Language models have been compared to parrots, but the bigger danger is that they turn people into parrots. A student who asks for “a paper about Middlemarch,” for instance, will get a pastiche loosely based on many things in the model’s training set. This may not count as plagiarism, but it won’t produce anything new.
But there are ways to use language models actively and creatively. We can select evidence to be analyzed, put it in a prompt, and specify the questions to be asked. Used this way, language models can create new knowledge that didn’t exist when they were trained. There are many ways to do this, and people may eventually get quite creative. But let’s start with a familiar task, so we can evaluate the results and decide whether language models really help. An obvious place to start is “content analysis”—a research method that analyzes hundreds or thousands of documents by posing questions about specific themes.
Below I work through a simple example of content analysis using the OpenAI API to measure the passage of time in fiction (see this GitHub repo for code). To spoil the suspense: I find that for this task, language models add something valuable, not just because they’re more accurate than older ways of doing this at scale but because they explain themselves better.
Why measure time in fiction?
Researchers already have several good ways to automate content analysis. Named entity extraction addresses certain kinds of questions. Topic modeling addresses others.
But there are also tricky questions that remain hard to answer by counting words. In 2017, for instance, I started to wonder how much time passes, on average, across a page of a novel. Literary-critical tradition suggested that there had been a pretty stable balance between “scene” (minute-by-minute description) and “summary” (which may cover weeks or years) until modernists started to leave out the summary and make every page breathlessly immediate [1]. But when I sat down with two graduate students (Sabrina Lee and Jessica Mercado) to manually characterize a thousand passages from fiction, we found instead a long trend. The average length of time represented in 250 words of fiction had been getting steadily shorter since the early eighteenth century. There was a trend toward immediacy, in other words, but modernism didn’t begin the trend [2].

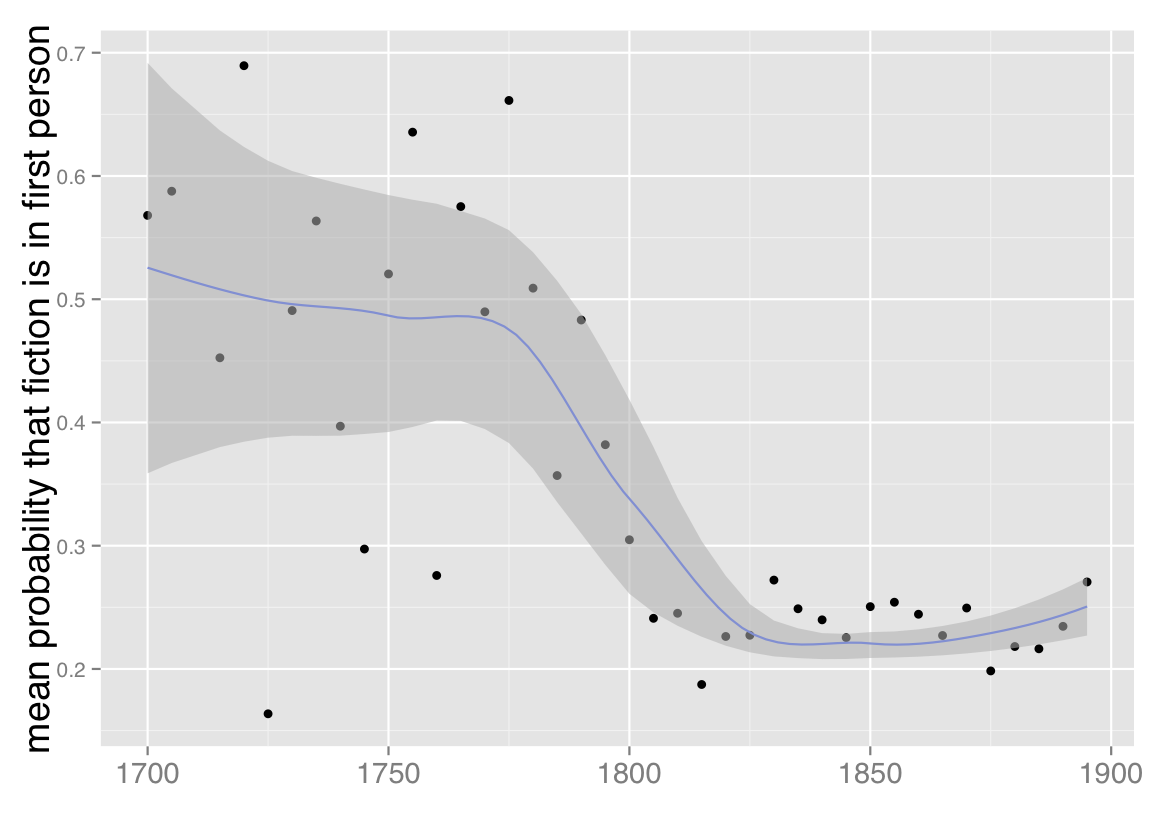
The average length of time described in 250 words of narration. Y axis is logarithmic. The shaded ribbon represents a 95% confidence interval for the dashed curve, which is itself calculated by loess regression. From Underwood, “Why Literary Time is Measured in Minutes,” p. 352.
