More fundamentally, I’m unsure how anyone could be right or wrong here, because as far as I can tell there’s no thesis under discussion yet. Jockers’ article isn’t published. All we have is an R package, syuzhet, which does something I would call exploratory data analysis. And it’s hard to evaluate exploratory data analysis in the absence of a specific argument.
For instance, does syuzhet smooth plot arcs appropriately? I don’t know. Without a specific thesis we’re trying to test, how would we decide what scale of variation matters? In some novels it might be a scene-to-scene rhythm; in others it might be a long arc. Until I know what scale of variation matters for a particular question, I have no way of knowing what kind of smoothing is “too much” or “too little.”*
The same thing goes, more fundamentally, for the concepts of “plot” and “emotional valence” themselves. As Jacob Eisenstein has pointed out, these aren’t concepts that have a single agreed-upon meaning. To argue about them meaningfully, we’re going to need a particular historical or formal question we’re trying to solve.
It seems to me likely that syuzhet will usefully illuminate some aspects of plot. But I have no way of knowing which aspects until I look at a test involving groups of books that readers perceive as different in some specific way. For instance, if syuzhet reliably discriminates between books with tragic and comic endings, that would already be interesting. It’s not everything we mean by plot, but it’s one important thing.
The underlying issue here is that Matt hasn’t published his article yet. So we don’t actually have a thesis to debate. What we have is a new form of exploratory data analysis, released as an R package. Conversation about exploration can be interesting; it can teach me a lot about low-pass filters; but I don’t know how it could be wrong or right until I know what the exploration is trying to reveal.
I think this holds even for Matt’s claim that he’s identified six (or seven) fundamental plot patterns. That sounds like a thesis, but I would tend to say it’s still description of exploratory analysis — in this case a clustering process. Matt has done the clustering in a principled and careful way, but clustering is still (in my eyes) basically an exploratory method. I’m not sure how to evaluate it until I know what kind of generic or historical evidence would count as confirmation that we’re looking at a coherent “plot pattern.”
There are a range of ways to get that confirmation. Lynn Cherny has explored plot using supervised methods; if you do that, predictive accuracy gives you an easy test. But unsupervised methods can also be great, in cases where tests aren’t so easy to define; it’s just that an unsupervised method needs to be supplemented by historical or formal discussion that tells you what would count as confirmation for this method. I imagine there will be some of that in Matt’s article, when it comes out.
* [Edit March 31: After playing around with some artificial data myself, I have to acknowledge that the low-pass filter option in syuzhet can behave in unintuitive ways where extreme outliers and edges are involved. I think Annie Swafford (in blog posts) and Daniel Lepage (below) have been right to emphasize this. It could be less of an issue with real data; I had to use pretty extreme outliers to “break” the filter; it’s not actually the case that the whole shape is necessarily defined by its single highest point. But my guess is that this sort of filter would only add value if you wanted to build in a strong prior that plot fluctuates on or near a particular “wavelength.” On the other hand, Matt Jockers has alluded to unpublished evidence for that sort of prior (or at least for a particular filter setting). So, after changing my opinion a couple times, I’m still not feeling I have an answer here.]
If you haven’t read Ben’s blog post, I recommend exploring it now, because I’m going to skim lightly over some of the details of his method.
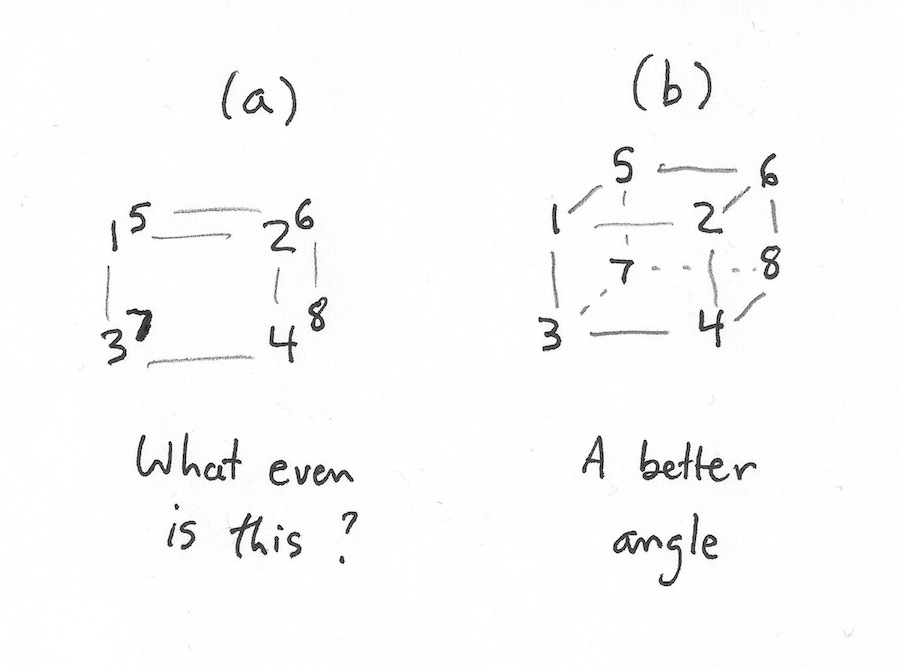
At its core, the technique is not complicated. It hinges on a transformation called principal component analysis (PCA), which allows researchers to map high-dimensional data onto a two-dimensional space, while keeping individual data points as far apart as possible. You can think of PCA as a technique that gives you a “good viewing angle” for flattening out a complex object. For instance, if you’ve got eight points at the corners of a cube, you could represent them as seen in (a), but (b) might be more legible because it spreads the points out more. It does that by squashing several different physical dimensions (length and breadth) into the x axis on the page.
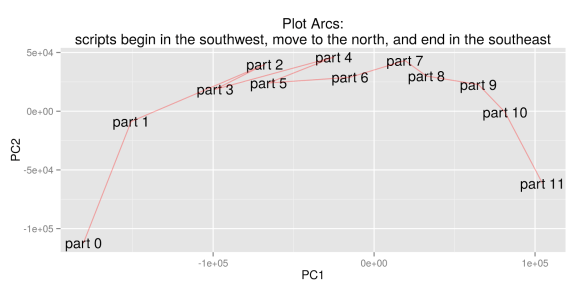
Ben uses this technique to reveal the structural relationship between different parts of a plot. As I understand it, he divides television scripts into six segments of equal length, and trains a topic model on all the segments. If you produce, say, 100 topics, each segment of each show is now characterized as a point in 100-dimensional space, where each dimension measures the prominence of one particular topic.
He takes the first sixth of every show and averages them to produce a single point that represents the average topic distribution for the first-sixth of all shows. After doing that for all six segments, he has six data points that represent typical segments of narrative time. Then he uses PCA to find an abstract space where those points are well separated. When he does this, he gets an arc-like structure that tends to preserve the original narrative sequence of the segments (although the algorithm isn’t directly informed about sequence). In his most detailed visualization, he even takes this down to twelfths.
Benjamin Schmidt’s initial visualization of “plot arcs,” December 16, 2014.
But what does this mean?
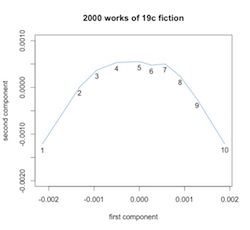
From the beginning, Ben has been pretty careful to stress that he sees the parabolic shape of this pattern as an artifact of PCA. (“I should emphasize that it’s hard to imagine any other shape coming out of the PCA algorithm with the inputs I put in.”) David Bamman confirms this, showing that PCA will turn many kinds of sequential data, even random walks, into an arc. The algorithm is also good at inferring sequence: if point 1 influences point 2, and point 2 influences point 3, etc., PCA will tend to preserve their sequential relationship in the projection. (It does this even if you take 1000 different random walks and add them up to produce a composite walk.) So if we believe that the topic distribution in each segment of each story is strongly related to the topic distributions on either side, we would expect PCA to organize the composite segments of all stories in a sequential arc.
That’s sort of cool, but also suggests that the structure we’re seeing is not unique to “plots.” On the other hand, it’s worth noting that the technique does work better on fiction (and television scripts) than on nonfiction. Or, rather, it shows us something different when you apply it to nonfiction.
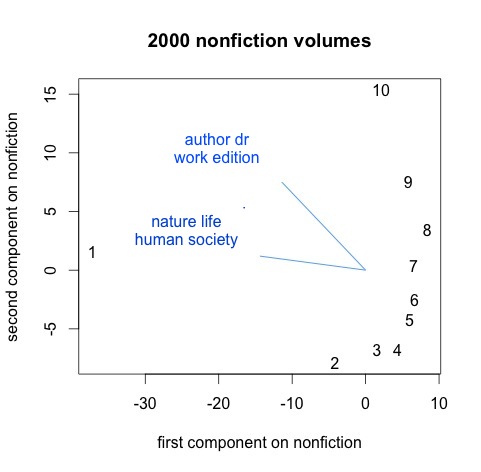
Here I’ve divided 2000 volumes of nineteenth-century nonfiction into ten parts, trained 200 topics on all 20,000 segments, and then created composite data points that represent the first “tenth,” second “tenth,” and so on, for all the volumes. PCA is still, somewhat remarkably, able to organize these points in the right sequence, but you have to squint a little to call this an arc. The graph is more clearly dominated by a contrast between introductions and body text. I’ve plotted two of the most important organizing topics as vectors; they include a lot of high-level abstractions and metadiscourse, whereas most of the topics in this nonfiction model are as specific as “birds eggs young wings” (and have a much smaller influence on this graph).
It’s important to note that I’m using the page-level metadata I recently described to select nonfiction here, which makes an effort to screen out paratext. (Otherwise we would probably be seeing topics like “table contents” and “index due date”!)
So where does this leave us? I think Lynn Cherny is right to say that with this technique, deviations from an arc are more significant than the arc itself. The slightly arc-like sequence on the right-hand side of the nonfiction graph isn’t telling us much about deep structures organizing nonfiction; it’s telling us mainly that there are continuities in text. But the “1” way over on the left-hand side is revealing a large structural fact: works of nonfiction have prefaces and introductions that can be very different from the rest of the text. Similarly, one of the most interesting aspects of Ben’s post involves the structural differences he finds toward the end between television genres (the difference between beginning and end seems more important for comedies, whereas science fiction is more organized by a contrast between central action and frame). Not a bad result for a historian to generate in his spare time.
Ten points that represent composite “tenths” of 1.981 works of fiction, topic-modeled and projected by PCA. Multivolume works have been joined.
Also, when I say differences are interesting, I don’t mean that the composite arc Ben saw by averaging all genres was meaningless. The fact that PCA will organize ten segments of 2000 novels into a parabola is not surprising. It would do that even with a random sequence. But in practice we’re not looking at random sequences, so PCA organizes points into a parabola by drawing on actual linguistic gradients that organize narrative time. As Ben has shown in a follow-up post, PCA is able to explain the patterns in television scripts better than it can explain random sequences.
