
Although methods of analysis are more fun to discuss, the most challenging part of distant reading may still be locating the texts in the first place [1].
In principle, millions of books are available in digital libraries. But literary historians need collections organized by genre, and locating the fiction or poetry in a digital library is not as simple as it sounds. Older books don’t necessarily have genre information attached. (In HathiTrust, less than 40% of English-language fiction published before 1923 is tagged “fiction” in the appropriate MARC control field.)
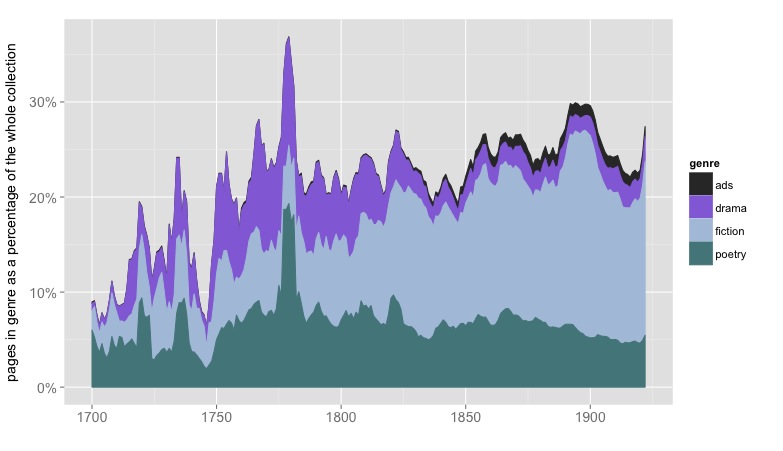
Volume-level information wouldn’t be enough to guide machine reading in any case, because genres are mixed up inside volumes. For instance Hoyt Long, Richard So, and I recently published an article in Slate arguing (among other things) that references to specific amounts of money become steadily more common in fiction from 1825 to 1950.
![Frequency of reference to "specific amounts" of money in 7,700 English-language works of fiction. Graphics from Wickham, ggplot2 [2].](https://tedunderwood.com/wp-content/uploads/2014/12/finalfreq.jpeg)
But Google’s “English Fiction” collection tells a very different story. The frequencies of many symbols that appear in prices (dollar signs, sixpence) skyrocket in the late nineteenth century, and then drop back by the early twentieth.
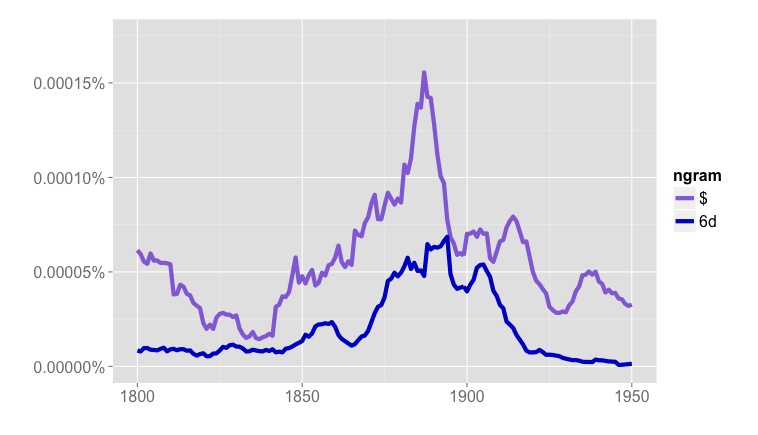
On the other hand, several other words or symbols that tend to appear in advertisements for books follow a suspiciously similar trajectory.
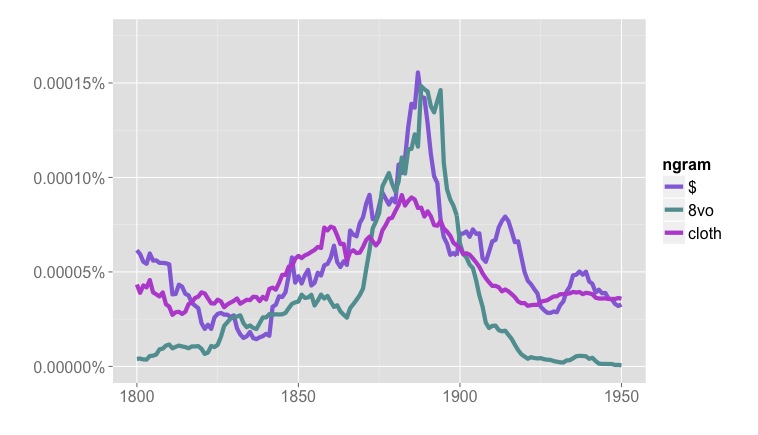
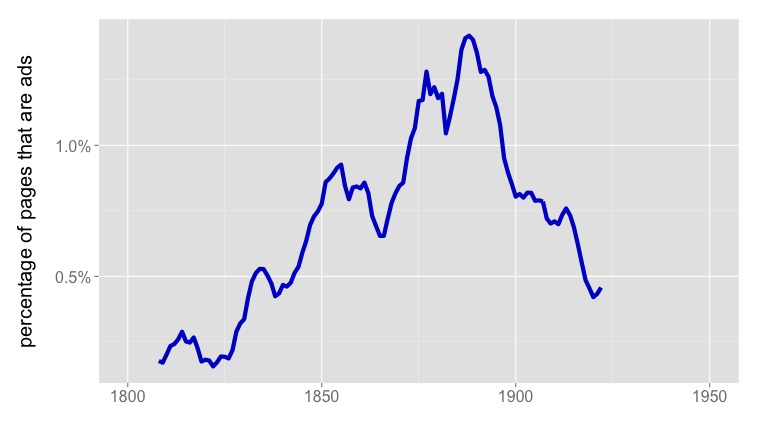
What we see in Google’s “Fiction” collection is something that happens in volumes of fiction, but not exactly in the genre of fiction — the rise and fall of publishers’ catalogs in the backs of books [3]. Individually, these two- or three-page lists of titles for sale may not look like significant noise, but because they often mention prices, and are distributed unevenly across the timeline, they add up to a significant potential pitfall for anyone interested in the role of money in fiction.