How well do bag of-words methods estimate time?
We decided to characterize passages manually because references to time in fiction can’t always be taken literally. If a character thinks (or says) “wow, it’s been thirty years but feels like yesterday,” you don’t want to conclude that thirty years have passed on the page. So word-counting seemed risky. Even as human readers we often found it hard to decide how much time was passing. But when a passage was read by two different people, our estimates agreed with each other well enough to conclude that “fictive time” was a meaningful construct, if not a precise one (r = .74 on log-transformed durations).
A year after we published our paper, Greg Yauney showed that word-counting methods can do an acceptable job of estimating time [3]. He trained a bag-of-words model on the passages we had labeled, and applied it to a new set of passages labeled by new readers. The model-predicted durations correlated with human estimates at r = .35. While this is much lower than inter-human agreement, the model was stable enough to precisely measure a trend (across thousands of books) that matched the trend we had sketched using laborious human reading of a hundred books.

Replicating this on our old data, I get a slightly higher correlation between models and readers (r = .49 on log-transformed durations), perhaps because the data I’m using was produced by readers who compared notes for several weeks to maximize agreement. But since this is still lower than .74, bag-of-words models are definitely less good at estimating time than human readers.
Can we train LLMs to estimate time?
To get a large language model to answer a question, you first need to make sure it understands the question. As Simon Willison helpfully explains, the way to train a chat model through the API is to demonstrate the interaction you want by providing a series of imagined exchanges between a “user” and an “assistant” [4]. These aren’t real replies from the assistant but ego ideals you’re providing to teach it how to behave.
Here’s the instruction I had the “user” give:
Read the following passage of fiction. Then do five things.
1: Briefly summarize the passage.
2: Reason step by step to decide how much time is described in the passage. If the passage doesn't include any explicit reference to time, you can guess how much time the events described would have taken. Even description can imply the passage of time by describing the earlier history of people or buildings. But characters' references to the past or future in spoken dialogue should not count as time that passed in the scene. Report the time using units of years, weeks, days, hours, or minutes. Do not say zero or N/A.
3: If you described a range of possible times in step 2 take the midpoint of the range. Then multiply to convert the units into minutes.
4: Report only the number of minutes elapsed, which should match the number in step 3. Do not reply N/A.
5: Given the amount of speculation required in step 2, describe your certainty about the estimate--either high, moderate, or low.
The passage follows: <omitting this to save space>You’ll notice that I’m using chain-of-thought prompting, building slowly from summary to inference to an estimated number of minutes. You may also notice I tell the model twice “don’t reply N/A.” I found the model was pretty cautious about speculating and needed to be encouraged to make assumptions and guesses. But to be honest, it’s possible that the model was right to be cautious! Duration is hard to estimate in some cases, and maybe we humans should have allowed N/A responses when we did this.
Here’s an example of an ego-ideal reply I provided to teach the “assistant” how to respond. This was responding to a passage from The Big Sleep.
1: A detective wakes up 'the next morning,' looks out a window for an undefined time, drinks (and presumably needs to make) two cups of coffee, then shaves and showers and gets dressed before stepping out his front door and seeing a car.
2: Making coffee, showering, and getting dressed take at least an hour. There's some ambiguity about whether to count the implicit reference to yesterday (since this is 'the next morning') as time elapsed in the passage, but let's say no, since yesterday is not actually described. So, an hour to 90 minutes.
3: 1.25 hours have elapsed. Multiplying by 60 minutes an hour that's 75 minutes.
4: 75 minutes.
5: Low confidence, because of ambiguity about a reference to the previous day.Using some code generously shared by Quinn Dombrowski, I gave the model four query-reply sequences like this, then asked it to characterize a new passage with the same instructions.
To assess performance on this simple task, I just extracted the minutes reported in step 4 and compared them to our human estimates from 2017. Other forms of content analysis might require the model to edit or mark up the text provided in the prompt. That’s doable, but I thought I would start with something simple.
I added step 5 (allowing the model to describe its own confidence) because in early experiments I found the model’s tendency to editorialize extremely valuable. The answers to step 5 were also fun to read as replies scrolled up the page, because my new sorcerer’s assistant complained volubly about the ambiguity of its task. (“30 minutes. Low confidence, as the passage is more focused on the poetic and symbolic aspects of the scene rather than providing a clear sense of time.”). In some cases it refused the task altogether and threw the question about confidence back in my face. (“N/A. High confidence that no specific amount of time is described.”) This capacity for backtalk is a feature not a bug: I learned a lot from it.
But after I adjusted my prompt to address the ambiguities the assistant correctly pointed out, complete refusal to answer the question was rare.
How well does GPT-4 estimate time?