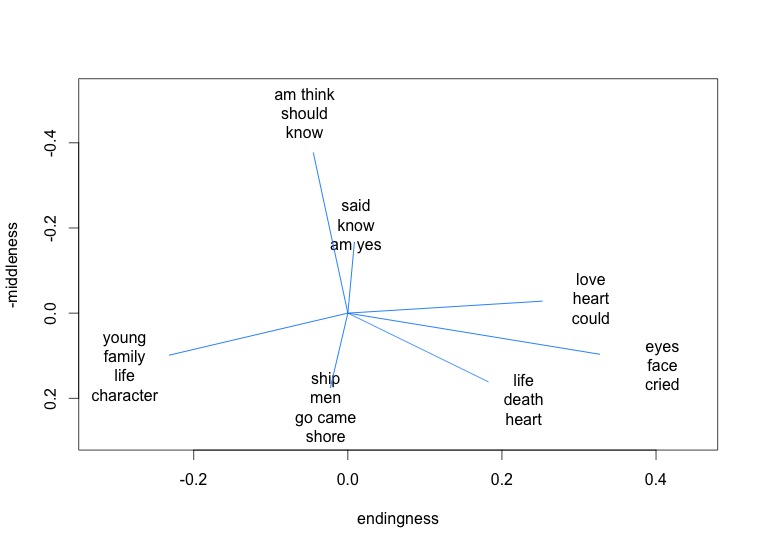
In other words, the differences we’re seeing between beginnings, middles, and ends are real differences. And it’s interesting to see what those differences are. The x and y axes in a PCA projection don’t have simple meanings, because we’ve squashed multiple dimensions into two. But we can understand the space a little better by mapping the influence exerted by different topics.
Vectors that play an especially strong role in organizing the PCA projection of 1,981 nineteenth-century novels.
In this visualization, for instance, topics associated with dialogue (“said am know yes”) tend to move a point up the y axis. They’re more common in the middle of a narrative.
It might also be interesting to compare the way narratives from different authors or genres project into this space.
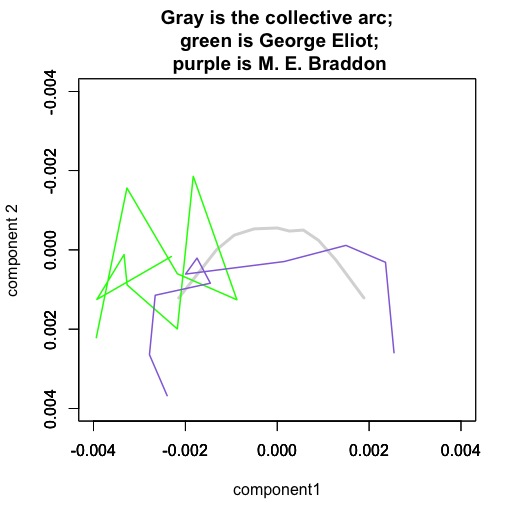
Each author here is represented by a composite set of ten segments of narrative time, produced by averaging her works. They are projected into a space defined by the average “tenths” of all works in the dataset.
Mary Elizabeth Braddon is a sensation novelist, and her works are strongly organized by a structure that resembles the majority of other novels in the nineteenth century (or is perhaps even more distinct than usual). A book like Lady Audley’s Secret begins with a stage-setting description of domestic space and family relationships. The middle of the book is characterized by dialogue. The tone of the diction becomes progressively more sentimental* until, in the conclusion, we back away from dialogue again to summary (but a summary that is very different from the introduction in tone).
By contrast, the novels of George Eliot are… um, perhaps it would be safest to say “not as well characterized by this model of narrative sequence.” You might be tempted to look at that tangle of lines and infer some kind of cyclic structure, but it would be a bit like reading tea leaves. I know George Eliot’s novels are interesting, but I doubt that squiggle tells me why. (It’s important to remember, for instance, that Eliot’s narrative time looks more orderly and arc-like when projected into a space defined by her own writing.)
Supervised and unsupervised models
In short, I think the method Ben has developed is interesting and worth further exploration, but I also think there are real interpretive challenges here. And the interpretive challenges are not general problems that would arise with any quantitative method: they’re specific to a quirk of this one, which is that it’s poised delicately between strategies of “supervised” and “unsupervised” modeling.
Actually, I’m not sure it’s technically accurate to call PCA a model at all; it’s almost a descriptive statistic (like the mean or standard deviation of a dataset). But the attraction of the technique is a bit like the attraction of unsupervised modeling: you turn it loose on the data and it spontaneously reveals patterns.
There’s nothing at all wrong with that, but the tricky thing here is that by focusing PCA on the temporal sequence within works, we actually give it a very strong bias toward a particular sort of pattern (a sequential arc). Which means we’re actually doing something that’s a bit more supervised than it might appear. It’s more like saying “if you assume narrative time is parabola-shaped, what would be the linguistic vectors organizing that space?”
All these approaches are interesting, and potentially valid; I just think it’s important to note that none of them are giving us an unsupervised model of plot. (Even unsupervised models do make assumptions, but I would say a topic model, for instance, is slightly more open-ended than an approach that implicitly maps sequences onto arcs.) There’s nothing wrong with assuming an arc, but there might be some advantage to doing it more explicitly. If I were going to use Ben’s insight to study plot in nineteenth-century novels, I would probably drop PCA and instead train two classifiers to recognize the “ends” and “middles” of narratives. When you do that, you get a result that is actually quite parallel to the one I got by using PCA.
The average probabilities two classifiers assigned to segments from different “tenths” of 1,981 novels. Five-fold crossvalidated, but I didn’t rule out the possibility that an author might appear in both the test set and the training set.
But with a predictive model like a classifier, I feel a little more confident in my ability to characterize the strength of the patterns I’m seeing. In this case, for instance, the classifier that recognizes ends was about 62% accurate out of sample. The classifier that recognizes middles was about 61% accurate, and since I counted six out of ten segments of each narrative as “the middle,” that’s not a lot better than random. [Later edit: This was a hasty first pass. Some simple normalization got the classifiers up to 67% and 64%. That signal is probably strong enough for people to do more interesting things with it.]
However, I want to be clear: I don’t think there’s anything wrong with using PCA for this, as long as we realize that it’s surprisingly good at inferring sequence from random walks in high-dimensional space. If plots are “arcs” (as critics have tended to assume), why not make use of that insight to analyze and visualize them? Ben’s post shows us one way to do that. Another thing I take away from this exploration is how amazing Twitter can be, because I couldn’t have fully understood what was going on here without contributions from a lot of different people.
* Re: “the tone of the diction becomes progressively more sentimental:” Matt Wilkens points out that the vectors that characterize endings here have a lot in common with the language that Sara Steger identified as characteristic of 19c sentimental fiction.
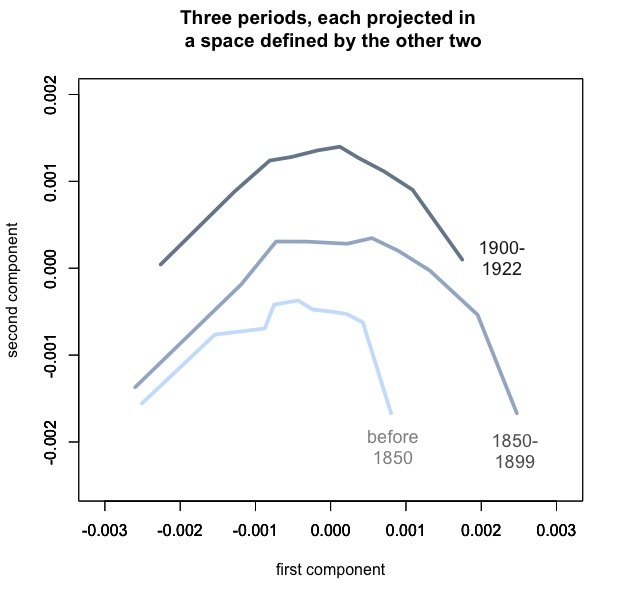
Postscript Jan 5: Have to admit I’ve found it hard to stop exploring this method. I ran it on a fiction dataset expanded to 4,000 works, and to 1922, and patterns started to become a little more legible. For instance, when I include more of her works, George Eliot no longer looks as idiosyncratic. It’s also kind of interesting to superimpose plot arcs for three different periods. Here I’ve borrowed Ben’s idea of using PCA so to speak “out-of-sample,” since each of these periods is actually projected into a different space (defined by the other two periods).
Generalized narrative arcs for 4,000 works of fiction from 1700 to 1922. In each case we’re plotting ten composite points representing the topic distributions for segments of narrative time, and time moves from left to right. The dataset does include reprints.
The fact that these arcs float upward may confirm something we already knew, which is that fiction tends to move away from “summary” and toward direct presentation of “scene” as historical time passes. But I think the stability of the pattern is also significant. As Ben has shown, there’s no guarantee that you’ll get an arc if you project a dataset into a PCA space defined by a different dataset. The congruence of these three arcs may not quite prove that plot *is* an arc, but it does suggest that linguistic signals of “beginnings,” “middles,” and “ends” remained broadly similar from the early nineteenth century through the early twentieth. If we wanted to confirm that, we could make more direct comparisons, but for exploratory visualization I see how PCA is useful here.
There are basically two different ways to build collections for distant reading. You can build up collections of specific genres, selecting volumes that you know belong to them. Or you can take an entire digital library as your base collection, and subdivide it by genre.
Most people do it the first way, and having just spent two years learning to do it the second way, I’d like to admit that they’re right. There’s a lot of overhead involved in mining a library. The problem becomes too big for your desktop; you have to schedule batch jobs; you have to learn to interpret MARC records. All this may be necessary eventually, but it’s not the ideal place to start.
But some of the problems I’ve encountered have been interesting. In particular, the problem of “dividing a library by genre” has made me realize that literary studies is constituted by exclusions that are a bit larger and more arbitrary than I used to think.
First of all, why is dividing by genre even a problem? Well, most machine-readable catalog records don’t say much about genre, and even if they did, a single volume usually contains multiple genres anyway. (Think introductions, indexes, collected poems and plays, etc.) With support from the ACLS and NEH, I’ve spent the last year wrestling with that problem, and in a couple of weeks I’m going to share an imperfect page-level map of genre for English-language books in HathiTrust 1700-1923.
But the bigger thing I want to report is that the ambiguity of genre may run deeper than most scholars who aren’t librarians currently imagine. To be sure, we know that subgenres like “detective fiction” are social institutions rather than natural forms. And in a vague way we also accept that broader categories like “fiction” and “poetry” are social constructs with blurry edges. We can all point to a few anomalies: prose poems, eighteenth-century journalistic fictions like The Spectator, and so on.
But somehow, in spite of knowing this for twenty years, I never grasped the full scale of the problem. For instance, I knew the boundary between fiction and nonfiction was blurry in the 18c, but I thought it had stabilized over time. By the time you got to the Victorians, surely, you could draw a circle around “fiction.” Exceptions would just prove the rule.