I don’t say this to criticize the team behind the Ngram Viewer. Genre wasn’t central to their goals; they provided a rough “fiction” collection merely as a cherry on top of a massively successful public-humanities project. My point is just that genres fail to line up with volume boundaries in ways that can really matter for the questions scholars want to pose. (In fact, fiction may be the genre that comes closest to lining up with volume boundaries: drama and poetry often appear mixed in The Collected Poems and Plays of So-and-So, With a Prose Life of the Author.)
You can solve this problem by selecting works manually, or by borrowing proprietary collections from a vendor. Those are both good, practical solutions, especially up to (say) 1900. But because they rely on received bibliographies, they may not entirely fulfill the promises we’ve been making about dredging the depths of “the great unread,” boldly going where no one has gone before, etc [4]. Over the past two years, with support from the ACLS and NEH, I’ve been trying to develop another alternative — a way of starting with a whole library, and dividing it by genre at the page level, using machine learning.
In researching the Slate article, we relied on that automatic mapping of genre to select pages of fiction from HathiTrust. It helped us avoid conflating advertisements with fiction, and I hope other scholars will also find that it reduces the labor involved in creating large, genre-specific collections. The point of this blog post is to announce the release of a first version of the map we used (covering 854,476 English-language books in HathiTrust 1700-1922).
The whole dataset is available on Figshare, where it has a DOI and is citable as a publication. An interim report is also available; it addresses theoretical questions about genre, as well as questions about methods and data format. And the code we used for the project is available on Github.
For in-depth answers to questions, please consult the interim project report. It’s 47 pages long; it actually explains the project; this blog post doesn’t. But here are a few quick FAQs just so you can decide whether to read further.
“What categories did you try to separate?”
We identify pages as paratext (front matter, back matter, ads), prose nonfiction, poetry (narrative and lyric are grouped together), drama (including verse drama), or prose fiction. The report discusses the rationale for these choices, but other choices would be possible.
“How accurate is this map?”
Since genres are social institutions, questions about accuracy are relative to human dissensus. Our pairs of human readers agreed about the five categories just mentioned for 94.5% of the pages they tagged [5]. Relying on two-out-of-three voting (among other things), we boiled those varying opinions down to a human consensus, and our model agreed with the consensus 93.6% of the time. So this map is nearly as accurate as we might expect crowdsourcing to be. But it covers 276 million pages. For full details, see the confusion matrices in the report. Also, note that we provide ways of adjusting the tradeoff between recall and precision to fit a researcher’s top priority — which could be catching everything that might belong in a genre, or filtering out everything that doesn’t belong. We provide filtered collections of drama, fiction, and poetry for scholars who want to work with datasets that are 97-98% precise.
“You just wrote a blog post admitting that even simple generic boundaries like fiction/nonfiction are blurry and contested. So how can we pretend to stabilize a single map of genre?”
The short answer: we can’t. I don’t expect the genre predictions in this dataset to be more than one resource among many. We’ve also designed this dataset to have a certain amount of flexibility. There are confidence metrics associated with each volume, and users can define their collection of, say, poetry more broadly or narrowly by adjusting the confidence thresholds for inclusion. So even this dataset is not really a single map.
“What about divisions below the page level?”
With the exception of divisions between running headers and body text, we don’t address them. There are certainly a wide range of divisions below the page level that can matter, but we didn’t feel there was much to be gained by trying to solve all those problems at the same time as page-level mapping. In many cases, divisions below the page level are logically a subsequent step.
“How would I actually use this map to find stuff?”
