
This post is substantially the same as a talk I delivered at the University of Nebraska on Friday, Feb 8th.
In recent months I’ve had several conversations with colleagues who are friendly to digital methods but wary of claims about novelty that seem overstated. They believe that text mining can add a new level of precision to our accounts of literary history, or add a new twist to an existing debate. They just don’t think it’s plausible that quantification will uncover fundamentally new evidence, or patterns we didn’t previously expect.
If I understand my friends’ skepticism correctly, it’s founded less on a narrow objection to text mining than on a basic premise about the nature of literary study. And where the history of the discipline is concerned, they’re arguably right. In fact, the discipline of literary studies has not usually advanced by uncovering unexpected evidence. As grad students, that’s not what we were taught to aim for. Instead we learned that the discipline moves forward dialectically. You take something that people already believe and “push against” it, or “critique” it, or “complicate” it. You don’t make discoveries in literary study, or if you do they’re likely to be minor — a lost letter from Byron to his tailor. Instead of making discoveries, you make interventions — a telling word.
So much flows from this assumption. If we’re not aiming for discovery, if the broad contours of literary history are already known, then methodological conversation can only be a zero-sum game. That’s why, when I say “digital methods don’t have to displace traditional scholarship,” my colleagues nod politely but assume it’s insincere happy talk. They know that in reality, the broad contours of our discipline are already known, and anything within those boundaries can only grow by displacing something else.
These are the assumptions I was also working with until about three years ago. But a couple of years of mucking about in digital archives have convinced me that the broad contours of literary history are not in fact well understood.
For instance, I just taught a course called Introduction to Fiction, and as part of that course I talk about the importance of point of view. You can characterize point of view in a lot of subtle ways, but the initial, basic division is between first-person and third-person perspectives.
Suppose some student had asked the obvious question, “Which point of view is more common? Is fiction mostly written in the first or third person? And how long has it been that way?” Fortunately undergrads don’t ask questions like that, because I couldn’t have answered.
I have a suspicion that first person is now used more often in literary fiction than in novels for a mass market, but if you ask me to defend that — I can’t. If you ask me how long it’s been that way — no clue. I’ve got a Ph.D in this field, but I don’t know the history of a basic formal device. Now, I’m not totally ignorant. I can say what everyone else says: “Jane Austen perfected free indirect discourse. Henry James. Focalizing character. James Joyce. Stream of consciousness. Etc.” And three years ago that might have seemed enough, because the bigger, simpler question was obviously unanswerable and I wouldn’t have bothered to pose it.
But recently I’ve realized that this question is answerable. We’ve got large digital archives, so we could in principle figure out how the proportions of first- and third-person narration have changed over time.
You might reasonably expect me to answer that question now. If so, you underestimate my commitment to the larger thesis here: that we don’t understand literary history. I will eventually share some new evidence about the history of narration. But first I want to stress that I’m not in a position to fully answer the question I’ve posed. For three reasons:
1) Our digital collections are incomplete. I’m working with a collection of about 700,000 18th and 19th-century volumes drawn from HathiTrust.
That’s a lot. But it’s not everything that was written in the English language, or even everything that was published.
2) This is work in progress. For instance, I’ve cleaned and organized the non-serial part of the collection (about 470,000 volumes), but I haven’t started on the periodicals yet. Also, at the moment I’m counting volumes rather than titles, so if a book was often reprinted I count it multiple times. (This could be a feature or a bug depending on your goals.)
3) Most importantly, we can’t answer the question because we don’t fully understand the terms we’re working with. After all, what is “first-person narration?”
The truth is that the first person comes in a lot of different forms. There are cases where the narrator is also the protagonist. That’s pretty straightforward. Then epistolary novels. Then there are cases where the narrator is anonymous — and not a participant in the action — but sometimes refers to herself as I. Even Jane Austen’s narrator sometimes says “I.” Henry Fielding’s narrator does it a lot more. Should we simply say this is third-person narration, or should we count it as a move in the direction of first? Then, what are we going to do about books like Bleak House? Alternating chapters of first and third person. Maybe we call that 50% first person? — or do we assign it to a separate category altogether? What about a novel like Dracula, where journals and letters are interspersed with news clippings?
Suppose we tried to crowdsource this problem. We get a big team together and decide to go through half a million volumes, first of all to identify the ones that are fiction, and secondly, if a volume is fiction, to categorize the point of view. Clearly, it’s going to be hard to come to agreement on categories. We might get halfway through the crowdsourcing process, discover a new category, and have to go back to the drawing board.
 Notice that I haven’t mentioned computers at all yet. This is not a problem created by computers, because they “only understand binary logic.” It’s a problem created by us. Distant reading is hard, fundamentally, because human beings don’t agree on a shared set of categories. Franco Moretti has a well-known list of genres, for instance, in Graphs, Maps, Trees. But that list doesn’t represent an achieved consensus. Moretti separates the eighteenth-century gothic novel from the late-nineteenth-century “imperial gothic.” But for other critics, those are two parts of the same genre. For yet other critics, the “gothic” isn’t a genre at all; it’s a mode like tragedy or satire, which is why gothic elements can pervade a bunch of different genres.
