Ted Underwood and David Bamman
1500-word abstract of a paper delivered Sat, Jan 9th, at MLA 2016, in a panel with Deidre Lynch and Andrew Piper. (An article based on this research, and further research with Sabrina Lee, will appear in Cultural Analytics in early 2018.)
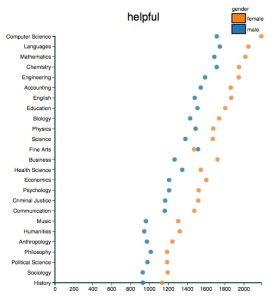 By visualizing course evaluations, Ben Schmidt has reminded us how subtly (and irrationally) descriptions of real people are shaped by gendered expectations. Men are praised for being funny, and condemned for being boring. Women are praised for being helpful, and condemned for being strict.
By visualizing course evaluations, Ben Schmidt has reminded us how subtly (and irrationally) descriptions of real people are shaped by gendered expectations. Men are praised for being funny, and condemned for being boring. Women are praised for being helpful, and condemned for being strict.
Fictional characters are never simply imagined people; they’re also aspects of novelistic form (Lynch 1998). But gendered patterns of description do appear in fiction, and it might be interesting to know how those patterns have changed. This also happens to be a problem where natural language processing can help us, since English pronouns have grammatical gender. (The gender of “me” is a trickier problem; for the purposes of this paper, we have regretfully set first-person narrators aside.)
We used BookNLP (a pipeline developed in Bamman et al. 2014a) to identify characters and the words connected to them. We applied it to 45,000 works of fiction distributed (unevenly) over the period 1780-1989. (The works themselves were partly drawn from HathiTrust and partly located at the Chicago Text Lab.) BookNLP does make errors (Vala et al., 2015), and any analysis on this scale will miss a great deal that is implied rather than said. But readers are so interested in character that it may be worth putting up with some gaps and uncertainties in order to glimpse broad historical patterns.
We asked, first, how strongly characterization is shaped by gender, and how that pressure waxed or waned across time. For instance, if you didn’t have names or pronouns, or tautological clues like “her Ladyship” and “her girlhood,” how easy would it be to infer a character’s (grammatical) gender from the apparently-genderless verbs, nouns, and adjectives associated with her?
One way to find out is to train a model to predict gender just from those implicit clues, testing it against the ground truth established by pronouns. When we do this, a long-term trend is perceptible: the linguistic differences between male and female characters get clearer to the middle of the nineteenth century, and then slowly get blurrier, through at least the 1980s.
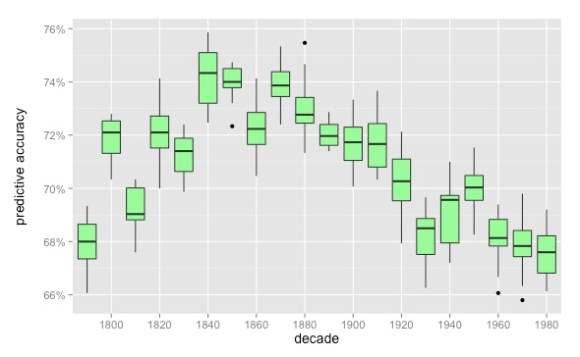
It’s not a huge or dramatic shift, partly because gender is never easy to infer in the first place. (Since the model could get 50% of the characters right by guessing randomly, 74% is not eagle-eyed. Of course, the median character was only associated with 51 words, which is not a lot of evidence to go on.)
There are also questions about the data that make it difficult to be confident about details. We have sparse data before 1810, so we’re not certain yet that gender was really less clearly marked in the eighteenth century — although Virginia Woolf does tell us that “the sexes drew further and further apart” as the nineteenth century began (Woolf 1992: 219).
Also, after 1923, our dataset gets a little more American and a little better at excluding reprints, so the apparent acceleration of change from 1910 to 1930 might partly reflect changes in the corpus. In the final draft, we plan to check multiple corpora against each other. But we don’t have much doubt about the broad trend from 1840 to 1989. Over that century and a half, the boundary that separates “men” and “women” in fiction does seem to get blurrier and blurrier.
What were the tacit patterns that made it possible to predict a character’s gender in the first place, and how did they change? That’s a big question; there’s room here for several decades of discussion.
But some of the broadest patterns are easy to grasp. For each word, you can measure the difference between its frequency in descriptions of women and of men. (In the graphs below, words above zero are more common in descriptions of women.) Then you can sort the words to find ones where the difference between genders is large early in the period, and declines over time.