Selecting volumes one by one for genre-specific collections didn’t shake my confidence. But if you start with a whole library and try to winnow it down, you’re forced to consider a lot of things you would otherwise never look at. I’ve become convinced that the subset of genre-typical cases (should we call them cis-genred volumes?) is nowhere near as paradigmatic as literary scholars like to imagine. A substantial proportion of the books in a library don’t fit those models. This is both a photograph of a real, unnamed mother and baby, and a picture of a fictional character named Shinkah. Frontispiece to Shinkah, The Osage Indian (1916).
Consider the case of Shinkah, the Osage Indian, published in 1916 by S. M. Barrett. The preface to this volume informs us that it’s intended as a contribution to “the sociology of the Osage Indians.” But it’s set a hundred years in the past, and the central character Shinkah is entirely fictional (his name just means “child.”) On the other hand, the book is illustrated with photographs of real contemporary people, who stand for the characters in an ethnotypical way.
After wading though 872,000 volumes, I’m sorry to report that odd cases of this kind are more typical of nineteenth- and early twentieth-century fiction than my graduate-school training had led me to believe. There’s a smooth continuum for instance between Shinkah and Old Court Life in France (1873), by Frances Elliot. This book has a bibliography, and a historiographical preface, but otherwise reads like a historical novel, complete with invented dialogue. I’m not sure how to distinguish it from other historical novels with real historical personages as characters.
Literary critics know there’s a problem with historical fiction. We also know about the blurry boundary between fiction, journalism, and travel writing represented by the genre of the “sketch.” And anyone who remembers James Frey being kicked out of Oprah Winfrey’s definition of nonfiction knows that autobiographies can be problematic. And we know that didactic fiction blurs into philosophical dialogue. And anyone who studies children’s literature knows that the boundary between fiction and nonfiction gets especially blurry there. And probably some of us know about ethnographic novels like Shinkah. But I’m not sure many of us (except for librarians) have added it all up. When you’re sorting through an entire library you’re forced to see the scale of it: in the period 1700-1923, maybe 10% of the volumes that could be cataloged as fiction present puzzling boundary cases.
You run into a lot of these works even if you browse or select titles at random; that’s how I met Shinkah. But I’ve also been training probabilistic models of genre that report, among other things, how certain or uncertain they are about each page. These models are good at identifying clear cases of our received categories; I found that they agreed with my research assistants almost exactly as often as the research assistants agreed with each other (93-94% of the time, about broad categories like fiction/nonfiction). But you can also ask a model to sift through several thousand volumes looking for hard cases. When I did that I was taken aback to discover that about half the volumes it had most trouble with were things I also found impossible to classify. The model was most uncertain, for instance, about The Terrific Register (1825) — an almanac that mixes historical anecdote, urban legend, and outright fiction randomly from page to page. The second-most puzzling book was Madagascar, or Robert Drury’s Journal (1729), a book that offers itself as a travel journal by a real person, and was for a long time accepted as one, although scholars have more recently argued that it was written by Defoe.
Of course, a statistical model of fiction doesn’t care whether things “really happened”; it pays attention mostly to word frequency. Past-tense verbs of speech, personal names, and “the,” for instance, are disproportionately common in fiction. “Is” and “also” and “mr” (and a few hundred other words) are common in nonfiction. Human readers probably think about genre in a more abstract way. But it’s not particularly miraculous that a model using word frequencies should be confused by the same examples we find confusing. The model was trained, after all, on examples tagged by human beings; the whole point of doing that was to reproduce as much as possible the contours of the boundary that separates genres for us. The only thing that’s surprising is that trawling the model through a library turns up more books right in the middle of the boundary region than our habits of literary attention would have suggested.
A lot of discussions of distant reading have imagined it as a move from canonical to popular or obscure examples of a (known) genre. But reconsidering our definitions of the genres we’re looking for may be just as important. We may come to recognize that “the novel” and “the lyric poem” have always been islands floating in a sea of other texts, widely read but never genre-typical enough to be replicated on English syllabi.
In the long run, this may require us to balance two kinds of inclusiveness. We already know that digital libraries exclude a lot. Allen Riddell has nicely demonstrated just how much: he concludes that there are digital scans for only about 58% of the novels listed in bibliographies as having been published between 1800 and 1836.
One way to ensure inclusion might be to start with those bibliographies, which highlight books invisible in digital libraries. On the other hand, bibliographies also make certain things invisible. The Terrific Register (1825), for instance, is not in Garside’s bibliography of early-nineteenth-century fiction. Neither is The Wonder-Working Water Mill (1791), to mention another odd thing I bumped into. These aren’t oversights; Garside et. al. acknowledge that they’re excluding certain categories of fiction from their conception of the novel. But because we’re trained to think about novels, the scale of that exclusion may only become visible after you spend some time trawling a library catalog.
I don’t want to present this as an aporia that makes it impossible to know where to start. It’s not. Most people attempting distant reading are already starting in the right place — which is to build up medium-sized collections of familiar generic categories like “the novel.” The boundaries of those categories may be blurrier than we usually acknowledge. But there’s also such a thing as fretting excessively about the synchronic representativeness of your sample. A lot of the interesting questions in distant reading are actually trends that involve relative, diachronic differences in the collection. Subtle differences of synchronic coverage may more or less drop out of questions about change over time.
On the other hand, if I’m right that the gray areas between (for instance) fiction and nonfiction are bigger and more persistently blurry than literary scholarship usually mentions, that’s probably in the long run an issue we should consider! When I release a page-level map of genre in a couple of weeks, I’m going to try to provide some dials that allow researchers to make more explicit choices about degrees of inclusion or exclusion.
Predictive models that report probabilities give us a natural way to handle this, because they allow us to characterize every boundary as a gradient, and explicitly acknowledge our compromises (for instance, trade-offs between precision and recall). People who haven’t done much statistical modeling often imagine that numbers will give humanists spuriously clear definitions of fuzzy concepts. My experience has been the opposite: I think our received disciplinary practices often make categories seem self-evident and stable because they teach us to focus on easy cases. Attempting to model those categories explicitly, on a large scale, can force you to acknowledge the real instability of the boundaries involved.
References and acknowledgments
Training data for this project was produced by Shawn Ballard, Jonathan Cheng, Lea Potter, Nicole Moore and Clara Mount, as well as me. Michael L. Black and Boris Capitanu built a GUI that helped us tag volumes at the page level. Material support was provided by the National Endowment for the Humanities and the American Council of Learned Societies. Some information about results and methods is online as a paper and a poster, but much more will be forthcoming in the next month or so — along with a page-level map of broad genre categories and types of paratext.
The project would have been impossible without help from HathiTrust and HathiTrust Research Center. I’ve also been taught to read MARC records by librarians and information scientists including Tim Cole, M. J. Han, Colleen Fallaw, and Jacob Jett, any of whom could teach a course on “Cursed Metadata in Theory and Practice.”
I mention Garside’s bibliography of early nineteenth-century fiction. This is Garside, Peter, and Rainer Schöwerling. The English novel, 1770-1829 : a bibliographical survey of prose fiction published in the British Isles. Ed. Peter Garside, James Raven, and Rainer Schöwerling. 2 vols. Oxford: Oxford University Press, 2000.
The Institute of Electrical and Electronics Engineers is an odd venue for literary history, and our paper ends up touching so many disciplinary bases that it may be distracting.* So I thought I’d pull out four issues of interest to humanists and discuss them briefly here; I’m also taking the occasion to add a little information about gender that we uncovered too late to include in the paper itself.
1) The overall point about genre. Our title, “Mapping Mutable Genres in Structurally Complex Volumes,” may sound like the sort of impossible task heroines are assigned in fairy tales. But the paper argues that the blurry mutability of genres is actually a strong argument for a digital approach to their history. If we could start from some consensus list of categories, it would be easy to crowdsource the history of genre: we’d each take a list of definitions and fan out through the archive. But centuries of debate haven’t yet produced stable definitions of genre. In that context, the advantage of algorithmic mapping is that it can be comprehensive and provisional at the same time. If you change your mind about underlying categories, you can just choose a different set of training examples and hit “run” again. In fact we may never need to reach a consensus about definitions in order to have an interesting conversation about the macroscopic history of genre.
2) A workset of 32,209 volumes of English-language fiction. On the other hand, certain broad categories aren’t going to be terribly controversial. We can probably agree about volumes — and eventually specific page ranges — that contain (for instance) prose fiction and nonfiction, narrative and lyric poetry, and drama in verse, or prose, or some mixture of the two. (Not to mention interesting genres like “publishers’ ads at the back of the volume.”) As a first pass at this problem, we extract a workset of 32,209 volumes containing prose fiction from a collection of 469,200 eighteenth- and nineteenth-century volumes in HathiTrust Digital Library. The metadata for this workset is publicly available from Illinois’ institutional repository. More substantial page-level worksets will soon be produced and archived at HathiTrust Research Center.