I had the Turbo model code 483 passages. Its predictions correlated with human estimates at r = .59. I only asked GPT-4 to code 121 passages (because it’s more expensive to run than Turbo), and it achieved r = .68. This is not as good as inter-human agreement (.74), but it’s closer to human readers than to bag of words models (.35 – .49). And of course GPT-4 does the work more quickly than human readers. It took the three of us several months to generate this data, but my LLM experiment was run in a couple of days. Plus, given an API, large language models are easier to use than other forms of machine learning: the main challenge is to describe your question systematically. This is a method that could realistically be used by researchers with relatively little programming experience.

The total cost to my OpenAI account was $22. Of that amount, about $8 was testing the prompts and running on the (cheaper) Turbo API. The final run on GPT-4 cost $14; if I had completely replicated our work from 2017 on GPT-4 it would have cost $140. So a project like this will not bankrupt researchers. But reliance on OpenAI is still a bad idea in the long run. Universities should develop their own models and APIs, both for reasons of institutional autonomy/survival (!!😬!!) and so that researchers can inspect and tune the models.
However, one could exaggerate the problems of interpretability created by a closed model. Watching the model think out loud about each passage actually gave me a better sense of how results were produced than I could extract from my own records of human research in 2017. (See below for an example from GPT-4: human readers don’t usually document their thought process this verbosely.) Also, because human beings can’t erase their own memories, it’s not possible for us to “repeat the same question with slightly different language.” If I try that on myself, I’m going to remember what I thought before and probably think it again. But a model can wake up each moment with eternal sunshine of the spotless mind.
ABRIDGED PASSAGE FROM Jane Eyre: And signs, for aught we know, may be but the sympathies of Nature with man. When I was a little girl, only six years old, I one night heard Bessie Leaven say to Martha Abbot that she had been dreaming about a little child ... Of late I had often recalled this saying and this incident; for during the past week scarcely a night had gone over my couch that had not brought with it a dream of an infant, which I sometimes hushed in my arms, sometimes dandled on my knee, sometimes watched playing with daisies on a lawn, or again, dabbling its hands in running water. It was a wailing child this night, and a laughing one the next: now it nestled close to me, and now it ran from me; but whatever mood the apparition evinced, whatever aspect it wore, it failed not for seven successive nights to meet me the moment I entered the land of slumber.
ASSISTANT REPLIES. 1: The narrator recalls a saying about dreaming of children being a sign of trouble and remembers an incident from her childhood. She then describes her recent dreams of infants over the past week.
2: The passage mentions the narrator's childhood memory, which happened when she was six years old, and the past week of dreams. The time elapsed in the passage is the week of dreams.
3: 1 week has elapsed. At seven days a week that's 7 days. 24 hours in a day, so 168 hours. 60 minutes in an hour, so 10080 minutes.
4: 10080 minutes.
5: Moderate confidence, as the childhood memory is not counted as time passing in the scene.What no model can do
While I think large language models will be tremendously useful assistants in content analysis, I don’t think we can dispense with multiple human readers. As David Bamman explains in a good Twitter thread, the core challenges of this work are “a. coming up with a new construct to measure, b. demonstrating that it can be measured, and c. showing that there’s value in doing so.” Intersubjective agreement between human beings is still the only way to know that we have addressed those questions.
That’s why I wouldn’t feel comfortable just making up my own definition of, say, “suspense,” teaching a model to measure it, and then running the model across a thousand books. The problem with that approach is not that LLMs have measurement error. (As we’ve seen in Greg Yauney’s paper, measurement methods with much more error can be productive.) The problem is that it isn’t clear what a single researcher’s construct means in the first place. To be confident that we’re measuring something called “suspense” we need to show that multiple people recognize it as suspense. And in spite of all the rhetorical personification in this blog post (which I trust you have understood rhetorically), a model is not a separate person. So a project of this kind still needs to start by getting several human beings to read systematically and compare notes, before the human codebook is translated into a prompt.
On the other hand, I do think language models will allow us to pose questions that are currently hard to pose at scale. Questions about plot and character, for instance, require reading a whole book while applying delicate decision criteria that may be hard to remember and keep stable across many books. Language models will help here not just because they’re fast, but because they can provide a relatively stable yardstick by which to measure slippery concepts, even at a modest scale of analysis.
This is a preliminary report on a very strange world. For me, the most surprising take-away from this experiment was not that deep learning is more accurate than statistical NLP, but that it may also be in some ways more interpretable. Because a language model has to think out loud, it tends to automatically document its own reasoning. This is useful even when (or especially when) the model doesn’t think you’ve defined the construct it’s supposed to measure clearly enough.
References
[1] Gérard Genette, Narrative Discourse: An Essay in Method, trans. Jane E. Lewin (Ithaca: Cornell Univ. Press, 1980), 97.
[2] Ted Underwood, “Why Literary Time is Measured in Minutes,” New Literary History 85.2 (2018) 351-65.
[3] Greg Yauney, Ted Underwood, and David Mimno, “Computational Prediction of Elapsed Narrative Time” (2019).
[4] Simon Willison, “A Simple Python Wrapper for the ChatGPT API” (2023).