
Digital collections are vastly expanding literary scholars’ field of view: instead of describing a few hundred well-known novels, we can now test our claims against corpora that include tens of thousands of works. But because this expansion of scope has also raised expectations, the question of representativeness is often discussed as if it were a weakness rather than a strength of digital methods. How can we ever produce a corpus complete and balanced enough to represent print culture accurately?
I think the question is wrongly posed, and I’d like to suggest an alternate frame. As I see it, the advantage of digital methods is that we never need to decide on a single model of representation. We can and should keep enlarging digital collections, to make them as inclusive as possible. But no matter how large our collections become, the logic of representation itself will always remain open to debate. For instance, men published more books than women in the eighteenth century. Would a corpus be correctly balanced if it reproduced those disproportions? Or would a better model of representation try to capture the demographic reality that there were roughly as many women as men? There’s something to be said for both views.
 To take another example, Scott Weingart has pointed out that there’s a basic tension in text mining between measuring “what was written” and “what was read.” A corpus that contains one record for every title, dated to its year of first publication, would tend to emphasize “what was written.” Measuring “what was read” is harder: a perfect solution would require sales figures, reviews, and other kinds of evidence. But, as a quick stab at the problem, we could certainly measure “what was printed,” by including one record for every volume in a consortium of libraries like HathiTrust. If we do that, a frequently-reprinted work like Robinson Crusoe will carry about a hundred times more weight than a novel printed only once.
To take another example, Scott Weingart has pointed out that there’s a basic tension in text mining between measuring “what was written” and “what was read.” A corpus that contains one record for every title, dated to its year of first publication, would tend to emphasize “what was written.” Measuring “what was read” is harder: a perfect solution would require sales figures, reviews, and other kinds of evidence. But, as a quick stab at the problem, we could certainly measure “what was printed,” by including one record for every volume in a consortium of libraries like HathiTrust. If we do that, a frequently-reprinted work like Robinson Crusoe will carry about a hundred times more weight than a novel printed only once.
We’ll never create a single collection that perfectly balances all these considerations. But fortunately, we don’t need to: there’s nothing to prevent us from framing our inquiry instead as a comparative exploration of many different corpora balanced in different ways.
For instance, if we’re troubled by the difference between “what was written” and “what was read,” we can simply create two different collections — one limited to first editions, the other including reprints and duplicate copies. Neither collection is going to be a perfect mirror of print culture. Counting the volumes of a novel preserved in libraries is not the same thing as counting the number of its readers. But comparing these collections should nevertheless tell us whether the issue of popularity makes much difference for a given research question.
I suspect in many cases we’ll find that it makes little difference. For instance, in tracing the development of literary language, I got interested in the relative prominence of words that entered English before and after the Norman Conquest — and more specifically, in how that ratio changed over time in different genres. My first approach to this problem was based on a collection of 4,275 volumes that were, for the most part, limited to first editions (773 of these were prose fiction).
But I recognized that other scholars would have questions about the representativeness of my sample. So I spent the last year wrestling with 470,000 volumes from HathiTrust; correcting their OCR and using classification algorithms to separate fiction from the rest of the collection. This produced a collection with a fundamentally different structure — where a popular work of fiction could be represented by dozens or scores of reprints scattered across the timeline. What difference did that make to the result? (click through to enlarge)
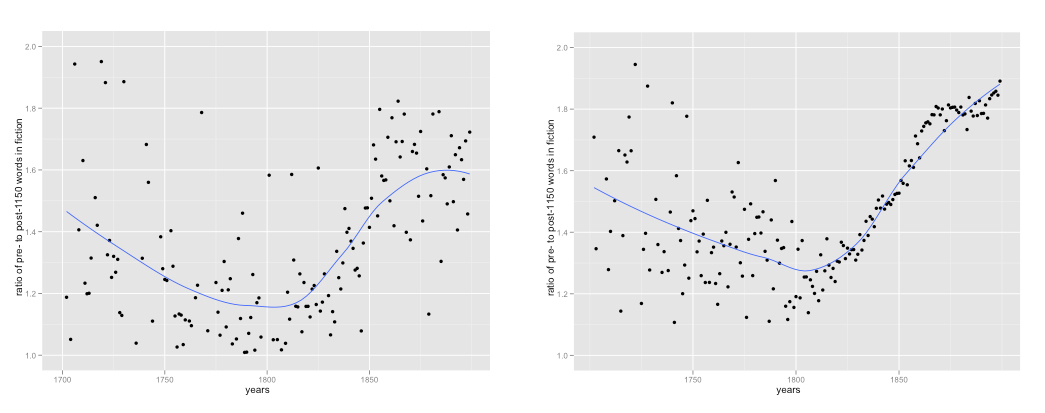
It made almost no difference. The scatterplots look different, of course, because the hand-selected collection (on the left) is relatively stable in size across the timespan, and has a consistent kind of noisiness, whereas the HathiTrust collection (on the right) gets so huge in the nineteenth century that noise almost disappears. But the trend lines are broadly comparable, although the collections were created in completely different ways and rely on incompatible theories of representation.
I don’t regret the year I spent getting a binocular perspective on this question. Although in this case changing the corpus made little difference to the result, I’m sure there are other questions where it will make a difference. And we’ll want to consider as many different models of representation as we can. I’ve been gathering metadata about gender, for instance, so that I can ask what difference gender makes to a given question; I’d also like to have metadata about the ethnicity and national origin of authors.
 But the broader point I want to make here is that people pursuing digital research don’t need to agree on a theory of representation in order to cooperate.