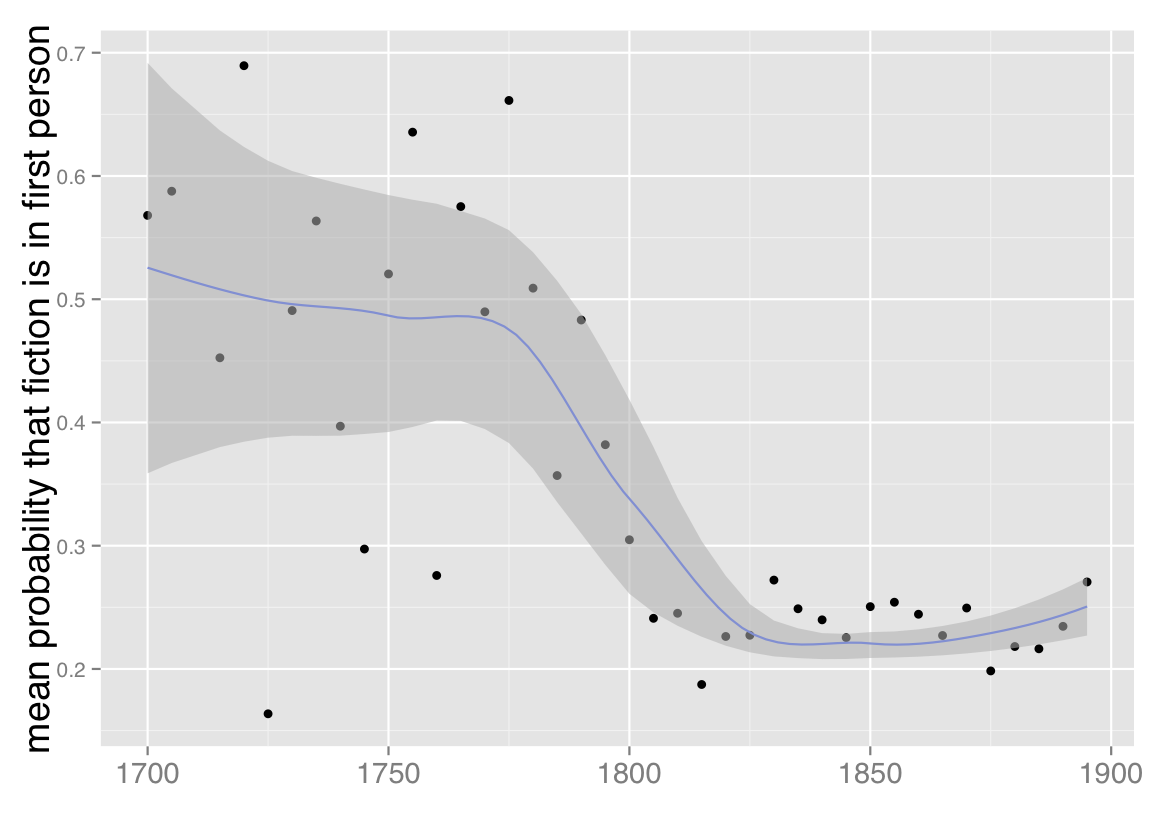
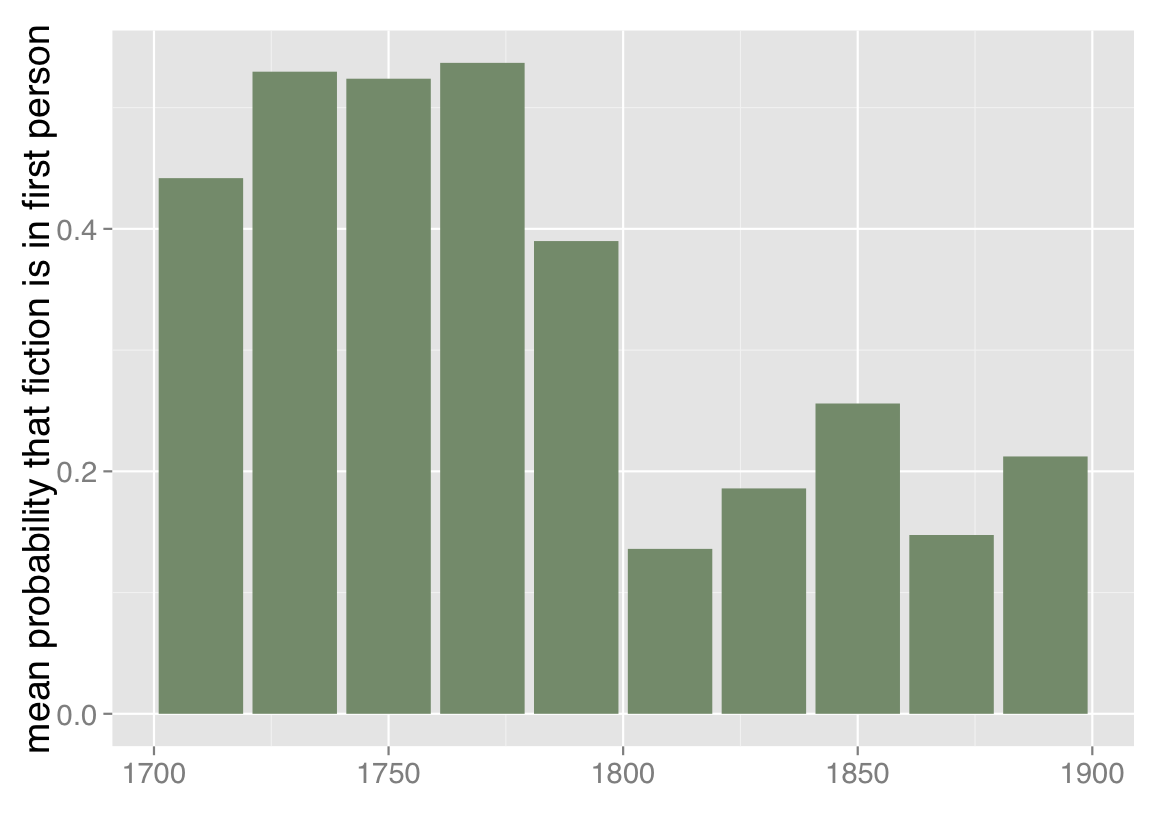
3) The declining prevalence of first-person narration. Once we’ve identified this fiction workset, we switch gears to consider point of view — frankly, because it’s a temptingly easy problem with clear literary significance. Though the fiction workset we’re using is defined more narrowly than it was last February, we confirm the result I glimpsed at that point, which is that the prevalence of first-person point of view declines significantly toward the end of the eighteenth century and then remains largely stable for the nineteenth.
Mean probability that fiction is written in first person, 1700-1899. Based on a corpus of 32,209 volumes of fiction extracted from HathiTrust Digital Library. Points are mean probabilities for five-year spans of time; a trend line with standard errors has been plotted with loess smoothing.
We can also confirm that result in a way I’m finding increasingly useful, which is to test it in a collection of a completely different sort. The HathiTrust collection includes reprints, which means that popular works have more weight in the collection than a novel printed only once. It also means that many volumes carry a date much later than their first date of publication. In some ways this gives a more accurate picture of print culture (an approximation to “what everyone read,” to borrow Scott Weingart’s phrase), but one could also argue for a different kind of representativeness, where each volume would be included only once, in a record dated to its first publication (an attempt to represent “what everyone wrote”).
Mean probability that fiction is written in first person, 1700-1899. Based on a corpus of 774 volumes of fiction selected by multiple hands from multiple sources. Plotted in 20-year bins because n is smaller here. Works are weighted by the number of words they contain.
Fortunately, Jordan Sellers and I produced a collection like that a few years ago, and we can run the same point-of-view classifier on this very different set of 774 fiction volumes (metadata available), selected by multiple hands from multiple sources (including TCP-ECCO, the Brown Women Writers Project, and the Internet Archive). Doing that reveals broadly the same trend line we saw in the HathiTrust collection. No collection can be absolutely representative (for one thing, because we don’t agree on what we ought to be representing). But discovering parallel results in collections that were constructed very differently does give me some confidence that we’re looking at a real trend.
4. Gender and point of view. In the process of classifying works of fiction, we stumbled on interesting thematic patterns associated with point of view. Features associated with first-person perspective include first-person pronouns, obviously, but also number words and words associated with sea travel. Some of this association may be explained by the surprising persistence of a particular two-century-long genre, the Robinsonade. A castaway premise obviously encourages first-person narration, but the colonial impulse in the Robinsonade also seems to have encouraged acquisitive enumeration of the objects (goats, barrels, guns, slaves) its European narrators find on ostensibly deserted islands. Thus all the number words. (But this association of first-person perspective with colonial settings and acquisitive enumeration may well extend beyond the boundaries of the Robinsonade to other genres of adventure fiction.)
Third-person perspective, on the other hand, is durably associated with words for domestic relationships (husband, lover, marriage). We’re still trying to understand these associations; they could be consequences of a preference for third-person perspective in, say, courtship fiction. But third-person pronouns correlate particularly strongly with words for feminine roles (girl,daughter,woman) — which suggests that there might also be a more specifically gendered dimension to this question.
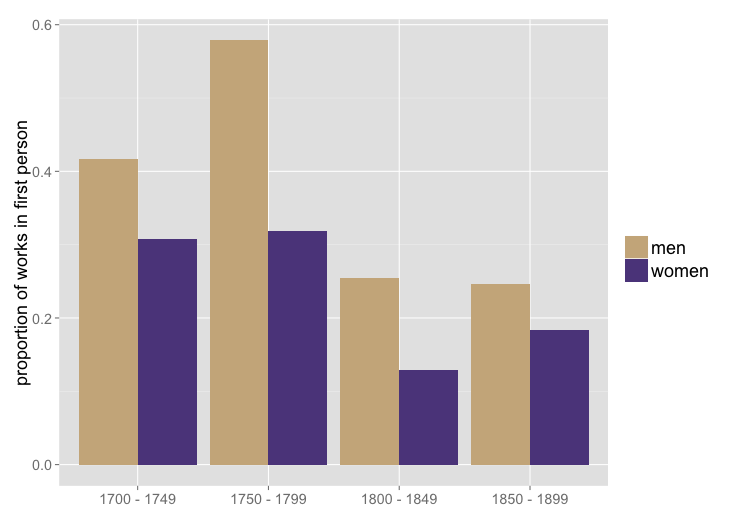
Since transmitting our paper to the IEEE I’ve had a chance to investigate this hypothesis in the smaller of the two collections we used for that paper — 774 works of fiction between 1700 and 1899: 521 by men, 249 by women, and four not characterized by gender. (Mike Black and Jordan Sellers recorded this gender data by hand.) In this collection, it does appear that male writers choose first-person perspective significantly more than women do. The gender gap persists across the whole timespan, although it might be fading toward the end of the nineteenth century.
Proportion of works of fiction by men and women in first person. Based on the same set of 774 volumes described above. (This figure counts strictly by the number of works rather than weighting works by the number of words they contain.)
Over the whole timespan, women use first person in roughly 23% of their works, and men use it in roughly 35% of their works.** That’s not a huge difference, but in relative terms it’s substantial. (Men are using first person 52% more than women). The Bayesian mafia have made me wary of p-values, but if you still care: a chi-squared test on the 2×2 contingency table of gender and point of view gives p < 0.001. (Attentive readers may already be wondering whether the decline of first person might be partly explained by an increase in the proportion of women writers. But actually, in this collection, works by women have a distribution that skews slightly earlier than that of works by men.)
These are very preliminary results. 774 volumes is a small set when you could test 32,209. At the recent HTRC Uncamp, Stacy Kowalczyk described a method for gender identification in the larger HathiTrust corpus, which we will be eager to borrow once it’s published. Also, the mere presence of an association between gender and point of view doesn’t answer any of the questions literary critics will really want to pose about this phenomenon — like, why is point of view associated with gender? Is this actually a direct consequence of gender, or is it an indirect consequence of some other variable like genre? Does this gendering of narrative perspective really fade toward the end of the nineteenth century? I don’t pretend to have answered any of those questions, all I’m doing here is flagging the existence of an interesting open question that will deserve further inquiry.
** We don’t actually represent point of view as a binary choice between first person or third person; the classifier reports probabilities as a continuous range between 0 and 1. But for purposes of this blog post I’ve simplified by dividing the works into two sets at the 0.5 mark. On this point, and for many other details of quantitative methodology, you’ll want to consult the paper itself.
In Macroanalysis, Matt Jockers points out that computational stylistics has found it hard to grapple with “the aspects of writing that readers care most deeply about, namely plot, character, and theme” (118). He then proceeds to use topic modeling to pretty thoroughly anatomize theme in the nineteenth-century novel. One down, I guess, two to go!