Notice that I haven’t mentioned computers at all yet. This is not a problem created by computers, because they “only understand binary logic.” It’s a problem created by us. Distant reading is hard, fundamentally, because human beings don’t agree on a shared set of categories. Franco Moretti has a well-known list of genres, for instance, in Graphs, Maps, Trees. But that list doesn’t represent an achieved consensus. Moretti separates the eighteenth-century gothic novel from the late-nineteenth-century “imperial gothic.” But for other critics, those are two parts of the same genre. For yet other critics, the “gothic” isn’t a genre at all; it’s a mode like tragedy or satire, which is why gothic elements can pervade a bunch of different genres.
This is the darkest moment of this post. It may seem that there’s no hope for literary historians. How can we ever know anything if we can’t even agree on the definitions of basic concepts like genre and point of view? But here’s the crucial twist — and the real center of what I want to say. The blurriness of literary categories is exactly why it’s helpful to use computers for distant reading. With an algorithm, we can classify 500,000 volumes provisionally. Try defining point of view one way, and see what you get. If someone else disagrees, change the definition; you can run the algorithm again overnight. You can’t re-run a crowdsourced cataloguing project on 500,000 volumes overnight.
Second, algorithms make it easier to treat categories as plural and continuous. Although Star Trek teaches us otherwise, computers do not start to stammer and emit smoke if you tell them that an object belongs in two different categories at once. Instead of sorting texts into category A or category B, we can assign degrees of membership to multiple categories. As many as we want. So The Moonstone can be 80% similar to a sensation novel and 50% similar to an imperial gothic, and it’s not a problem. Of course critics are still going to disagree about individual cases. And we don’t have to pretend that these estimates are precise characterizations of The Moonstone. The point is that an algorithm can give us a starting point for discussion, by rapidly mapping a large collection in a consistent but flexibly continuous way.
Then we can ask, Does the gothic often overlap with the sensation novel? What other genres does it overlap with? Even if the boundaries are blurry, and critics disagree about every individual case — even if we don’t have a perfect definition of the term “genre” itself — we’ve now got a map, and we can start talking about the relations between regions of the map.
Can we actually do this? Can we use computers to map things like genre and point of view? Yes, to coin a phrase, we can. The truth is that you can learn a lot about a document just by looking at word frequency. That’s how search engines work, that’s how spam gets filtered out of your e-mail; it’s a well-developed technology. The Stanford Literary Lab suggested a couple of years ago that it would probably work for literary genres as well (see Pamphlet 1), and Matt Jockers has more detailed work forthcoming on genre and diction in Macroanalysis.
There are basically three steps to the process. First, get a training set of a thousand or so examples and tag the categories you want to recognize: poetry or prose, fiction or nonfiction, first- or third-person narration. Then, identify features (usually words) that turn out to provide useful clues about those categories. There are a lot of ways of doing this automatically. Personally, I use a Wilcoxon test to identify words that are consistently common or uncommon in one class relative to others. Finally, train classifiers using those features. I use what’s known as an “ensemble” strategy where you train multiple classifiers and they all contribute to the final result. Each of the classifiers individually uses an algorithm called “naive Bayes,” which I’m not going to explain in detail here; let’s just say that collectively, as a group, they’re a little less “naive” than they are individually — because they’re each relying on slightly different sets of clues.
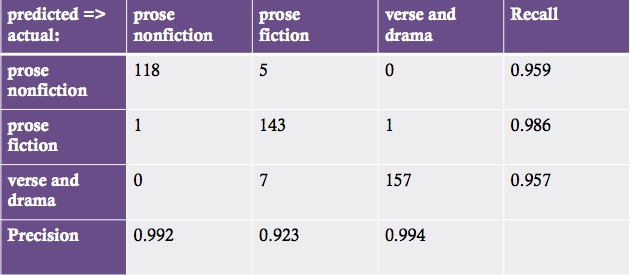
How accurate does this end up being? This confusion matrix gives you a sense. Let me underline that this is work in progress. If I were presenting finished results I would need to run this multiple times and give you an average value. But these are typical results. Here I’ve got a corpus of thirteen hundred nineteenth-century volumes. I train a set of classifiers on two-thirds of the corpus, and then test it by using it to classify the other third of the corpus which it hasn’t yet seen. That’s what I mean by saying 432 documents were “held out.” To make the accuracy calculations simple here, I’ve treated these categories as if they were exclusive, but in the long run, we don’t have to do that: documents can belong to more than one at once.
These results are pretty good, but that’s partly because this test corpus didn’t have a lot of miscellaneous collected works in it. In reality you see a lot of volumes that are a mosaic of different genres — the collected poems and plays of so-and-so, prefaced by a prose life of the author, with an index at the back. Obviously if you try to classify that volume as a single unit, it’s going to be a muddle. But I think it’s not going to be hard to use genre classification itself to segment volumes, so that you get the introduction, and the plays, and the lyric poetry sorted out as separate documents. I haven’t done that yet, but it’s the next thing on my agenda.
