordsworth than in other poets from 1780 to 1850. I’ve used Wordle’s graphics, but the words have been selected by a Mann-Whitney test, which measures overrepresentation relative to a context — not by Wordle’s own (context-free) method.
It’s also easy to turn results like this into a word cloud — if you want to. People make fun of word clouds, with some justice; they’re eye-catching but don’t give you a lot of information. I use them in blog posts, because eye-catching, but I wouldn’t in an article.
4) Find or organize works.
This rubric is shorthand for the enormous number of different ways we might use information technology to organize collections of written material or orient ourselves in discursive space. Humanists already do this all the time, of course: we rely very heavily on web search, as well as keyword searching in library catalogs and full-text databases.
But our current array of strategies may not necessarily reveal all the things we want to find. This will be obvious to historians, who work extensively with unpublished material. But it’s true even for printed books: works of poetry or fiction published before 1960, for instance, are often not tagged as “poetry” or “fiction.”A detail from Fig 7 in So and Long, “Network Analysis and the Sociology of Modernism.”Even if we believed that the task of simply finding things had been solved, we would still need ways to map or organize these collections. One interesting thread of research over the last few years has involved mapping the concrete social connections that organize literary production. Natalie Houston has mapped connections between Victorian poets and publishing houses; Hoyt Long and Richard Jean So have shown how writers are related by publication in the same journals [Houston 2014; So and Long 2013].
There are of course hundreds of other ways humanists might want to organize their material. Maps are often used to visualize references to places, or places of publication. Another obvious approach is to group works by some measure of textual similarity.
There aren’t purpose-built tools to support much of this work. There are tools for building visualizations, but often the larger part of the problem is finding, or constructing, the metadata you need.
5) Model literary forms or genres.
Throughout the rest of this post I’ll be talking about “modeling”; underselling the centrality of that concept seems to me the main oversight in the 2012 post I’m fixing.A model treehouse, by Austin and Zak — CC-NC-SA.A model is a simplified representation of something, and in principle models can be built out of words, balsa wood, or anything you like. In practice, in the social sciences, statistical models are often equations that describe the probability of an association between variables. Often the “response variable” is the thing you’re trying to understand (literary form, voting behavior, or what have you), and the “predictor variables” are things you suspect might help explain or predict it.
This isn’t the only way to approach text analysis; historically, humanists have tended to begin instead by first choosing some aspect of text to measure, and then launching an argument about the significance of the thing they measured. I’ve done that myself, and it can work. But social scientists prefer to tackle problems the other way around: first identify a concept that you’re trying to understand, and then try to model it. There’s something to be said for their bizarrely systematic approach.
Building a model can help humanists in a number of ways. Classically, social scientists model concepts in order to understand them better. If you’re trying to understand the difference between two genres or forms, building a model could help identify the features that distinguish them.
The tension between modeling-to-explain and modeling-to-predict has been discussed at length in other disciplines [Shmueli, 2010]. But statistical models haven’t been used extensively in historical research yet, and humanists may well find ways to use them that aren’t common in other disciplines. For instance, once we have a model of a phenomenon, we may want to ask questions about the diachronic stability of the pattern we’re modeling. (Does a model trained to recognize this genre in one decade make equally good predictions about the next?)
There are lots of software packages that can help you infer models of your data. But assessing the validity and appropriateness of a model is a trickier business. It’s important to fully understand the methods we’re borrowing, and that’s likely to require a bit of background reading. One might start by understanding the assumptions implicit in simple linear models, and work up to the more complex models produced by machine learning algorithms [Sculley and Pasanek 2008]. In particular, it’s important to learn something about the problem of “overfitting.” Part of the reason statistical models are becoming more useful in the humanities is that new methods make it possible to use hundreds or thousands of variables, which in turn makes it possible to represent unstructured text (those bags of words tend to contain a lot of variables). But large numbers of variables raise the risk of “overfitting” your data, and you’ll need to know how to avoid that.
6) Model social boundaries.
There’s no reason why statistical models of text need to be restricted to questions of genre and form. Texts are also involved in all kinds of social transactions, and those social contexts are often legible in the text itself.