But plot and character are probably harder than theme; it’s not yet clear how we would trace those patterns in thousands of volumes. So I think it may be worth flagging a very promising article by David Bamman, Brendan O’Connor, and Noah A. Smith. Computer scientists don’t often develop a new methodology that could seriously enrich criticism of literature and film. But this one deserves a look. (Hat tip to Lynn Cherny, by the way, for this lead.)
The central insight in the article is that character can be modeled grammatically. If you can use natural language processing to parse sentences, you should be able to identify what’s being said about a given character. The authors cleverly sort “what’s being said” into three questions: what does the character do, what do they suffer or undergo, and what qualities are attributed to them? The authors accordingly model character types (or “personas”) as a set of three distributions over these different domains. For instance, the ZOMBIE persona might do a lot of “eating” and “killing,” get “killed” in turn, and find himself described as “dead.”
The authors try to identify character types of this kind in a collection of 42,306 movie plot summaries extracted from Wikipedia. The model they use is a generative one, which entails assumptions that literary critics would call “structuralist.” Movies in a given genre have a tendency to rely on certain recurring character types. Those character types in turn “generate” the specific characters in a given story, which in turn generate the actions and attributes described in the plot summary.
Using this model, they reason inward from both ends of the process. On the one hand, we know the genres that particular movies belong to. On the other hand, we can see that certain actions and attributes tend to recur together in plot summaries. Can we infer the missing link in this process — the latent character types (“personas”) that mediate the connection from genre to action?
It’s a very thoughtful model, both mathematically and critically. Does it work? Different disciplines will judge success in different ways. Computer scientists tend to want to validate a model against some kind of ground truth; in this case they test it against character patterns described by fans on TV Tropes. Film critics may be less interested in validating the model than in seeing whether it tells them anything new about character. And I think the model may actually have some new things to reveal; among other things, it suggests that the vocabulary used to describe character is strongly coded by genre. In certain genres, characters “flirt,” in others, they “switch” or “are switched.” In some genres, characters merely “defeat” each other; in other genres, they “decapitate” or “are decapitated”!
Since an association with genre is built into the generative assumptions that define the article’s model of character, this might be a predetermined result. But it also raises a hugely interesting question, and there’s lots of room for experimentation here. If the authors’ model of character is too structuralist for your taste, you’re free to sketch a different one and give it a try! Or, if you’re skeptical about our ability to fully “model” character, you could refuse to frame a generative model at all, and just use clustering algorithms in an ad hoc exploratory way to find clues.
Critics will probably also cavil about the dataset (which the authors have generously made available). Do Wikipedia plot summaries tell us about recurring character patterns in film, or do they tell us about the character patterns that are most readily recognized by editors of Wikipedia?
But I think it would be a mistake to cavil. When computer scientists hand you a new tool, the question to ask is not, “Have they used it yet to write innovative criticism?” The question to ask is, “Could we use this?” And clearly, we could.
The approach embodied in this article could be enormously valuable: it could help distant reading move beyond broad stylistic questions and start to grapple with the explicit social content of fiction (and for that matter, nonfiction, which may also rely on implicit schemas of character, as the authors shrewdly point out). Ideally, we would not only map the assumptions about character that typify a given period, but describe how those patterns have changed across time.
Making that work will not be simple: as always, the real problem is the messiness of the data. Applying this technique to actual fictive texts will be a lot harder than applying it to a plot summary. Character names are often left implicit. Many different voices speak; they’re not all equally reliable. And so on.
But the Wordseer Project at Berkeley has begun to address some of these problems. Also, it’s possible that the solution is to scale up instead of sweating the details of coreference resolution: an error rate of 20 or 30% might not matter very much, if you’re looking at strongly marked patterns in a corpus of 40,000 novels.
In any case, this seems to me an exciting lead, worthy of further exploration.
Postscript: Just to illustrate some of the questions that come up: How gendered are character types? The article by Bamman et. al. explicitly models gender as a variable, but the types it ends up identifying are less gender-segregated than I might expect. The heroes and heroines of romantic comedy, for instance, seem to be described in similar ways. Would this also be true in nineteenth-century fiction?
In recent months I’ve had several conversations with colleagues who are friendly to digital methods but wary of claims about novelty that seem overstated. They believe that text mining can add a new level of precision to our accounts of literary history, or add a new twist to an existing debate. They just don’t think it’s plausible that quantification will uncover fundamentally new evidence, or patterns we didn’t previously expect.
If I understand my friends’ skepticism correctly, it’s founded less on a narrow objection to text mining than on a basic premise about the nature of literary study. And where the history of the discipline is concerned, they’re arguably right. In fact, the discipline of literary studies has not usually advanced by uncovering unexpected evidence. As grad students, that’s not what we were taught to aim for. Instead we learned that the discipline moves forward dialectically. You take something that people already believe and “push against” it, or “critique” it, or “complicate” it. You don’t make discoveries in literary study, or if you do they’re likely to be minor — a lost letter from Byron to his tailor. Instead of making discoveries, you make interventions — a telling word.
The broad contours of our discipline are already known, so nothing can grow without displacing something else.
So much flows from this assumption. If we’re not aiming for discovery, if the broad contours of literary history are already known, then methodological conversation can only be a zero-sum game. That’s why, when I say “digital methods don’t have to displace traditional scholarship,” my colleagues nod politely but assume it’s insincere happy talk. They know that in reality, the broad contours of our discipline are already known, and anything within those boundaries can only grow by displacing something else.
These are the assumptions I was also working with until about three years ago. But a couple of years of mucking about in digital archives have convinced me that the broad contours of literary history are not in fact well understood.
For instance, I just taught a course called Introduction to Fiction, and as part of that course I talk about the importance of point of view. You can characterize point of view in a lot of subtle ways, but the initial, basic division is between first-person and third-person perspectives.
Suppose some student had asked the obvious question, “Which point of view is more common? Is fiction mostly written in the first or third person? And how long has it been that way?” Fortunately undergrads don’t ask questions like that, because I couldn’t have answered.
I have a suspicion that first person is now used more often in literary fiction than in novels for a mass market, but if you ask me to defend that — I can’t. If you ask me how long it’s been that way — no clue. I’ve got a Ph.D in this field, but I don’t know the history of a basic formal device. Now, I’m not totally ignorant. I can say what everyone else says: “Jane Austen perfected free indirect discourse. Henry James. Focalizing character. James Joyce. Stream of consciousness. Etc.” And three years ago that might have seemed enough, because the bigger, simpler question was obviously unanswerable and I wouldn’t have bothered to pose it.
But recently I’ve realized that this question is answerable. We’ve got large digital archives, so we could in principle figure out how the proportions of first- and third-person narration have changed over time.
You might reasonably expect me to answer that question now. If so, you underestimate my commitment to the larger thesis here: that we don’t understand literary history. I will eventually share some new evidence about the history of narration. But first I want to stress that I’m not in a position to fully answer the question I’ve posed. For three reasons:
1) Our digital collections are incomplete. I’m working with a collection of about 700,000 18th and 19th-century volumes drawn from HathiTrust.
That’s a lot. But it’s not everything that was written in the English language, or even everything that was published.
2) This is work in progress. For instance, I’ve cleaned and organized the non-serial part of the collection (about 470,000 volumes), but I haven’t started on the periodicals yet. Also, at the moment I’m counting volumes rather than titles, so if a book was often reprinted I count it multiple times. (This could be a feature or a bug depending on your goals.)
3) Most importantly, we can’t answer the question because we don’t fully understand the terms we’re working with. After all, what is “first-person narration?”
The truth is that the first person comes in a lot of different forms. There are cases where the narrator is also the protagonist. That’s pretty straightforward. Then epistolary novels. Then there are cases where the narrator is anonymous — and not a participant in the action — but sometimes refers to herself as I. Even Jane Austen’s narrator sometimes says “I.” Henry Fielding’s narrator does it a lot more. Should we simply say this is third-person narration, or should we count it as a move in the direction of first? Then, what are we going to do about books like Bleak House? Alternating chapters of first and third person. Maybe we call that 50% first person? — or do we assign it to a separate category altogether? What about a novel like Dracula, where journals and letters are interspersed with news clippings?
Suppose we tried to crowdsource this problem. We get a big team together and decide to go through half a million volumes, first of all to identify the ones that are fiction, and secondly, if a volume is fiction, to categorize the point of view. Clearly, it’s going to be hard to come to agreement on categories. We might get halfway through the crowdsourcing process, discover a new category, and have to go back to the drawing board.
Notice that I haven’t mentioned computers at all yet. This is not a problem created by computers, because they “only understand binary logic.” It’s a problem created by us. Distant reading is hard, fundamentally, because human beings don’t agree on a shared set of categories. Franco Moretti has a well-known list of genres, for instance, in Graphs, Maps, Trees. But that list doesn’t represent an achieved consensus. Moretti separates the eighteenth-century gothic novel from the late-nineteenth-century “imperial gothic.” But for other critics, those are two parts of the same genre. For yet other critics, the “gothic” isn’t a genre at all; it’s a mode like tragedy or satire, which is why gothic elements can pervade a bunch of different genres.
This is the darkest moment of this post. It may seem that there’s no hope for literary historians. How can we ever know anything if we can’t even agree on the definitions of basic concepts like genre and point of view? But here’s the crucial twist — and the real center of what I want to say. The blurriness of literary categories is exactly why it’s helpful to use computers for distant reading. With an algorithm, we can classify 500,000 volumes provisionally. Try defining point of view one way, and see what you get. If someone else disagrees, change the definition; you can run the algorithm again overnight. You can’t re-run a crowdsourced cataloguing project on 500,000 volumes overnight.
Second, algorithms make it easier to treat categories as plural and continuous. Although Star Trek teaches us otherwise, computers do not start to stammer and emit smoke if you tell them that an object belongs in two different categories at once. Instead of sorting texts into category A or category B, we can assign degrees of membership to multiple categories. As many as we want. So The Moonstone can be 80% similar to a sensation novel and 50% similar to an imperial gothic, and it’s not a problem. Of course critics are still going to disagree about individual cases. And we don’t have to pretend that these estimates are precise characterizations of The Moonstone. The point is that an algorithm can give us a starting point for discussion, by rapidly mapping a large collection in a consistent but flexibly continuous way.
Then we can ask, Does the gothic often overlap with the sensation novel? What other genres does it overlap with? Even if the boundaries are blurry, and critics disagree about every individual case — even if we don’t have a perfect definition of the term “genre” itself — we’ve now got a map, and we can start talking about the relations between regions of the map.
Can we actually do this? Can we use computers to map things like genre and point of view? Yes, to coin a phrase, we can. The truth is that you can learn a lot about a document just by looking at word frequency. That’s how search engines work, that’s how spam gets filtered out of your e-mail; it’s a well-developed technology. The Stanford Literary Lab suggested a couple of years ago that it would probably work for literary genres as well (see Pamphlet 1), and Matt Jockers has more detailed work forthcoming on genre and diction in Macroanalysis.