One complication I have already handled is historical change. Following up a hint from Michael Witmore, I’ve found that it’s useful to train different classifiers for different historical periods. Then when you get an uncategorized document, you can have each classifier make a prediction, and weight those predictions based on the date of the document.
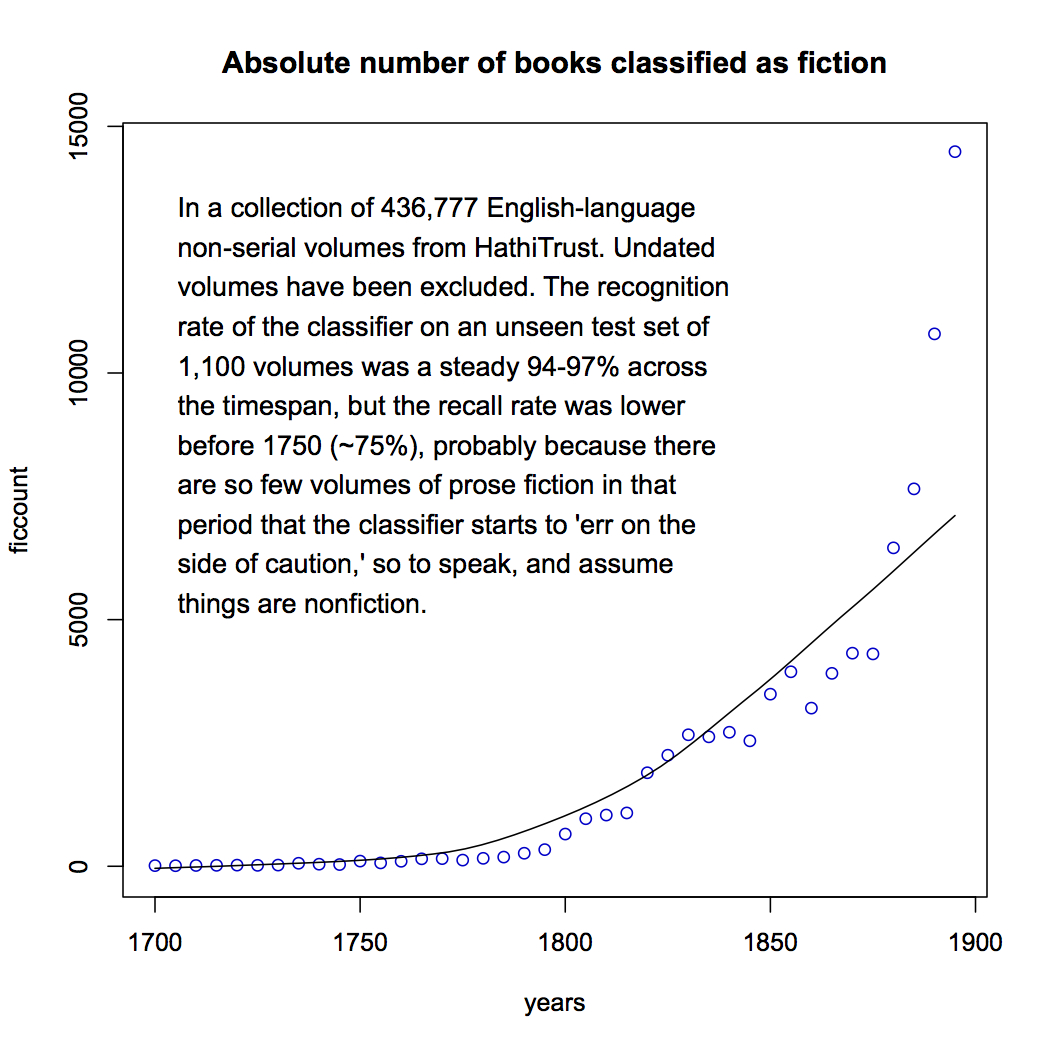 So what have I found? First of all, here’s the absolute number of volumes I was able to identify as fiction in HathiTrust’s collection of eighteenth and nineteenth-century English-language books. Instead of plotting individual years, I’ve plotted five-year segments of the timeline. The increase, of course, is partly just an absolute increase in the number of books published.
So what have I found? First of all, here’s the absolute number of volumes I was able to identify as fiction in HathiTrust’s collection of eighteenth and nineteenth-century English-language books. Instead of plotting individual years, I’ve plotted five-year segments of the timeline. The increase, of course, is partly just an absolute increase in the number of books published.