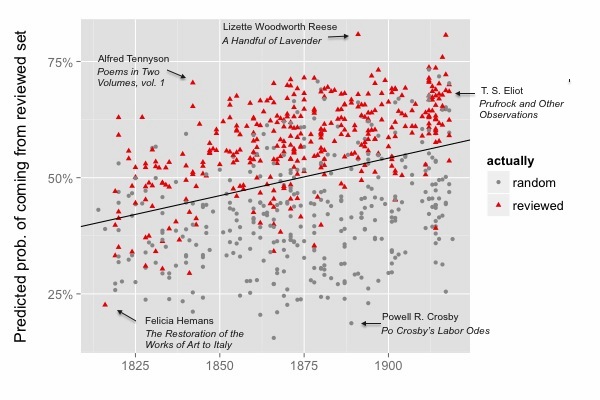
For instance, Jordan Sellers and I have recently been studying the history of literary distinction by training models to distinguish poetry reviewed in elite periodicals from a random selection of volumes drawn from a digital library. There are a lot of things we might learn by doing this, but the top-line result is that the implicit standards distinguishing elite poetic discourse turn out to be relatively stable across a century.
7) Unsupervised modeling.
The models we’ve discussed so far are supervised in the sense that they have an explicit goal. You already know (say) which novels got reviewed in prominent periodicals, and which didn’t; you’re training a model in order to discover whether there are any patterns in the texts themselves that might help us explain this social boundary, or trace its history.
But advances in machine learning have also made it possible to train unsupervised models. Here you start with an unlabeled collection of texts; you ask a learning algorithm to organize the collection by finding clusters or patterns of some loosely specified kind. You don’t necessarily know what patterns will emerge.
But I’m putting unsupervised models at the end of this list because they may almost be too seductive. Topic modeling is perfectly designed for workshops and demonstrations, since you don’t have to start with a specific research question. A group of people with different interests can just pour a collection of texts into the computer, gather round, and see what patterns emerge. Generally, interesting patterns do emerge: topic modeling can be a powerful tool for discovery. But it would be a mistake to take this workflow as paradigmatic for text analysis. Usually researchers begin with specific research questions, and for that reason I suspect we’re often going to prefer supervised models.
* * *
In short, there are a lot of new things humanists can do with text, ranging from new versions of things we’ve always done (make literary arguments about diction), to modeling experiments that take us fairly deep into the methodological terrain of the social sciences. Some of these projects can be crystallized in a push-button “tool,” but some of the more ambitious projects require a little familiarity with a data-analysis environment like Rstudio, or even a programming language like Python, and more importantly with the assumptions underpinning quantitative social science. For that reason, I don’t expect these methods to become universally diffused in the humanities any time soon. In principle, everything above is accessible for undergraduates, with a semester or two of preparation — but it’s not preparation of a kind that English or History majors are guaranteed to have.
Generally I leave blog posts undisturbed after posting them, to document what happened when. But things are changing rapidly, and it’s a lot of work to completely overhaul a survey post like this every few years, so in this one case I may keep tinkering and adding stuff as time passes. I’ll flag my edits with a date in square brackets.
Elson, D. K., N. Dames, and K. R. McKeown. “Extracting Social Networks from Literary Fiction.” Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Uppsala, Sweden, 2010. 138-147.
Greenblatt, Stephen, et. al., Norton Anthology of English Literature 8th Edition, vol 2 (New York: WW Norton, 2006.
The list could go on, but I’m not trying to cover everything — just observing that “DH” didn’t begin by embedding itself in the curricula of humanities departments. It went around them, in improvisational and surprisingly successful ways.
That’s a history to be proud of, but I think it’s also setting us up for predictable frustrations at the moment, as disciplines decide to import “DH” and reframe it in disciplinary terms. (“Seeking a scholar of early modern drama, with a specialization in digital humanities …”)
But although the research payoff is clear, the marriage between disciplinary and extradisciplinary institutions may not be so easy. I sense that a lot of friction around this topic is founded in a feeling that it ought to be straightforward to integrate new modes of study in disciplinary curricula and career paths. So when this doesn’t go smoothly, we feel there must be some irritating mistake in existing disciplines, or in the project of DH itself. Something needs to be trimmed to fit.
What I want to say is just this: there’s actually no reason this should be easy. Grafting a complex extradisciplinary project onto existing disciplines may not completely work. That’s not because anyone made a mistake.
Consider my home field of literary study. If digital methods were embodied in a critical “approach,” like psychoanalysis, they would be easy to assimilate. We could identify digital “readings” of familiar texts, add an article to every Norton edition, and be done with it. In some cases that actually works, because digital methods do after all change the way we read familiar texts. But DH also tends to raise foundational questions about the way literary scholarship is organized. Sometimes it valorizes things we once considered “mere editing” or “mere finding aids”; sometimes it shifts the scale of literary study, so that courses organized by period and author no longer make a great deal of sense. Disciplines can be willing to welcome new ideas, and yet (understandably) unwilling to undertake this sort of institutional reorganization.