There are basically three steps to the process. First, get a training set of a thousand or so examples and tag the categories you want to recognize: poetry or prose, fiction or nonfiction, first- or third-person narration. Then, identify features (usually words) that turn out to provide useful clues about those categories. There are a lot of ways of doing this automatically. Personally, I use a Wilcoxon test to identify words that are consistently common or uncommon in one class relative to others. Finally, train classifiers using those features. I use what’s known as an “ensemble” strategy where you train multiple classifiers and they all contribute to the final result. Each of the classifiers individually uses an algorithm called “naive Bayes,” which I’m not going to explain in detail here; let’s just say that collectively, as a group, they’re a little less “naive” than they are individually — because they’re each relying on slightly different sets of clues.
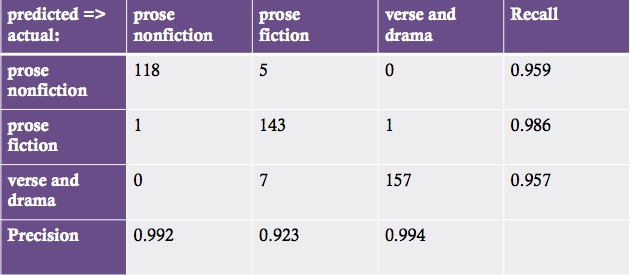
Confusion matrix from an ensemble of naive Bayes classifiers. (432 test documents held out from a larger sample of 1356.)
How accurate does this end up being? This confusion matrix gives you a sense. Let me underline that this is work in progress. If I were presenting finished results I would need to run this multiple times and give you an average value. But these are typical results. Here I’ve got a corpus of thirteen hundred nineteenth-century volumes. I train a set of classifiers on two-thirds of the corpus, and then test it by using it to classify the other third of the corpus which it hasn’t yet seen. That’s what I mean by saying 432 documents were “held out.” To make the accuracy calculations simple here, I’ve treated these categories as if they were exclusive, but in the long run, we don’t have to do that: documents can belong to more than one at once.
These results are pretty good, but that’s partly because this test corpus didn’t have a lot of miscellaneous collected works in it. In reality you see a lot of volumes that are a mosaic of different genres — the collected poems and plays of so-and-so, prefaced by a prose life of the author, with an index at the back. Obviously if you try to classify that volume as a single unit, it’s going to be a muddle. But I think it’s not going to be hard to use genre classification itself to segment volumes, so that you get the introduction, and the plays, and the lyric poetry sorted out as separate documents. I haven’t done that yet, but it’s the next thing on my agenda.
One complication I have already handled is historical change. Following up a hint from Michael Witmore, I’ve found that it’s useful to train different classifiers for different historical periods. Then when you get an uncategorized document, you can have each classifier make a prediction, and weight those predictions based on the date of the document.
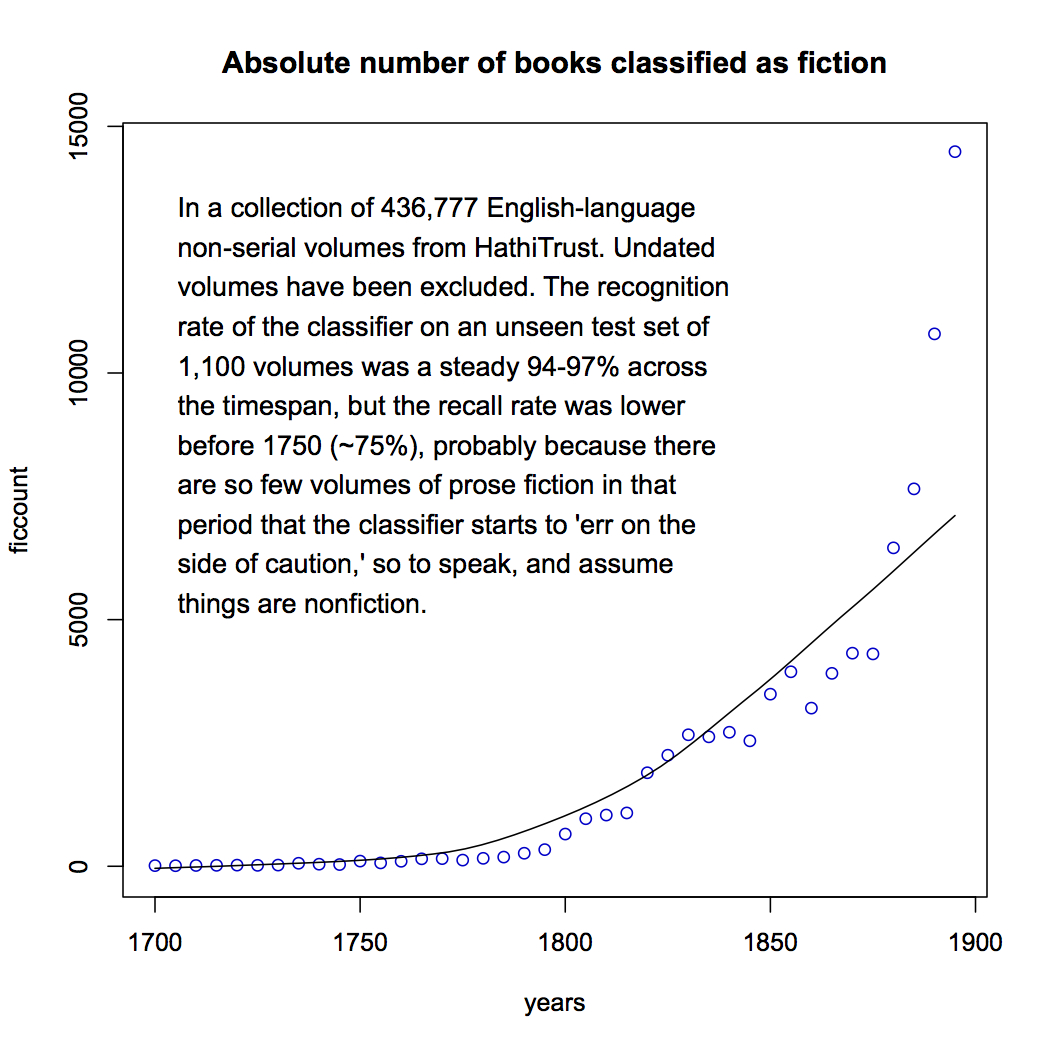
So what have I found? First of all, here’s the absolute number of volumes I was able to identify as fiction in HathiTrust’s collection of eighteenth and nineteenth-century English-language books. Instead of plotting individual years, I’ve plotted five-year segments of the timeline. The increase, of course, is partly just an absolute increase in the number of books published.
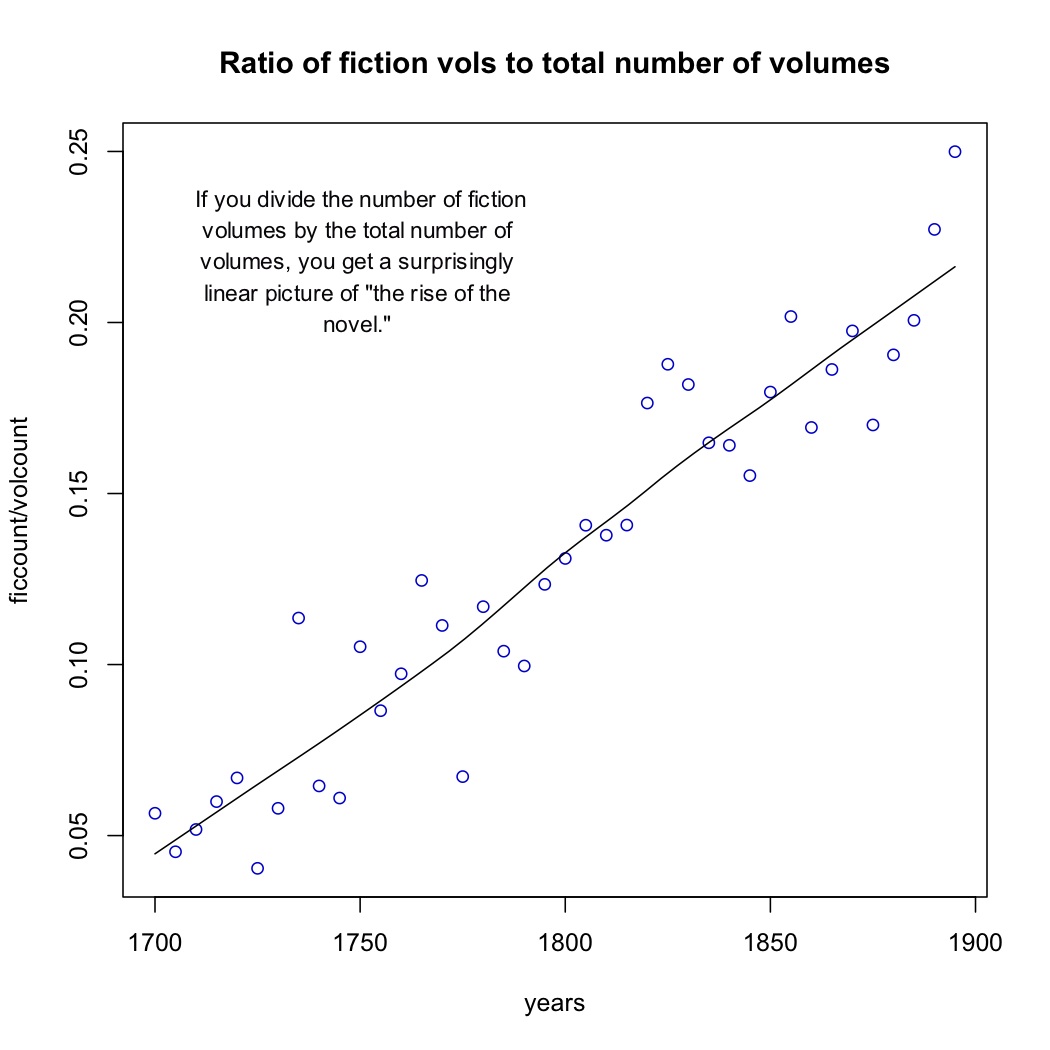
But it’s also an increase specifically in fiction. Here I’ve graphed the number of volumes of fiction divided by the total number of volumes in the collection. The proportion of fiction increases in a straightforward linear way. From 1700-1704, when fiction is only about 5% of the collection, to 1895-99, when it’s 25%. People better-versed in book history may already have known that this was a linear trend, but I was a bit surprised. (I should note that I may be slightly underestimating the real numbers before 1750, for reasons explained in the fine print to the earlier graph — basically, it’s hard for the classifier to find examples of a class that is very rare.)