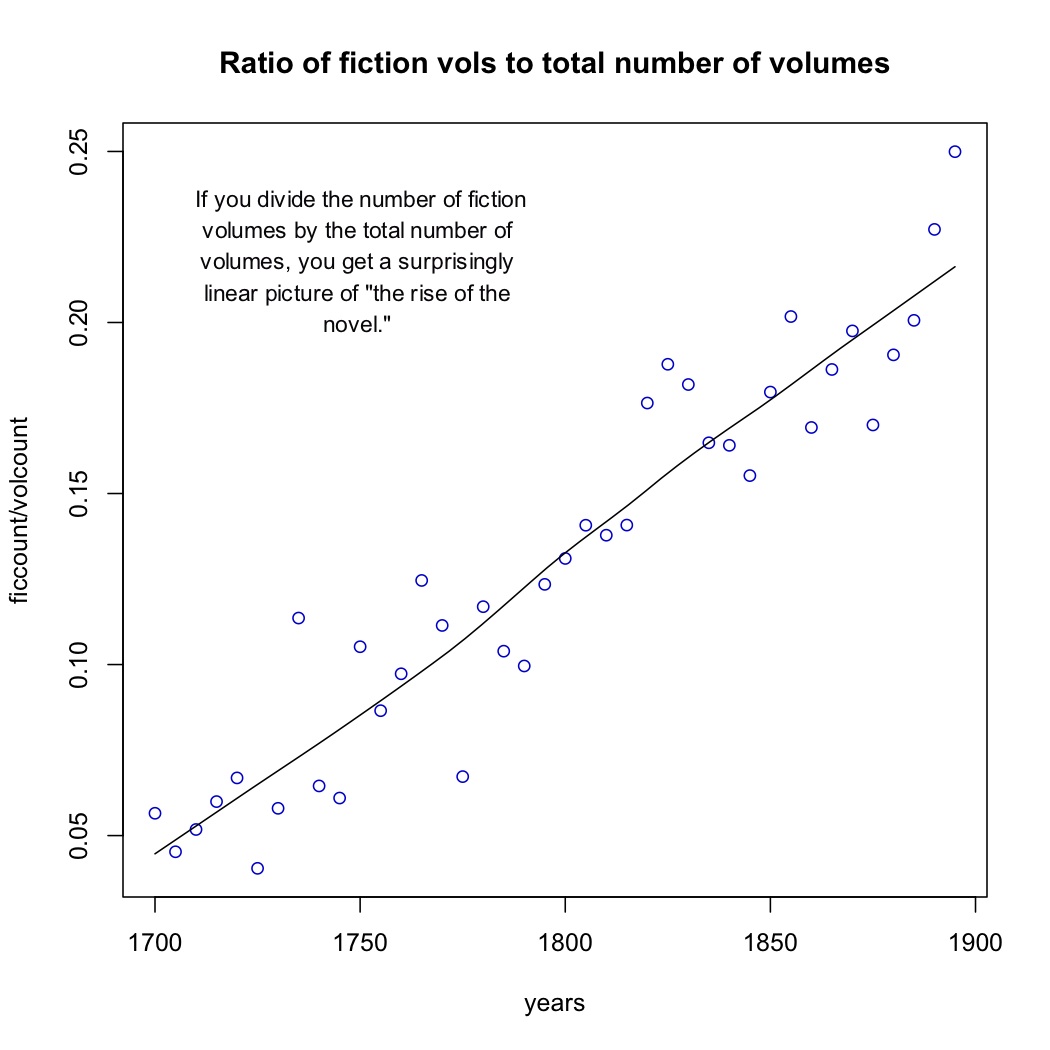 But it’s also an increase specifically in fiction. Here I’ve graphed the number of volumes of fiction divided by the total number of volumes in the collection. The proportion of fiction increases in a straightforward linear way. From 1700-1704, when fiction is only about 5% of the collection, to 1895-99, when it’s 25%. People better-versed in book history may already have known that this was a linear trend, but I was a bit surprised. (I should note that I may be slightly underestimating the real numbers before 1750, for reasons explained in the fine print to the earlier graph — basically, it’s hard for the classifier to find examples of a class that is very rare.)
But it’s also an increase specifically in fiction. Here I’ve graphed the number of volumes of fiction divided by the total number of volumes in the collection. The proportion of fiction increases in a straightforward linear way. From 1700-1704, when fiction is only about 5% of the collection, to 1895-99, when it’s 25%. People better-versed in book history may already have known that this was a linear trend, but I was a bit surprised. (I should note that I may be slightly underestimating the real numbers before 1750, for reasons explained in the fine print to the earlier graph — basically, it’s hard for the classifier to find examples of a class that is very rare.)