Training is an even bigger problem. People have argued long and fiercely about the amount of digital training actually required to “do DH,” and I’m not going to resolve that question here. I just want to say that there’s a reason for the argument: it’s a thorny problem. In many cases, humanists are now tackling projects that require training not provided in humanities departments. There are a lot of possible fixes for that — we can make tools easier to use, foster collaboration — but none of those fixes solve the whole problem. Not everything can be externalized as a “tool.” Some digital methods are really new forms of interpretation; packaging them in a GUI would create a problematic black box. Collaboration, likewise, may not remove the need for new forms of training. Expecting computer scientists to do all the coding on a project can be like expecting English professors to do all the spelling.
I think these problems can find solutions, but I’m coming to suspect that the solutions will be messy. Humanities curricula may evolve, but I don’t think the majority of English or History departments are going to embrace rapid structural change — for instance, change of the kind that would be required to support graduate programs in distant reading. These disciplines have already spent a hundred years rejecting rapprochement with social science; why would they change course now? English professors may enjoy reading Moretti, but it’s going to be a long time before they add a course on statistical methods to the major.
Meanwhile, there are other players in this space (at least at large universities): iSchools, Linguistics, Departments of Communications, Colleges of Media. Digital methods are being assimilated rapidly in these places. New media, of course, are already part of media studies, and if a department already requires statistics, methods like topic modeling are less of a stretch. It’s quite possible that the distant reading of literary culture will end up being shared between literature departments and (say) Communications. The reluctance of literary studies to become a social science needn’t prevent social scientists from talking about literature.
I’m saying all this because I think there’s a strong tacit narrative in DH that understands extradisciplinary institutions as a wilderness, in which we have wandered that we may reach the promised land of recognition by familiar disciplinary authority. In some ways that’s healthy. It’s good to have work organized by clear research questions (so we aren’t just digitizing aimlessly), and I’m proud that digital methods are making contributions to the core concerns of literary studies.
But I’m also wary of the normative pressures associated with that narrative, because (if you’ll pardon the extended metaphor) I’m not sure this caravan actually fits in the promised land. I suspect that some parts of the sprawling enterprise called “DH” (in fact, some of the parts I enjoy most) won’t be absorbed easily in the curricula of History or English. That problem may be solved differently at different schools; the nice thing about strong extradisciplinary institutions is that they allow us to work together even if the question of disciplinary identity turns out to be complex.
postscript: This whole post should have footnotes to Bethany Nowviskie every time I use the term “extradisciplinary,” and to Matt Kirschenbaum every time I say “DH” with implicit air quotes.
If the Internet is good for anything, it’s good for speeding up the Ent-like conversation between articles, to make that rumble more perceptible by human ears. I thought I might help the process along by summarizing the Stanford Literary Lab’s latest pamphlet — a single-authored piece by Franco Moretti, “‘Operationalizing’: or the function of measurement in modern literary theory.”
One of the many strengths of Moretti’s writing is a willingness to dramatize his own learning process. This pamphlet situates itself as a twist in the ongoing evolution of “computational criticism,” a turn from literary history to literary theory.
Measurement as a challenge to literary theory, one could say, echoing a famous essay by Hans Robert Jauss. This is not what I expected from the encounter of computation and criticism; I assumed, like so many others, that the new approach would change the history, rather than the theory of literature ….
Measurement challenges literary theory because it asks us to “operationalize” existing critical concepts — to say, for instance, exactly how we know that one character occupies more “space” in a work than another. Are we talking simply about the number of words they speak? or perhaps about their degree of interaction with other characters?
Moretti uses Alex Woloch’s concept of “character-space” as a specific example of what it means to operationalize a concept, but he’s more interested in exploring the broader epistemological question of what we gain by operationalizing things. When literary scholars discuss quantification, we often tacitly assume that measurement itself is on trial. We ask ourselves whether measurement is an adequate proxy for our existing critical concepts. Can mere numbers capture the ineffable nuances we assume they possess? Here, Moretti flips that assumption and suggests that measurement may have something to teach us about our concepts — as we’re forced to make them concrete, we may discover that we understood them imperfectly. At the end of the article, he suggests for instance (after begging divine forgiveness) that Hegel may have been wrong about “tragic collision.”