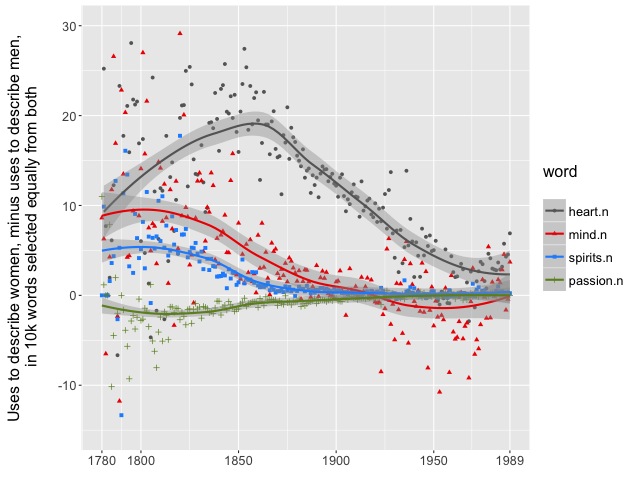 When you do that, you find a lot of words that describe subjective consciousness and emotion; most of them are attributed to women. “Passion” is an exception used more often for men; of course, in the early nineteenth century, it often means “lust.”
When you do that, you find a lot of words that describe subjective consciousness and emotion; most of them are attributed to women. “Passion” is an exception used more often for men; of course, in the early nineteenth century, it often means “lust.”
This evidence tends to support Nancy Armstrong’s contention in Desire and Domestic Fiction that subjectivity was to begin with “a female domain” in the novel (Armstrong 4), although it puts the peak of this phenomenon a little later than she suggests.
But in general, the gendering of subjectivity is a pattern that will be familiar to scholars of the novel. So, probably, is the tension between public and private space revealed here. Throughout the nineteenth century, it’s “her chamber” and “her room,” but “his country.” Around 1925, houses switch owners.
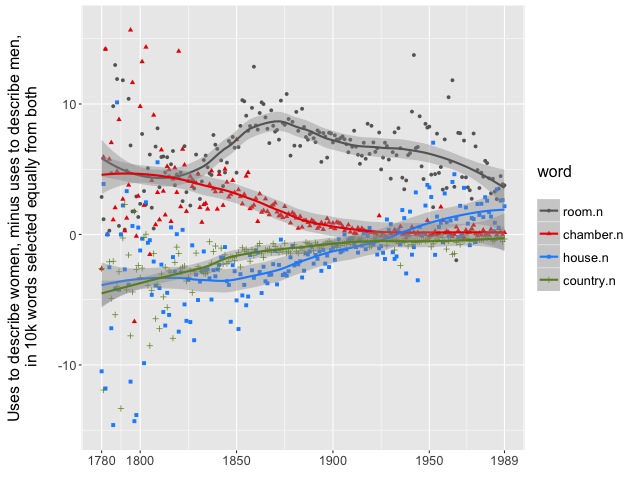
The convergence of all these lines on the right side of the graph helps explain why our models find gender harder and harder to predict: many of the words you might use to predict it are becoming less common (or becoming more evenly balanced between men and women — the graphs we’ve presented here don’t yet distinguish those two sorts of change.) On balance, that’s the prevailing trend. But there are also a few implicitly gendered forms of description that do increase. In particular, physical description becomes more important in fiction (Heuser and Le-Khac 2012).
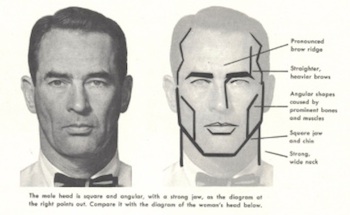
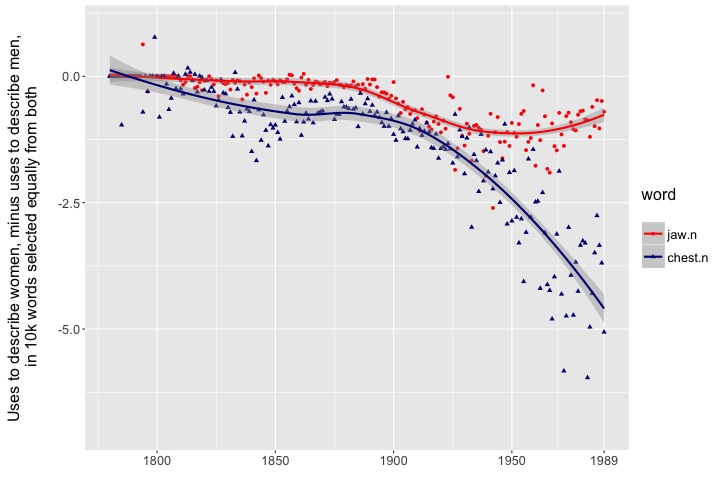
And as writers spend more time describing their characters physically, some aspects of the body and dress also become more important as signifiers of gender. This isn’t a simple, monolithic process. There are parts of the body whose significance seems to peak at a certain date and then level off — like the masculine jaw, maybe peaking around 1950?