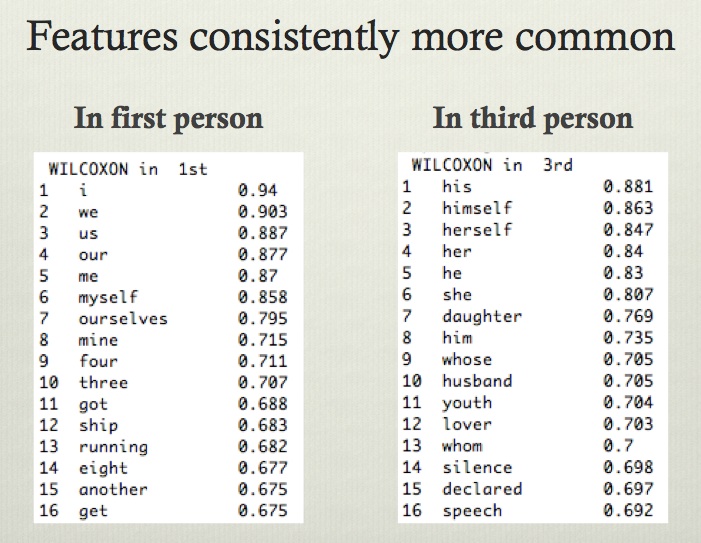
What about the question we started with — first-person narration? I approach this the same way I approached genre classification. I trained a classifier on 290 texts that were clearly dominated by first- or third-person narration, and used a Wilcoxon test to select features that are consistently more common in one set or in the other.
Now, it might seem obvious what these features are going to be: obviously, we would expect first-person and third-person pronouns to be the most important signal. But I’m allowing the classifier to include whatever features it in practice finds. For instance, terms for domestic relationships like “daughter” and “husband” and the relative pronouns “whose” and “whom” are also consistently more common in third-person contexts, and oddly, numbers seem more common in first-person contexts. I don’t know why that is yet; this is work in progress and there’s more exploration to do. But for right now I haven’t second-guessed the classifier; I’ve used the top sixteen features in both lists whether they “make sense” or not.
 And this is what I get. The classifier predicts each volume’s probability of belonging to the class “first person.” That can be anywhere between 0 and 1, and it’s often in the middle (Bleak House, for instance, is 0.54). I’ve averaged those values for each five-year interval. I’ve also dropped the first twenty years of the eighteenth century, because the sample size was so low there that I’m not confident it’s meaningful.
And this is what I get. The classifier predicts each volume’s probability of belonging to the class “first person.” That can be anywhere between 0 and 1, and it’s often in the middle (Bleak House, for instance, is 0.54). I’ve averaged those values for each five-year interval. I’ve also dropped the first twenty years of the eighteenth century, because the sample size was so low there that I’m not confident it’s meaningful.
Now, there’s a lot more variation in the eighteenth century than in the nineteenth century, partly because the sample size is smaller. But even with that variation it’s clear that there’s significantly more first-person narration in the eighteenth century. About half of eighteenth-century fiction is first-person, and in the nineteenth century that drops down to about a quarter. That’s not something I anticipated. I expected that there might be a gradual decline in the amount of first-person narration, but I didn’t expect this clear and relatively sudden moment of transition. Obviously when you see something you don’t expect, the first question you ask is, could something be wrong with the data? But I can’t see a source of error here. I’ve cleaned up most of the predictable OCR errors in the corpus, and there aren’t more medial s’s in one list than in the other anyway.
And perhaps this picture is after all consistent with our expectations. Eleanor Courtemanche points out that the timing of the shift to third person is consistent with Ian Watt’s account of the development of omniscience (as exemplified, for instance, in Austen). In a quick twitter poll I carried out before announcing the result, Jonathan Hope did predict that there would be a shift from first-person to third-person dominance, though he expected it to be more gradual. Amanda French may have gotten the story up to 1810 exactly right, although she expected first-person to recover in the nineteenth century. I expected a gradual decline of first-person to around 1810, and then a gradual recovery — so I seem to have been completely wrong.

Much more could be said about this result. You could decide that I’m wrong to let my classifier use things like numbers and relative pronouns as clues about point of view; we could restrict it just to counting personal pronouns. (That won’t change the result very significantly, as you can see in the illustration on the right — which also, incidentally, shows what happens in those first twenty years of the eighteenth century.) But we could refine the method in many other ways. We could exclude pronouns in direct discourse. We could break out epistolary narratives as a separate category.
All of these things should be tried. I’m explicitly not claiming to have solved this problem yet. Remember, the thesis of this talk is that we don’t understand literary history. In fact, I think the point of posing these questions on a large scale is partly to discover how slippery they are. I realize that to many people that will seem like a reason not to project literary categories onto a macroscopic scale. It’s going to be a mess, so — just don’t go there. But I think the mess is the reason to go there. The point is not that computers are going to give us perfect knowledge, but that we’ll discover how much we don’t know.
For instance, I haven’t figured out yet why numbers are common in first-person narrative, but I suspect it might be because there’s a persistent affinity with travel literature. As we follow up leads like that we may discover that we don’t understand point of view itself as well as we assume.
It’s this kind of complexity that will ultimately make classification interesting. It’s not just about sorting things into categories, but about identifying the places where a category breaks down or has changed over time. I would draw an analogy here to a paper on “Gender in Twitter” recently published by a group of linguists. They used machine learning to show that there are not two but many styles of gender performance on Twitter. I think we’ll discover something similar as we explore categories like point of view and genre. We may start out trying to recognize known categories, like first-person narration. But when you sort a large collection into categories, the collection eventually pushes back on your categories as much as the categories illuminate the collection.