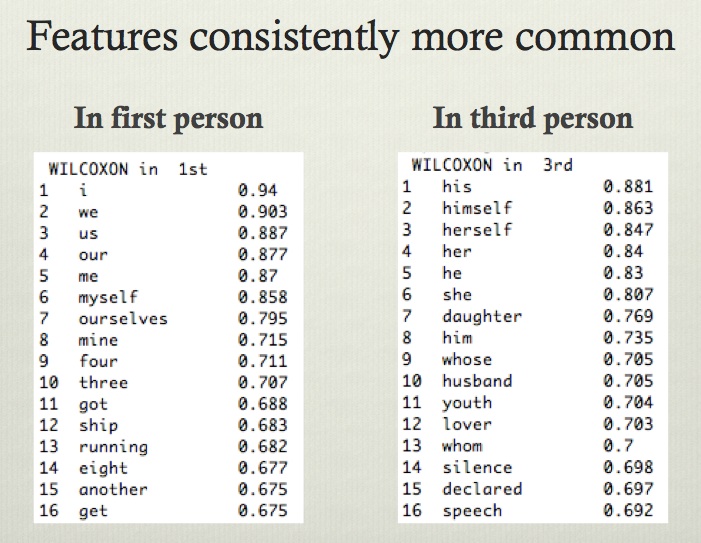
Features consistently more common in first- or third-person narration, ranked by Mann-Whitney-Wilcoxon rho.
What about the question we started with — first-person narration? I approach this the same way I approached genre classification. I trained a classifier on 290 texts that were clearly dominated by first- or third-person narration, and used a Wilcoxon test to select features that are consistently more common in one set or in the other.
Now, it might seem obvious what these features are going to be: obviously, we would expect first-person and third-person pronouns to be the most important signal. But I’m allowing the classifier to include whatever features it in practice finds. For instance, terms for domestic relationships like “daughter” and “husband” and the relative pronouns “whose” and “whom” are also consistently more common in third-person contexts, and oddly, numbers seem more common in first-person contexts. I don’t know why that is yet; this is work in progress and there’s more exploration to do. But for right now I haven’t second-guessed the classifier; I’ve used the top sixteen features in both lists whether they “make sense” or not.
And this is what I get. The classifier predicts each volume’s probability of belonging to the class “first person.” That can be anywhere between 0 and 1, and it’s often in the middle (Bleak House, for instance, is 0.54). I’ve averaged those values for each five-year interval. I’ve also dropped the first twenty years of the eighteenth century, because the sample size was so low there that I’m not confident it’s meaningful.
Now, there’s a lot more variation in the eighteenth century than in the nineteenth century, partly because the sample size is smaller. But even with that variation it’s clear that there’s significantly more first-person narration in the eighteenth century. About half of eighteenth-century fiction is first-person, and in the nineteenth century that drops down to about a quarter. That’s not something I anticipated. I expected that there might be a gradual decline in the amount of first-person narration, but I didn’t expect this clear and relatively sudden moment of transition. Obviously when you see something you don’t expect, the first question you ask is, could something be wrong with the data? But I can’t see a source of error here. I’ve cleaned up most of the predictable OCR errors in the corpus, and there aren’t more medial s’s in one list than in the other anyway.
And perhaps this picture is after all consistent with our expectations. Eleanor Courtemanche points out that the timing of the shift to third person is consistent with Ian Watt’s account of the development of omniscience (as exemplified, for instance, in Austen). In a quick twitter poll I carried out before announcing the result, Jonathan Hope did predict that there would be a shift from first-person to third-person dominance, though he expected it to be more gradual. Amanda French may have gotten the story up to 1810 exactly right, although she expected first-person to recover in the nineteenth century. I expected a gradual decline of first-person to around 1810, and then a gradual recovery — so I seem to have been completely wrong.
The ratio between raw counts of first- and third-person pronouns in fiction.
Much more could be said about this result. You could decide that I’m wrong to let my classifier use things like numbers and relative pronouns as clues about point of view; we could restrict it just to counting personal pronouns. (That won’t change the result very significantly, as you can see in the illustration on the right — which also, incidentally, shows what happens in those first twenty years of the eighteenth century.) But we could refine the method in many other ways. We could exclude pronouns in direct discourse. We could break out epistolary narratives as a separate category.
All of these things should be tried. I’m explicitly not claiming to have solved this problem yet. Remember, the thesis of this talk is that we don’t understand literary history. In fact, I think the point of posing these questions on a large scale is partly to discover how slippery they are. I realize that to many people that will seem like a reason not to project literary categories onto a macroscopic scale. It’s going to be a mess, so — just don’t go there. But I think the mess is the reason to go there. The point is not that computers are going to give us perfect knowledge, but that we’ll discover how much we don’t know.
For instance, I haven’t figured out yet why numbers are common in first-person narrative, but I suspect it might be because there’s a persistent affinity with travel literature. As we follow up leads like that we may discover that we don’t understand point of view itself as well as we assume.
It’s this kind of complexity that will ultimately make classification interesting. It’s not just about sorting things into categories, but about identifying the places where a category breaks down or has changed over time. I would draw an analogy here to a paper on “Gender in Twitter” recently published by a group of linguists. They used machine learning to show that there are not two but many styles of gender performance on Twitter. I think we’ll discover something similar as we explore categories like point of view and genre. We may start out trying to recognize known categories, like first-person narration. But when you sort a large collection into categories, the collection eventually pushes back on your categories as much as the categories illuminate the collection.
Acknowledgments: This research was supported by the Andrew W. Mellon Foundation through “Expanding SEASR Services” and “The Uses of Scale in Literary Study.” Loretta Auvil, Mike Black, and Boris Capitanu helped develop resources for normalizing 18/19c OCR, many of which are public at usesofscale.com. Jordan Sellers developed the initial training corpus of 19c documents categorized by genre.
I’m getting ahead of myself with this post, because I don’t have time to explain everything I did to produce this. But it was just too striking not to share.
Basically, I’m experimenting with Latent Dirichlet Allocation, and I’m impressed. So first of all, thanks to Matt Jockers, Travis Brown, Neil Fraistat, and everyone else who tried to convince me that Bayesian methods are better. I’ve got to admit it. They are.
But anyway, in a class I’m teaching we’re using LDA on a generically diverse collection of 1,853 volumes between 1751 and 1903. The collection includes fiction, poetry, drama, and a limited amount of nonfiction (just biography). We’re stumbling on a lot of fascinating things, but this was slightly moving. Here’s the graph for one particular topic.
The circles and X’s are individual volumes. Blue is fiction, green is drama, pinkish purple is poetry, black biography. Only the volumes where this topic turned out to be prominent are plotted, because if you plot all 1,853 it’s just a blurry line at the bottom of the image. The gray line is an aggregate frequency curve, which is not related in any very intelligible way to the y-axis. (Work in progress …) As you can see. this topic is mostly prominent in fiction around the year 1800. Here are the top 50 words in the topic:
But here’s what I find slightly moving. The x’s at the top of the graph are the 10 works in the collection where the topic was most prominent. They include, in order, Mary Wollstonecraft Shelley, Frankenstein, Mary Wollstonecraft, Mary, William Godwin, St. Leon, Mary Wollstonecraft Shelley, Lodore, William Godwin, Fleetwood, William Godwin, Mandeville, and Mary Wollstonecraft Shelley, Falkner.
In short, this topic is exemplified by a family! Mary Hays does intrude into the family circle with Memoirs of Emma Courtney, but otherwise, it’s Mary Wollstonecraft, William Godwin, and their daughter.
Other critics have of course noticed that M. W. Shelley writes “Godwinian novels.” And if you go further down the list of works, the picture becomes less familial (Helen Maria Williams and Thomas Holcroft butt in, as well as P. B. Shelley). Plus, there’s another topic in the model (“myself these should situation”) that links William Godwin more closely to Charles Brockden Brown than it does to his wife or daughter. And LDA isn’t graven on stone; every time you run topic modeling you’re going to get something slightly different. But still, this is kind of a cool one. “Mind feelings heart felt” indeed.
Giving a talk this morning at the MLA. There are two main arguments:
1) The first one will be familiar if you’ve read my blog. I suggest that the boundary between “text mining” and conventional literary research is far fuzzier than people realize. There appears to be a boundary only because literary scholars are pretty unreflective about the way we’re currently using full-text search. I’m going to press this point in detail, because it’s not just a metaphor: to produce a simple but useful topic-modeling algorithm, all you have to do is take a search engine and run it backwards.
2) The second argument is newer; I don’t think I’ve blogged about it yet. I’m going to present topic modeling as a useful bridge between “distant” and “close” reading. I’ve found that I often learn most about a genre by modeling it as part of a larger collection that includes many other genres. In that context, a topic-modeling algorithm can highlight peculiar convergences of themes that characterize the genre relative to its contemporary backdrop. a slide from the talk, where a simple topic-modeling algorithm has been used to produce a dendrogram that offers a clue about the temporal framing of narration in late-18c novels
This is distant reading, in the sense that it requires a large collection. But it’s also close reading, in the sense that it’s designed to reveal subtle formal principles that shape individual works, and that might otherwise elude us.
Having just returned from a conference of Romanticists, I’m in a mood to reflect a bit about the relationship between text mining and the broader discipline of literary studies. This entry will be longer than my usual blog post, because I think I’ve got an argument to make that demands a substantial literary example. But you can skip over the example to extract the polemical thesis if you like!
At the conference, I argued that literary critics already practice a crude form of text mining, because we lean heavily on keyword search when we’re tracing the history of a topic or discourse. I suggested that information science can now offer us a wider range of tools for mapping archives — tools that are subtler, more consonant with our historicism, and maybe even more literary than keyword search is.
At the same time, I understand the skepticism that many literary critics feel. Proving a literary thesis with statistical analysis is often like cracking a nut with a jackhammer. You can do it: but the results are not necessarily better than you would get by hand.
One obvious solution would be to use text mining in an exploratory way, to map archives and reveal patterns that a critic could then interpret using nuanced close reading. I’m finding that approach valuable in my own critical practice, and I’d like to share an example of how it works. But I also want to reflect about the social forces that stand in the way of this obvious compromise between digital and mainstream humanists — leading both sides to assume that quantitative analysis ought to contribute instead by proving literary theses with increased certainty. Part of a topic tree based on a generically diverse collection of 2200 18c texts.
I’ll start with an example. If you don’t believe text mining can lead to literary insights, bear with me: this post starts with some goofy-looking graphs, but develops into an actual hypothesis about the Romantic novel based on normal kinds of literary evidence. But if you’re willing to take my word that text-mining can produce literary leads, or simply aren’t interested in Romantic-era fiction, feel free to skip to the end of this (admittedly long!) post for the generalizations about method.
Several months ago, when I used hierarchical clustering to map eighteenth-century diction on this blog, I pointed to a small section of the resulting tree that intriguingly mixed language about feeling with language about time. It turned out that the words in this section of the tree were represented strongly in late-eighteenth-century novels (novels, for instance, by Frances Burney, Sophia Lee, and Ann Radcliffe). Other sections of the tree, associated with poetry or drama, had a more vivid kind of emotive language, and I wondered why novels would combine an emphasis on feeling or exclamation (“felt,” “cried”) with the abstract topic of duration (“moment,” “longer”). It seemed an oddly phenomenological way to think about emotion.