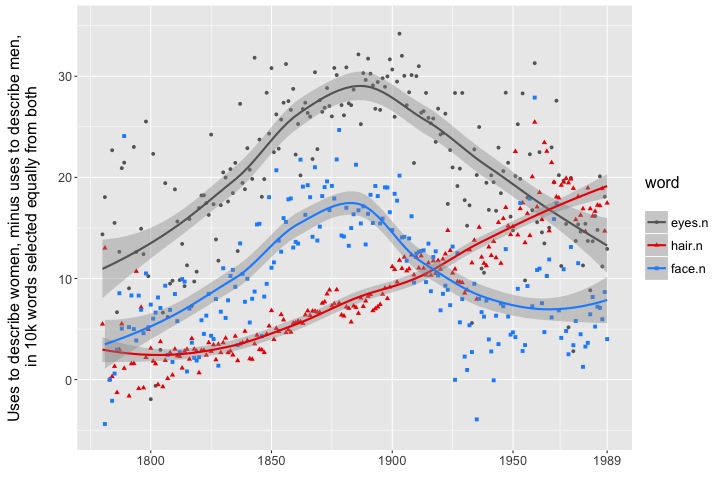
Other signifiers of masculinity — like the chest, and incidentally pockets — continue to become more and more important. For women, the “eyes” and “face” peak very markedly around 1890. But hair has rarely been more gendered (or bigger) than it was in the 1980s.
The measures we’re using here are simple, and deliberately conflate sheer frequency with gendered-ness in order to highlight words that have both attributes. We may use a wider range of interpretive strategies in the final article. But it’s clear already that gender has been unstable, not just because the implicit gendering of characterization became blurrier overall from 1840 to 1989 — but because the specific clues associated with gender have been rather volatile. In other words, gender is not at all the same thing in 1980 that it was in 1840.
There’s nothing very novel about the discovery that gender is fluid. But of course, we like to say everything is fluid: genres, roles, geographies. The advantage of a comparative method is that it lets us say specifically what we mean. Fluid compared to what? For instance, the increasing blurriness of gender boundaries is a kind of change we don’t see when we model the boundary between detective fiction and other genres: that boundary remains remarkably stable from 1841 to 1989. So we can say the linguistic signs of gender in characterization are more mutable than at least some genres.
We didn’t have to start with a complex data model to find this fluidity. Our initial representation of gender was a naive binary one, borrowed casually from English grammar. But we still ended up discovering that the things associated with those binary reference points have been in practice very changeable.
Other approaches are possible. The model Underwood has used to define genre (in a forthcoming piece) is messy and perspectival from the get-go, patched together from different sources of testimony. A project working with appropriate kinds of evidence could, similarly, build a perspectival dimension into definitions of gender from the very outset (for inspiration see Posner 2015 and Bamman et al. 2014b). But the point of research is also to discover things that weren’t hard-coded in the original plan. Even a perspectival model of genre may end up finding that different sources actually agree, for instance, about the boundaries of detective fiction. Conversely, even naively grammatical gender categories may start to bend and blur if they’re stretched across a two-century timeline.
Acknowledgements. This project was made possible by generous support from the NovelTM project, funded by the Social Sciences and Humanities Research Council. The authors would like to acknowledge work in progress at NovelTM as an influence on their thinking, including especially a forthcoming project by Matthew L. Jockers and Gabi Kirilloff. Our models of the twentieth century depend on collections located at the Chicago Text Lab, and supported by the University of Chicago Knowledge Lab. Eleanor Courtemanche suggested the connection to Woolf. BookNLP is available on github; work planned for this year at HathiTrust Research Center will make it possible for scholars to apply it to fiction even beyond the wall of copyright.
References:
Armstrong, Nancy. 1987. Desire and Domestic Fiction: A Political History of the Novel. New York: Oxford University Press.
Bamman, David, Ted Underwood, and Noah Smith. 2014a. “A Bayesian mixed-effects model of literary character.” ACL 2014. http://www.ark.cs.cmu.edu/literaryCharacter/
Bamman, David, Jacob Eisenstein, and Tyler Schnoebelen. 2014b. Gender Identity and Lexical Variation in Social Media. Journal of Sociolinguistics 18, 2 (2014).
Heuser, Ryan, and Long Le-Khac. 2012. “A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method.” Stanford Literary Lab Pamphlet Series. http://litlab.stanford.edu/pamphlets/ May 2012.
Lynch, Deidre. The Economy of Character: Novels, Market Culture, and the Business of Inner Meaning. Chicago: The University of Chicago Press, 1998.
Posner, Miriam. 2015. “What’s Next: The Radical, Unrealized Potential of Digital Humanities.” http://miriamposner.com/blog/whats-next-the-radical-unrealized-potential-of-digital-humanities/
Schmidt, Benjamin. 2015. “Gendered language in teaching reviews.” http://benschmidt.org/profGender/
Vala, Hardik, David Jurgens, Andrew Piper, and Derek Ruths. 2015. “Mr Bennet, his Coachman, and the Archibishop Walk into a Bar, but only One of them Gets Recognized.” CEMNLP. http://cs.stanford.edu/~jurgens/docs/vala-jurgens-piper-ruths_emnlp_2015.pdf
Woolf, Virginia. 1992. Orlando: A Biography, ed. Rachel Bowlby. Oxford: Oxford University Press.