I think Moretti is frankly right about the broad question this pamphlet opens. If we engage quantitative methods seriously, they’re not going to remain confined to empirical observations about the history of predefined critical concepts. Quantification is going to push back against the concepts themselves, and spill over into theoretical debate. I warned y’all back in August that literary theory was “about to get interesting again,” and this is very much what I had in mind.
At this point in a scholarly review, the standard procedure is to point out that a work nevertheless possesses “oversights.” (Insight, meet blindness!) But I don’t think Moretti is actually blind to any of the reflections I add below. We have differences of rhetorical emphasis, which is not the same thing.
For instance, Moretti does acknowledge that trying to operationalize concepts could cause them to dissolve in our hands, if they’re revealed as unstable or badly framed (see his response to Bridgman on pp. 9-10). But he chooses to focus on a case where this doesn’t happen. Hegel’s concept of “tragic collision” holds together, on his account; we just learn something new about it.
In most of the quantitative projects I’m pursuing, this has not been my experience. For instance, in developing statistical models of genre, the first thing I learned was that critics use the word genre to cover a range of different kinds of categories, with different degrees of coherence and historical volatility. Instead of coming up with a single way to operationalize genre, I’m going to end up producing several different mapping strategies that address patterns on different scales.
Something similar might be true even about a concept like “character.” In Vladimir Propp’s Morphology of the Folktale, for instance, characters are reduced to plot functions. Characters don’t have to be people or have agency: when the hero plucks a magic apple from a tree, the tree itself occupies the role of “donor.” On Propp’s account, it would be meaningless to represent a tale like “Le Petit Chaperon Rouge” as a social network. Our desire to imagine narrative as a network of interactions between imagined “people” (wolf ⇌ grandmother) presupposes a separation between nodes and edges that makes no sense for Propp. But this doesn’t necessarily mean that Moretti is wrong to represent Hamlet as a social network: Hamlet is not Red Riding Hood, and tragic drama arguably envisions character in a different way. In short, one of the things we might learn by operationalizing the term “character” is that the term has genuinely different meanings in different genres, obscured for us by the mere continuity of a verbal sign. [I should probably be citing Tzvetan Todorov here, The Poetics of Prose, chapter 5.]
Illustration from “Learning Latent Personas of Film Characters,” Bamman et. al.Another place where I’d mark a difference of emphasis from Moretti involves the tension, named in my title, between “measurement” and “modeling.” Moretti acknowledges that there are people (like Graham Sack) who assume that character-space can’t be measured directly, and therefore look for “proxy variables.” But concepts that can’t be directly measured raise a set of issues that are quite a bit more challenging than the concept of a “proxy” might imply. Sack is actually trying to build models that postulate relations between measurements. Digital humanists are probably most familiar with modeling in the guise of topic modeling, a way of mapping discourse by postulating latent variables called “topics” that can’t be directly observed. But modeling is a flexible heuristic that could be used in a lot of different ways.
The illustration on the right is a probabilistic graphical model drawn from a paper on the “Latent Personas of Film Characters” by Bamman, O’Connor, and Smith. The model represents a network of conditional relationships between variables. Some of those variables can be observed (like words in a plot summary w and external information about the film being summarized md), but some have to be inferred, like recurring character types (p) that are hypothesized to structure film narrative.
Having empirically observed the effects of illustrations like this on literary scholars, I can report that they produce deep, Lovecraftian horror. Nothing looks bristlier and more positivist than plate notation.
But I think this is a tragic miscommunication produced by language barriers that both sides need to overcome. The point of model-building is actually to address the reservations and nuances that humanists correctly want to interject whenever the concept of “measurement” comes up. Many concepts can’t be directly measured. In fact, many of our critical concepts are only provisional hypotheses about unseen categories that might (or might not) structure literary discourse. Before we can attempt to operationalize those categories, we need to make underlying assumptions explicit. That’s precisely what a model allows us to do.
It’s probably going to turn out that many things are simply beyond our power to model: ideology and social change, for instance, are very important and not at all easy to model quantitatively. But I think Moretti is absolutely right that literary scholars have a lot to gain by trying to operationalize basic concepts like genre and character. In some cases we may be able to do that by direct measurement; in other cases it may require model-building. In some cases we may come away from the enterprise with a better definition of existing concepts; in other cases those concepts may dissolve in our hands, revealed as more unstable than even poststructuralists imagined. The only thing I would say confidently about this project is that it promises to be interesting.