There are three different ways — see “How to use this data?” in the interim report. If you’re working with HathiTrust Research Center, you could use this data to define a workset in their portal. Alternatively, if your research question can be answered with word frequencies, you could download public page-level features from HTRC and align them with our genre predictions on your own machine to produce a dataset of word counts from “only pages that have a 97% probability of being prose fiction,” or what have you. (HTRC hasn’t released feature counts for all the volumes we mapped yet, but they’re about to.) You can also align our predictions directly with HathiTrust zip files, if you have those. The pagealigner module in the utilities subfolder of our Github repo is intended as a handy shortcut for people who use Python; it will work both with HT zip files and HTRC feature files, aligning them with our genre predictions and returning a list of pages zipped with genre codes.
Is this sort of collection really what I need for my project?
Maybe not. There are a lot of books in HathiTrust. But as I admitted in my last post, a medium-sized collection based on bibliographies may be a better starting point for most scholars. Library-based collections include things like reprints, works in translation, juvenile fiction, and so on, that could be viewed as giving a fuller picture of literary culture … or could be viewed as messy complicating factors. I don’t mean to advocate for a library-based approach; I’m just trying to expand the range of alternatives we have available.
“What if I want to find fiction in French books between 1900 and 1970?”
Although we’ve made our code available as a resource, we definitely don’t want to represent it as a “tool” that could simply be pointed at other collections to do the same kind of genre mapping. Much of the work involved in this process is domain-specific (for instance, you have to develop page-level training data in a particular language and period). So this is better characterized as a method than a tool, and the report is probably more important than the repo. I plan to continue expanding the English-language map into the twentieth century (algorithmic mapping of genre may in fact be especially necessary for distant reading behind the veil of copyright). But I don’t personally have plans to expand this map to other languages; I hope someone else will take up that task.
As a reward for reading this far, here’s a visualization of the relative sizes of genres across time, represented as a percentage of pages in the English-language portion of HathiTrust.
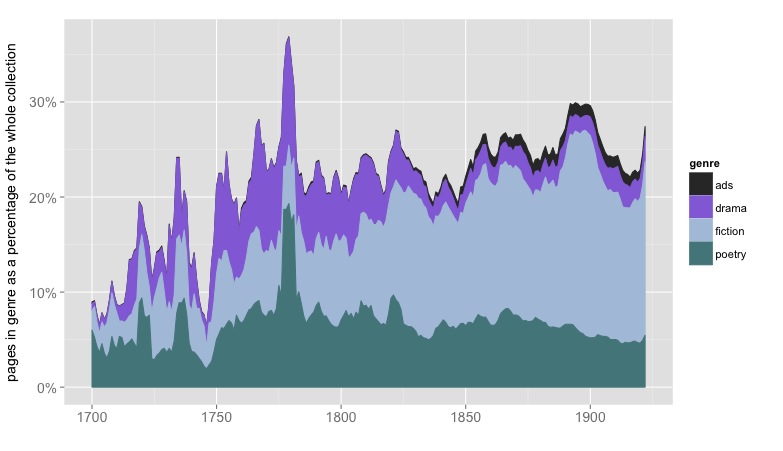
The image is discussed at more length in the interim progress report.
Acknowledgments
The blog post above often slips awkwardly into first-person plural, because I’m describing a project that involved a lot of people. Parts of the code involved were written by Michael L. Black and Boris Capitanu. The code also draws on machine learning libraries in Weka and Scikit-Learn [6, 7]. Shawn Ballard organized the process of gathering training data, assisted by Jonathan Cheng, Nicole Moore, Clara Mount, and Lea Potter. The project also depended on collaboration and conversation with a wide range of people at HathiTrust Digital Library, HathiTrust Research Center, and the University of Illinois Library, including but not limited to Loretta Auvil, Timothy Cole, Stephen Downie, Colleen Fallaw, Harriett Green, Myung-Ja Han, Jacob Jett, and Jeremy York. Jana Diesner and David Bamman offered useful advice about machine learning. Essential material support was provided by a Digital Humanities Start-Up Grant from the National Endowment for the Humanities and a Digital Innovation Fellowship from the American Council of Learned Societies. None of these people or agencies should be held responsible for mistakes.
References
[1] Perhaps it goes without saying, since the phrase has now lost its quotation marks, but “distant reading” is Franco Moretti, “Conjectures on World Literature,” New Left Review 1 (2000).
[2] Hadley Wickham, ggplot2: Elegant Graphics for Data Analysis. http: //had.co.nz/ggplot2/book. Springer New York, 2009.
[3] Having mapped advertisements in volumes of fiction, I’m pretty certain that they’re responsible for the spike in dollar signs in Google’s “English Fiction” collection. The collection I mapped overlaps heavily with Google Books, and the number of pages of ads in fiction volumes tracks very closely with the frequency of dollars signs, “8vo,” and so on.
[4] “The great unread” comes from Margaret Cohen, The Sentimental Education of the Novel (Princeton NJ: Princeton University Press, 1999), 23.
[5] See the interim report (subsection, “Evaluating Confusion Matrices”) for a fuller description; it gets complicated, because we actually assessed accuracy in terms of the number of words misclassified, although the classification was taking place at a page level.
[6] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
[7] Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, Peter Reutemann, and Ian H. Witten. The WEKA data mining software: An update. SIGKDD Explorations, 11(1), 2009.