But I also realized that hierarchical clustering is a fairly crude way of mapping conceptual space in an archive. The preferred approach in digital humanities right now is topic modeling, which does elegantly handle problems like polysemy. However, I’m not convinced that existing methods of topic modeling (LDA and so on) are flexible enough to use for exploration. One of their chief advantages is that they don’t require the human user to make judgment calls: they automatically draw boundaries around discrete “topics.” But for exploratory purposes boundaries are not an advantage! In exploring an archive, the goal is not to eliminate ambiguity so that judgment calls are unnecessary: the goal is to reveal intriguing ambiguities, so that the human user can make judgments about them.
If this is our goal, it’s probably better to map diction as an associative web. Fortunately, it was easy to get from the tree to a web, because the original tree had been based on an algorithm that measured the strength of association between any two words in the collection. Using the same algorithm, I created a list of twenty-five words most strongly associated with the branch that had interested me (“instantly,” “cried,” “felt,” moment,” “longer,”) and then used the strengths of association between those words to model the whole list as a force-directed graph. In this graph, words are connected by “springs” that pull them closer together; the darker the line, the stronger the association between the two words, and the more tightly they will be bound together in the graph. (The sizes of words are loosely proportional to their frequency in the collection, but only very loosely.)
A graph like this is not meant to be definitive: it’s a brainstorming tool that helps me explore associations in a particular collection (here, a generically diverse collection of eighteenth-century writing). On the left side, we see a triangle of feminine pronouns (which are strongly represented in the same novels where “felt,” “moment,” and so on are strongly represented) as well as language that defines domestic space (“quitting,” “room”). On the right side of the graph, we see a range of different kinds of emotion. And yet, looking at the graph as a whole, there is a clear emphasis on an intersection of feeling and time — whether the time at issue is prospective (“eagerly,” “hastily,” “waiting”) or retrospective (“recollected,” “regret”).
In particular, there are a lot of words here that emphasize temporal immediacy, either by naming a small division of time (“moment,” “instantly”), or by defining a kind of immediate emotional response (“surprise,” “shocked,” “involuntarily”). I have highlighted some of these words in red; the decision about which words to include in the group was entirely a human judgment call — which means that it is open to the same kind of debate as any other critical judgment.
But the group of words I have highlighted in red — let’s call it a discourse of temporal immediacy — does turn out to have an interesting historical profile. We already know that this discourse was common in late-eighteenth-century novels. But we can learn more about its provenance by restricting the generic scope of the collection (to fiction) and expanding its temporal scope to include the nineteenth as well as eighteenth centuries. Here I’ve graphed the aggregate frequency of this group of words in a collection of 538 works of eighteenth- and nineteenth-century fiction, plotted both as individual works and as a moving average. [The moving average won’t necessarily draw a line through the center of the “cloud,” because these works vary greatly in size. For instance, the collection includes about thirty of Hannah More’s “Cheap Repository Tracts,” which are individually quite short, and don’t affect the moving average more than a couple of average-sized novels would, although they create an impressive stack of little circles in the 1790s.]
The shape of the curve here suggests that we’re looking at a discourse that increased steadily in prominence through the eighteenth century and peaked (in fiction) around the year 1800, before sinking back to a level that was still roughly twice its early-eighteenth-century frequency.
Why might this have happened? It’s always a good idea to start by testing the most boring hypothesis — so a first guess might be that words like “moment” and “instantly” were merely displacing some set of close synonyms. But in fact most of the imaginable synonyms for this set of words correlate very closely with them. (This is true, for instance, of words like “sudden,” “abruptly,” and “alarm.”)
Another way to understand what’s going on would be to look at the works where this discourse was most prominent. We might start by focusing on the peak between 1780 and 1820. In this period, the works of fiction where language of temporal immediacy is most prominent include
Charlotte Dacre, Zofloya (1806)
Charlotte Lennox, Hermione, or the Orphan Sisters (1791)
M. G. Lewis, The Monk (1796)
Ann Radcliffe, A Sicilian Romance (1790), The Castles of Athlin and Dunbayne (1789), and The Romance of the Forest (1792)
Frances Burney, Cecilia (1782) and The Wanderer (1814)
Amelia Opie, Adeline Mowbray (1805)
Sophia Lee, The Recess (1785)
There is a strong emphasis here on the Gothic, but perhaps also, more generally, on women writers. The works of fiction where the same discourse is least prominent would include
Hannah More, most of her “Cheap Repository Tracts” and Coelebs in Search of a Wife (1809)
Robert Bage, Hermsprong (1796)
John Trusler, Life; or the Adventures of William Ramble (1793)
Maria Edgeworth, Castle Rackrent (1800)
Arnaud Berquin, The Children’s Friend (1788)
Isaac Disraeli, Vaurien; or, Sketches of the Times (1797)
Many of these works are deliberately old-fashioned in their approach to narrative form: they are moral parables, or stories for children, or first-person retrospective narratives (like Rackrent), or are told by Fieldingesque narrators who feel free to comment and summarize extensively (as in the works by Disraeli and Trusler).
After looking closely at the way the language of temporal immediacy is used in Frances Burney, Cecilia (1782), and Sophia Lee, The Recess (1785), it seems to me that it had both a formal and an affective purpose.
Formally, it foregrounded a newly sharp kind of temporal framing. If we believe Ian Watt, part of the point of the novel form is to emulate the immediacy of first-hand experience — a purpose that can be slightly at odds with the retrospective character of narrative. Eighteenth-century novelists fought the distancing effect of retrospection in a lot of ways: epistolary narrative, discovered journals and so on are ways of bringing the narrative voice as close as possible to the moment of experience. But those tricks have limits; at some point, if your heroine keeps running off to write breathless letters between every incident, Henry Fielding is going to parody you.
By the late eighteenth century it seems to me novelists were starting to work out ways of combining temporal immediacy with ordinary retrospective narration. Maybe you can’t literally have your narrator describe events as they’re taking place, but you can describe events in a way that highlights their temporal immediacy. This is one of the things that makes Frances Burney read more like a nineteenth-century novelist than like Defoe; she creates a tight temporal frame for each event, and keeps reminding her readers about the tightness of the frame. So, a new paragraph will begin “A few moments after he was gone …” or “At that moment Sir Robert himself burst into the Room …” or “Cecilia protested she would go instantly to Mr Briggs,” to choose a few examples from a single chapter of Cecilia (my italics, 363-71). We might describe this vaguely as a way of heightening suspense — but there are of course many different ways to produce suspense in fiction. Narratology comes closer to the question at issue when it talks about “pacing,” but unless someone has already coined a better term, I think I would prefer to describe this late-18c innovation as a kind of “temporal framing,” because the point is not just that Burney uses “scene” rather than “summary” to make discourse time approximate story time — but that she explicitly divides each “scene” into a succession of discrete moments.
There is a lot more that could be said about this aspect of narrative form. For one thing, in the Romantic era it seems related to a particular way of thinking about emotion — a strategy that heightens emotional intensity by describing experience as if it were divided into a series of instananeous impressions. E.g, “In the cruelest anxiety and trepidation, Cecilia then counted every moment till Delvile came …” (Cecilia, 613). Characters in Gothic fiction are “every moment expecting” some start, shock, or astonishment. “The impression of the moment” is a favorite phrase for both Burney and Sophia Lee. On one page of The Recess, a character “resign[s] himself to the impression of the moment,” although he is surrounded by a “scene, which every following moment threatened to make fatal” (188, my italics).
In short, fairly simple tools for mapping associations between words can turn up clues that point to significant formal, as well as thematic, patterns. Maybe I’m wrong about the historical significance of those patterns, but I’m pretty sure they’re worth arguing about in any case, and I would never have stumbled on them without text mining.
On the other hand, when I develop these clues into a published article, the final argument is likely to be based largely on narratology and on close readings of individual texts, supplemented perhaps by a few simple graphs of the kind I’ve provided above. I suppose I could master cutting-edge natural language processing, in order to build a fabulous tool that would actually measure narrative pace, and the division of scenes into incidents. That would be fun, because I love coding, and it would be impressive, since it would prove that digital techniques can produce literary evidence. But the thing is, I already have an open-source application that can measure those aspects of narrative form, and it runs on inexpensive hardware that requires only water, glucose, and caffeine.
The methodological point I want to make here is that relatively simple forms of text mining, based on word counts, may turn out to be the techniques that are in practice most useful for literary critics. Moreover, if I can speak frankly: what makes this fact hard for us to acknowledge is not technophilia per se, but the nature of the social division between digital humanists and mainstream humanists. Literary critics who want to dismiss text mining are fond of saying “when you get right down to it, it’s just counting words.” (At moments like this we seem to forget everything 20c literary theorists ever learned from linguistics, and go back to treating language as a medium that ideally, ought to be immaterial and transparent. Surely a crudely verbal approach — founded on lumpy, ambiguous words — can never tell us anything about the conceptual subtleties of form and theme!) Stung by that critique, digital humanists often feel we have to prove that our tools can directly characterize familiar literary categories, by doing complex analyses of syntax, form, and sentiment.
I don’t want to rule out those approaches; I’m not interested in playing the game “Computers can never do X.” They probably can do X. But we’re already carrying around blobs of wetware that are pretty good at understanding syntax and sentiment. Wetware is, on the other hand, terrible at counting several hundred thousand words in order to detect statistical clues. And clues matter. So I really want to urge humanists of all stripes to stop imagining that text mining has to prove its worth by proving literary theses.
That should not be our goal. Full-text search engines don’t perform literary analysis at all. Nor do they prove anything. But literary scholars find them indispensable: in fact, I would argue that search engines are at least partly responsible for the historicist turn in recent decades. If we take the same technology used in those engines (a term-document matrix plus vector space math), and just turn the matrix on its side so that it measures the strength of association between terms rather than documents, we will have a new tool that is equally valuable for literary historians. It won’t prove any thesis by itself, but it can uncover a whole new range of literary questions — and that, it seems to me, ought to be the goal of text mining.
References
Frances Burney, Cecilia; or, Memoirs of an Heiress, ed. Peter Sabor and Margaret Ann Doody (Oxford: OUP, 1999).
Sophia Lee, The Recess; or, a Tale of Other Times, ed. April Alliston (Lexington: UP of Kentucky, 2000).
[Postscript: This post, originally titled “How to make text mining serve literary history,” is a version of a talk I gave at NASSR 2011 in Park City, Utah, sharpened by the discussion that took place afterward. I’d like to thank the organizers of the conference (Andrew Franta and Nicholas Mason) as well as my co-panelists (Mark Algee-Hewitt and Mark Schoenfield) and everyone in the audience. The original slides are here; sometimes PowerPoint can be clearer than prose.
I don’t mean to deny, by the way, that the simple tools I’m using could be refined in many ways — e.g., they could include collocations. What I’m saying is I that don’t think we need to wait for technical refinements. Our text-mining tools are already sophisticated enough to produce valuable leads, and even after we make them more sophisticated, it will remain true that at some point in the critical process we have to get off the bicycle and walk.]