A couple of weeks ago, after reading abstracts from DH2013, I said that the take-away for me was that “literary theory is about to get interesting again” – subtweeting the course of history in a way that I guess I ought to explain.
A 1915 book by Chicago’s “Professor of Literary Theory.”
In the twentieth century, “literary theory” was often a name for the sparks that flew when literary scholars pushed back against challenges from social science. Theory became part of the academic study of literature around 1900, when the comparative study of folklore seemed to reveal coherent patterns in national literatures that scholars had previously treated separately. Schools like the University of Chicago hired “Professors of Literary Theory” to explore the controversial possibility of generalization.* Later in the century, structural linguistics posed an analogous challenge, claiming to glimpse an organizing pattern in language that literary scholars sought to appropriate and/or deconstruct. Once again, sparks flew.
I think literary scholars are about to face a similarly productive challenge from the discipline of machine learning — a subfield of computer science that studies learning as a problem of generalization from limited evidence. The discipline has made practical contributions to commercial IT, but it’s an epistemological method founded on statistics more than it is a collection of specific tools, and it tends to be intellectually adventurous: lately, researchers are trying to model concepts like “character” (pdf) and “gender,” citing Judith Butler in the process (pdf).
This could be the beginning of a beautiful friendship. I realize a marriage between machine learning and literary theory sounds implausible: people who enjoy one of these things are pretty likely to believe the other is fraudulent and evil.** But after reading through a couple of ML textbooks,*** I’m convinced that literary theorists and computer scientists wrestle with similar problems, in ways that are at least loosely congruent. Neither field is interested in the mere accumulation of data; both are interested in understanding the way we think and the kinds of patterns we recognize in language. Both fields are interested in problems that lack a single correct answer, and have to be mapped in shades of gray (ML calls these shades “probability”). Both disciplines are preoccupied with the danger of overgeneralization (literary theorists call this “essentialism”; computer scientists call it “overfitting”). Instead of saying “every interpretation is based on some previous assumption,” computer scientists say “every model depends on some prior probability,” but there’s really a similar kind of self-scrutiny involved.
It’s already clear that machine learning algorithms (like topic modeling) can be useful tools for humanists. But I think I glimpse an even more productive conversation taking shape, where instead of borrowing fully-formed “tools,” humanists borrow the statistical language of ML to think rigorously about different kinds of uncertainty, and return the favor by exposing the discipline to boundary cases that challenge its methods.
Won’t quantitative models of phenomena like plot and genre simplify literature by flattening out individual variation? Sure. But the same thing could be said about Freud and Lévi-Strauss. When scientists (or social scientists) write about literature they tend to produce models that literary scholars find overly general. Which doesn’t prevent those models from advancing theoretical reflection on literature! I think humanists, conversely, can warn scientists away from blind alleys by reminding them that concepts like “gender” and “genre” are historically unstable. If you assume words like that have a single meaning, you’re already overfitting your model.
Of course, if literary theory and computer science do have a conversation, a large part of the conversation is going to be a meta-debate about what the conversation can or can’t achieve. And perhaps, in the end, there will be limits to the congruence of these disciplines. Alan Liu’s recent essay in PMLA pushes against the notion that learning algorithms can be analogous to human interpretation, suggesting that statistical models become meaningful only through the inclusion of human “seed concepts.” I’m not certain how deep this particular disagreement goes, because I think machine learning researchers would actually agree with Liu that statistical modeling never starts from a tabula rasa. Even “unsupervised” algorithms have priors. More importantly, human beings have to decide what kind of model is appropriate for a given problem: machine learning aims to extend our leverage over large volumes of data, not to take us out of the hermeneutic circle altogether.
But as Liu’s essay demonstrates, this is going to be a lively, deeply theorized conversation even where it turns out that literary theory and computer science have fundamental differences. These disciplines are clearly thinking about similar questions: Liu is right to recognize that unsupervised learning, for instance, raises hermeneutic questions of a kind that are familiar to literary theorists. If our disciplines really approach similar questions in incompatible ways, it will be a matter of some importance to understand why.
** This post grows out of a conversation I had with Eleanor Courtemanche, in which I tried to convince her that machine learning doesn’t just reproduce the biases you bring to it.
PS later that afternoon: Belatedly realize I didn’t say anything about the most controversial word in my original tweet: “literary theory is about to get interesting again.” I suppose I tacitly distinguish literary theory (which has been a little sleepy lately, imo) from theory-sans-adjective (which has been vigorous, although hard to define). But now I’m getting into a distinction that’s much too slippery for a short blog post.