Acknowledgments: This research was supported by the Andrew W. Mellon Foundation through “Expanding SEASR Services” and “The Uses of Scale in Literary Study.” Loretta Auvil, Mike Black, and Boris Capitanu helped develop resources for normalizing 18/19c OCR, many of which are public at usesofscale.com. Jordan Sellers developed the initial training corpus of 19c documents categorized by genre.

31 replies on “We don’t already understand the broad outlines of literary history.”
Boring question:
Your second chart shows a huge spike in number of volumes published under ‘fiction’ (threefold increase?) right at 1800. Both the first-person genre charts show a major discontinuity right at 1800. Are there just compositional changes in the dataset?
For example, a hypothetical bibliographical explanation might be: the University of Michigan shelves fiction before 1800 in a special collections library: U of Calif doesn’t; U of Mich collected more genre fiction; genre fiction is more third person. Does that seem less likely than a major, overnight shift in narrative styles?
Just checked this in Ngrams: by one useful proxy, capitalized university names, there is indeed a major shift in library composition in the “English Fiction” corpus exactly at 1800 in Ngrams: California bookplates don’t exist in Ngrams fiction before 1800, but Michigan bookplates do. (The numbers are extremely small, but not all books from the library will have the bookplate).
It’s possible that this is a side-effect of some change in library selection practices; I can’t rule that out yet. But it would have to be a rather large change, and a sustained one. I do think it’s likely that there’s some relation between the increased volume of fiction around 1800 and the increased reliance on third-person, but if you asked me to wager, I would put my money on a literary rather than bibliographical explanation.
Incidentally, I suspect Google’s “English fiction” corpus isn’t comparable to what I’m working with here — because when I asked Harvard researchers about the composition of that dataset a couple of years ago, they conceded that it probably contained a fair amount of critical prose. I’m not sure how the “English fiction” corpus was selected, but when I graph first- and third-person pronouns in that corpus, I don’t see a pattern comparable to what I show in my final graph above.
http://books.google.com/ngrams/graph?content=%28I+%2B+me%29+%2F+%28he+%2B+him+%2B+her%29&year_start=1700&year_end=1900&corpus=16&smoothing=3&share=
Ooh, I should find something to bet. What’s setting off alarm bells for me is discontinuous change almost exactly at 1800. If it were at 1815, or smooth, I’d be less suspicious. But if you ignore the loess, this looks pretty much like a step function. (Although possibly at 1795? If so, I’m probably wrong.)
Yeah, Google Fiction’s not the best proxy–thought I think it’s probably closer than the full Google set to what you have. But Hathi’s directly checkable, if not Hathi fiction: so… This is what I mean: some libraries (Harvard, NYPL) double their contributions from 1799 to 1801, and some (Princeton, Michigan) don’t. I suspect that’s only a manifestation of lots of other rules underneath about how university librarians have drawn arbitrary rules about the year 1800—some of which have got to be involved in the increase in fiction from 1795 to 1805 (much larger than Hathi’s overall increase) if not the first-person change.
I do know what you mean about “step” functions. I hate to see them, and you can bet I’m going to be scrutinizing the data on either side of 1800. I actually woke up at 6 this morning and ran the raw “pronoun” ratio as a check, because I was terrified about oversights. For whatever it’s worth, the biggest “step” seems to take place at slightly different places in the two graphs. In the second graph (with raw pronoun ratios rather than classifier predictions), it’s in the slice 1795-99. (Each slice is plotted at its “floor” year.) I’ll keep scouring …
YES. We don’t know. For several years now my basic line has been that we don’t have descriptive control over our texts. Even at the level of close analysis of hand-picked individual texts, we don’t have descriptive control.
Some years ago I read an essay by Monika Fludernik where she examined scene transitions in 50 British texts from medieval to early 20th century. She discovered a progression from explicitly signaled transitions–”And now we leave X and go to Y”–to implicit transitions where, upon a chapter break, the scene shifts from one place to another with no explicit marker. Rather, the reader is left to infer such a shift from what’s said.
It seems plausible enough, but 50 texts is only 50 texts and when they are hand-picked from the canon, well, maybe such a transition is broad and general and maybe it’s an artifact of a hand-picked sample. Though it’s likely to be tricky, it seems to me that text mining might help here.
And maybe the list of relevant features numbers in the 100s. Some will be amenable to current text mining methods, some not. But I do think there’s lots of work to do.
Idea that is conceptually interesting but/and more computationally complex and probably doesn’t improve anything: Elson, Dames, and McKeown reported a few years back that they could differentiate first- from third-person narration based on the size and degree of the algorithmically extracted social network in a text. Could be another approach to the same problem and/or a way to compare baseline results. The paper is at http://www.cs.columbia.edu/~delson/pubs/ACL2010-ElsonDamesMcKeown.pdf; my discussion at http://wp.me/pl9RM-aJ.