But the broader point I want to make here is that people pursuing digital research don’t need to agree on a theory of representation in order to cooperate.
If you’re designing a shared syllabus or co-editing an anthology, I suppose you do need to agree in advance about the kind of representativeness you’re aiming to produce. Space is limited; tradeoffs have to be made; you can only select one set of works.
But in digital research, there’s no reason why we should ever have to make up our minds about a model of representativeness, let alone reach consensus. The number of works we can select for discussion is not limited. So we don’t need to imagine that we’re seeking a correspondence between the reality of the past and any set of works. Instead, we can look at the past from many different angles and ask how it’s transformed by different perspectives. We can look at all the digitized volumes we have — and then at a subset of works that were widely reprinted — and then at another subset of works published in India — and then at three or four works selected as case studies for close reading. These different approaches will produce different pictures of the past, to be sure. But nothing compels us to make a final choice among them.

9 replies on “Distant reading and representativeness.”
Very nice.
I note that biologists have similar issues. Most of the living species haven’t even been named and classified, let alone investigated in any detail. There’s no reason to think that we’ve studied a representative sample.
And the fossil record is patchy. Several times in the past few years I’ve read articles about a new fossil that forces a revision of a significant region of the existing taxonomy. And then there’s the specific case of our pre-human ancestors. What we know about them is based on a handful of skeletal remains. The total number of individuals involved is no more than 1000s. There’s no reason to think that they are a representative sample of the millions of individuals in those populations.
We just have to do the best we can with the tools and objects available.
Yes. In fact, when you put it like that, people who work on printed books have it really easy.
Somehow I just stumbled on this today; I’m glad you’ve finally put your thoughts of this into a blog post so I can reference it!
The issue some of us (read: me) have with representativeness is not whether or not the dataset is fully representative of some aspect of the past, but that often, we don’t know what the dataset is representative of (e.g. Ben’s patchwork libraries http://sappingattention.blogspot.com/2013/03/patchwork-libraries.html). The contingent historical processes of selecting and editing and digitizing are a carnival house of mirrors which ultimately distorts the data in ways we cannot expect. We hope that the data are distorted in unsystematic ways, but if there are systematic biases, so too will they be present in our analyses.
All of this is a round-about way of saying that it is unwise to analyze an entire collection, because it’s difficult to know systematic shifts in perspective have crept in. That said, if you cut the Big Collection into smaller collections and compare them against one another, only looking at the deltas (does poetry have *more* figurative language than prose?) rather than the hard numbers, confidence in the statistical validity of the results based on what you *think* the data represents is greatly increased. That’s why the HTRC will be so powerful, and why they should adopt the idea your proposed last year to allow users to create their own collections.
I think I largely agree with you here.
Floating beneath the surface of my post is an implication that there actually is no single clearly-defined object we’re supposed to be “representing.” Which implies that the task we’re engaged in might better be understood as a comparative one (“looking at the deltas.”)
I’m not quite ready to formalize that as a rule — in part because my experience has been that you often do, after all, get the same result in collections selected very, very differently. But comparative questions are definitely where I find it easiest to make persuasive arguments. Looking at print culture as a whole to conclude “in the 20c, writers became happier and more individualistic!” seems to invite fallacies of composition or presentism. It seems more useful to ask “how did Genre A differ from Genre B, and how did that difference change over time?” Which is, like you suggest, about chopping collections into parts. I guess the place where I differ a bit from your emphasis, and maybe from Ben’s in that recent post, is that I would prefer to frame this as a necessary fact about representation itself rather than a contingent accident caused by the imperfection of our sampling methods or of library collections.
One problem I do see (to recur to the theme of a recent tweet) is that editors of magazines seem to prefer to print headlines framed in absolute rather than appropriately relativized and internally-comparative terms. E.g. “Scholars: 20thc happier, more individualistic than the 19th.” But here I’m just grousing idly; if we actually want to change that emphasis, I guess it’s up to us to write the articles.
Re HathiTrust Research Center: they absolutely are going to let scholars form their own collections. Stay tuned …
[…] I do wonder a bit about these notions of representativeness (a point also often brought up by Ted Underwood, Ben Schmidt, and Jockers himself). This is probably something lit-researchers worked out in the […]
[…] is by no means a novel question. Ted Underwood, Matt Jockers, Ben Schmidt, and I had an ongoing discussion on corpus representativeness a few years back, and it’s been continuously pointed to by corpus linguists 6 and literary historians for some […]
[…] There has also been a debate taking place in DH across blogs and twitter about ‘validity’ and ‘representativeness’ when it comes to analysing a large corpus of texts (such as Google Books or Hathi Trust). A number of our own discussions have revolved around the representativeness of the corpus of eighteenth-century titles or works you have created in workshops and the validity of the analyses you have produced. A good place to start is Scott Weingart’s blog essay ‘Not Enough Perspectives I’. You don’t necessarily have to follow up on all the links, but check out his valuable comments on ‘The Great Unread’ (pace Franco Moretti), ‘Tsundoko’ (Japanese word for an ever-increasing pile of books bought but not read), and ‘the Forgotten Read’. See also Ted Underwood’s earlier post ‘Distant Reading and Representativness’. […]
[…] what was published, and what was read. He also noted a conversation from a few years ago that Ted Underwood documented, and drew attention to Heather Froelich, who does lots of careful thinking about issues […]
[…] Ted Distant Reading and Representativeness, 2013. [Online] Available from: https://tedunderwood.com/2013/04/01/distant-reading-and-representativeness/ [Accessed 10 May […]