
would you like some help with that?
I’m not being snarky. Right now, I have several friends writing articles that are largely or partly a critique of interrelated trends that go under the names “data” or “distant reading.” It looks like many other articles of the same kind are being written.
This is good news! I believe fervently in Mae West’s theory of publicity. “I don’t care what the newspapers say about me as long as they spell my name right.” (Though it turns out we may not actually know who said that, so I guess the newspapers failed.)
In any case, this blog post is not going to try to stop you from proving that numbers are neoliberal, unethical, inevitably assert objectivity, aim to eliminate all close reading from literary study, fail to represent time, and lead to loss of “cultural authority.” Go for it! Ideas live on critique.
But I do want to help you “spell our names right.” Andrew Piper has recently pointed out that critiques of data-driven research tend to use a small sample of articles. He expressed that more strongly, but I happen to like the article he was aiming at, so I’m going to soften his expression. However, I don’t disagree with the underlying point! For some reason, critics of numbers don’t feel they need to consider more than one example, or two if they’re in a generous mood.
There are some admirable exceptions to this rule. I’ve argued that a recent issue of Genre was, in general, moving in the right direction. And I’m fairly confident that the trend will continue. A field that has been generating mostly articles and pamphlets is about to shift into a lower gear and publish several books. In literary studies, that tends to be an effective way of reframing debate.
But it may be another twelve to eighteen months before those books are out. In the meantime, you’ve got to finish your critique. So let me help with the bibliography.
When you’re tempted to assume that all possible uses of numbers (or “data”) in literary study can be summed up by engaging one or two texts that Franco Moretti wrote in the year 2000, you should resist the assumption. You are actually talking about a long, complex story, and your readers deserve some glimpse of its complexity.
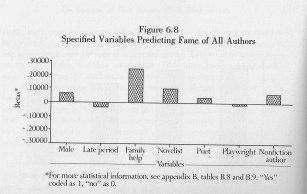
For instance, sociologists, linguists and book historians have been using numbers to describe literature since the middle of the twentieth century. You should make clear whether you are critiquing that work, or just arguing that it is incapable of addressing the inner literariness of literature. The journal Computers and the Humanities started in the 1960s. The 1980s gave rise to a thriving tradition of feminist literary sociology, embodied in books by Janice Radway and Gaye Tuchman, and in the journal Signs. I’ve used one of Tuchman’s regression models as an illustration here.
<deep breath>
In the 1990s, Mark Olsen (working at the University of Chicago) started to articulate many of the impulses we now call “distant reading.” Around 2000, Franco Moretti gave quantitative approaches an infusion of polemical verve and wit, which raised their profile among literary scholars who had not previously paid attention. (Also, frankly, the fact that Moretti already had disciplinary authority to spend mattered a great deal. Literary scholars can be temperamentally conservative even when theoretically radical.)
But Moretti himself is a moving target. The articles he has written since 2008 aim at different goals, and use different methods, than articles before that date. Part of the point of an experimental method, after all, is that you are forced to revise your assumptions! Because we are actually learning things, this field is changing rapidly. A recent pamphlet from the Stanford Literary Lab conceives the role of the “archive,” for instance, very differently than “Slaughterhouse of Literature” did.
But that pamphlet was written by six authors—a useful reminder that this is a collective project. Today the phrase “distant reading” is often a loose description for large-scale literary history, covering many people who disagree significantly with Moretti. In a recent roundtable in PMLA, for instance, Andrew Goldstone argues for evidence of a more sociological and less linguistic kind. Lisa Rhody and Alison Booth both argue for different scales or forms of “distance.” Richard Jean So argues that the simple measurements which typified much work before 2010 need to be replaced by statistical models, which account for variation and uncertainty in a more principled way.
One might also point, for instance, to Lauren Klein’s work on gaps in the archive, or to Ryan Cordell’s work on literary circulation, or to Katherine Bode’s work, which aims to construct corpora that represent literary circulation rather than production. Or to Matt Wilkens, or Hoyt Long, or Tanya Clement, or Matt Jockers, or James F. English … I’m going to run out of breath before I run out of examples.
Not all of these scholars believe that numbers will put literary scholarship on a more objective footing. Few of them believe that numbers can replace “interpretation” with “explanation.” None of them, as far as I can tell, have stopped doing close reading. (I would even claim to pair numbers with close reading in Joseph North’s strong sense of the phrase: not just reading-to-illustrate-a-point but reading-for-aesthetic-cultivation.) In short, the work literary scholars are doing with numbers is not easily unified by a shared set of principles—and definitely isn’t unified by a 17-year-old polemic. The field is unified, rather, by a fast-moving theoretical debate. Literary production versus circulation. Book history versus social science. Sociology versus linguistics. Measurement versus modeling. Interpretation versus explanation versus prediction.
Critics of this work may want to argue that it all nevertheless fails in the same way, because numbers inevitably (flatten time/reduce reading to visualization/exclude subjectivity/fill in the blank). That’s a fair thesis to pursue. But if you believe that, you need to show that your generalization is true by considering several different (recent!) examples, and teasing out the tacit similarities concealed underneath ostensible disagreements. I hope this post has helped with some of the bibliographic legwork. If you want more sources, I recently wrote a “Genealogy of Distant Reading” that will provide more. Now, tear them apart!

 So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
So I’m not volunteering to tackle any of the three problems that follow. I’m just putting up a bat signal, in case there’s a weary private detective out there who might be the heroine Gotham City needs right now.