Thanks, Matt — I had read that but forgotten it, and it might do a lot to explain otherwise puzzling things. Like, why does third-person narration tend to lean more heavily on words for social relationships (husband, daughter)?
[…] * Ted Underwood on text-mining: We don’t already know the broad outlines of literary history. […]
I see a bit of a conceptual or perhaps terminological issue here. On the one hand, you make a credible case that there are new facts and new knowledge to be uncovered with computational tools–a claim I agree with, and with which I agreed beforehand. But then you say that this new knowledge is something you call “literary history,” whose broad outlines you say “we don’t know.” But scholars and writers have known something they called literary history, and even worse, have operated as if that something were fact. Obviously limited both by canon formation and tool (and cognitive) limitations, scholars and perhaps even more importantly writers have operated as if what was in print, easily available, etc., does constitute literary history.
I think the danger is in trying to map what you are discovering onto that existing category of literary history. We know from notebooks, prefaces, speeches, and many other sources what writers like James, Eliot, Joyce, etc., thought literary history was. They knew very little of that corpus that is now found in the Hathi Trust.
The connection between the new knowledge/facts you are uncovering and the practice of both writers and scholars seems to me to require more nuance than you’ve allowed here. Among other things, the category of “the literary” has at times been thought to map not onto “all and only the novels, plays and poems that exist” but “the canon of works we [whoever we are] consider ‘literature.'” In many cases, we do have a pretty good sense of what goes on in that narrow, limited, but also highly interactive body (that is, the authors read each other as time passed, knowing of their predecessors, etc.)
So let’s suppose, for example, that Auerbach were alive and wanted to rewrite Mimesis. Would his work be more authoritative if he chose all writing, including works by many people who remain, even now, largely unread? Or is the very fact of the interconnected knowledge of other writers part of what makes his story compelling? I think Auerbach did “know literary history” in an absolutely critical sense, and that it’s a bit too far to suggest that he (as part of “we”) didn’t really know his subject matter. The history of writing is complex and fascinating, but that doesn’t meant it’s the same thing as what we’ve called “literary history.”
I agree. Part of the reason we haven’t asked these seemingly basic questions is that our discipline had a basically evaluative goal for much of its 19c/20c history.
On the other hand, the concept of literariness we’re talking about doesn’t run back forever. E.g., in the early 18c “literature” meant writing in general, or learning in general. It didn’t mean “fictive works set apart from other writing by imaginative intent and aesthetic mastery.”
But the bottom line is, I agree that “literary history” is a fraught and difficult term, because “literature” means profoundly different things at different points in “literary” history. So perhaps, technically, we can’t even know whether we understand literary history. 🙂
I should note that in conversation at Univ. Nebraska – Lincoln, Laura White pointed out that Austen initially wrote Pride and Prejudice as an epistolary novel and redrafted it in the third person almost exactly at the moment where my graphs show a sudden shift in that direction. This seems to me a nice instance of the way focused, biographical studies and “distant reading” can usefully complement each other. I tend to suspect that innovations like free indirect discourse made third-person-omniscient more flexible and created a basically new equilibrium that favored it over first-person.
I tend to suspect that innovations like free indirect discourse made third-person-omniscient more flexible and created a basically new equilibrium that favored it over first-person.
What I like about about this line of thought is that it suggests a fundamentally aesthetic account of the change-over. It might also be useful to undertake a careful comparative description and analysis of the epistolary draft with the published version.
[…] has an interesting post on text mining and what is being called “distant reading,” “We Don’t Already Know the Broad Outlines of Literary History.” His blog is The Stone and the Shell: Historical Questions Raised by a Quantitative Approach to […]
[…] We don’t already know the broad outlines of literary history. (tedunderwood.com) […]
I’m a student at UNL, but unfortunately I missed this talk. Pity… it looks really interesting.
While I’m not really a literary expert in any capacity, I do quite a bit of computational analysis on chemical systems. Given my experience in some somewhat analogous data analysis, I noticed two things, please forgive me if they are misguided or elementary due to a lack of literary knowledge:
1) Prior to 1800, not only does the probability of classification change, but your standard deviation seems to skyrocket. Do you know why this is yet? Offhand, I’d be tempted to accuse the algorithms of getting muddled in changing vocabulary or grammatical norms, but it may very well be actual spread of the literature. I really have no appreciable experience with 18th century (or earlier) literature, so my guess may be way off the mark.
2) Your confusion matrix is very impressive; you’re predicting with 95% confidence or so. I was wondering though, have you so far only used single word identifiers? If phrases or context (such as constraining the analysis to words outside of quotations) where included, you might get even better results. I’m saying this because pronoun coupling with certain verbs might correlate with greater distinction than just the pronouns themselves, especially if you could normalize for such entities as direct quotation which may be first-person text within a third-person narrative (being that the character is speaking in first person). It would also be useful if the algorithm could search for keys like the protagonist’s name, but I don’t know how that could be used without manual input, which kind of ruins the point.
Either way, this write-up was very interesting and informative; I really look forward to this research in the future. I’m now daydreaming about algorithms which could identify influential authors and regional trends.
Yes, the standard deviation is higher in the eighteenth century because average sample size is much smaller. (Fewer books, and especially fewer works of fiction, were published in each five-year interval, so there’s greater variability.)
Also, yes, it would be nice to be able to exclude “direct discourse” — directly quoted speech. There are smaller corpora where that will be possible. It might also be nice to use bigrams, as you suggest. I would tend to frame these refinements less as a matter of “increasing accuracy” than as a way of exploring different possible definitions of “point of view.” I can imagine valid reasons to include or exclude narratorial asides, direct discourse, and so on — ideally, we’d do it both ways and compare.
I recently just graduated from my undergrad so I’m not sure that I can add anything stunningly intellectual to this conversation just yet. I do think that these are really interesting questions and are things that I have never thought about before. If we would allow the computers to do a lot of our heavy lifting, I think we would find questions we never knew we had and answers that astounded us. Hopefully, as the humanities shift towards a more digital discipline, we will see more scholars asking these same/similar questions.
I continue to think about the shift towards third person in the nineteenth century (as this is the area I will pursue in graduate school) and I want to know what it means. I keep making up stories about industrialization, identity, and urbanization in my mind as a way of explaining this sudden shift in narrative form. I can’t be sure that it’s true but I don’t think I would be able to rule it out.
Congrats on graduation. Right now, I’m also “making up stories” to explain this shift. I trust some 19c grad students will come along to help us explain it!
Thank you! I hope I’ll be able to make some impact on these types of questions once I finally get to graduate school. I think that we need to understand these types of questions because we don’t yet know the questions that this new information could unearth. We could discover aspects of “literary history” that we weren’t even aware existed… and that’s very exciting!
Which is to say, new empirical discovers create the need for new theories, perhaps even new modes of theorizing.
A lively and enlivening talk with some extremely interesting debate. David Perkins in his book “Is Literary History Possible?” (Baltimore, 1992) has many pertinent arguments to advance about the philosophical permeability of traditional literary-historical categories. He also offers to explain the aporia that arises from attempting to historicize certain kinds of printed material (literary works) whose literariness is defined by its unsusceptibility to objective appraisal. A literary history is by its nature a contradiction in terms because works of literature, while created at some point in the past, exist meaningfully as literature only within the present. Such works are perpetually re-created as literature with each successive re-reading, this constituting a re-enactment in the present of a past experience that is now dead and gone with its author but remains available for re-creation via the printed page. There are many associated versions of this thought that pervade the philosophy of history as it applies to the history of texts, and profoundly important work by Gadamer, Jauss, and Ricoeur have much of value to say. In grappling with the aims, outcomes, and methods of a computerized analysis of a literary corpus, it appeared to me that a further philosophical nuancing of historical textuality would enhance the current research and help mediate its findings usefully to a highly theorized current discipline of literary studies.
Philip Smallwood,
University of Bristol
Thanks, Philip. As a Romanticist, I have a high regard for David Perkins, and I believe I glanced at ‘Is Literary History Possible?’ long ago in another life. I’ll take a second look.
[…] Underwood makes a case for the use of DH methods to help us revisit and refine our categories and macro-narratives of […]
[…] Mit Blick auf die geisteswissenschaftliche Forschung mit vor allem (aber nicht nur!) Methoden der Computerlinguistik scheinen wir uns im Moment in einer Phase der spielerischen Entdeckung zu befinden. Häufig zu hören ist der Vorwurf, mit Technik spielen zu wollen ohne dabei ein ernsthaftes, begründbares geisteswissenschaftliches Forschungsinteresse zu verfolgen. Momentan werden Forschungsprogramme erst noch sondiert, sie existieren noch nicht. Ein Beispiel hierfür ist Ted Underwoods Artikel “We don’t already understand the broad outlines of literary history” […]
[…] Hayles has a lot to say about this in her How We Think ,Ted Underwood talks some about that here, and of course Franco Moretti’s Graphs, Maps, Trees thinks about it some more). As befits a […]
[…] Underwood, Ted. 2013. “We Don’t Already Understand the Broad Outlines of Literary History.” The Stone and the Shell (blog). February 8. https://tedunderwood.com/2013/02/08/we-dont-already-know-the-broad-outlines-of-literary-history/ […]
[…] questions over longer time frames and/or in larger data collections. Jo Guldi, David Armitage, Ted Underwood, and others have written about what it means for scholars to have ever-growing source material to […]
[…] https://tedunderwood.com/2013/02/08/we-dont-already-know-the-broad-outlines-of-literary-history/ […]
[…] see through your frustration how bounded and particular the codes and frames of your perspective have always been. Just as digitization has not de-materialized the humanities, but rather brought its material basis […]
[…] this might well be it. Yesterday, I was whining to a mechanical engineer of my acquaintance about Underwood’s observations of the reluctance in the Academy to embrace digital technologies, how they fear a […]