

This blog post is loosely connected to a talk I’m giving (virtually) at the Workshop on Narrative Understanding, Storylines, and Events at the ACL. It’s an informal talk, exploring some of the challenges and opportunities we encounter when we take the impressive sentence-level tools of contemporary NLP and try to use them to produce insights about book-length documents.
Questions about the “predictability” of fiction started to interest me after I read a preprint by Maarten Sap et al. on the difference between “recollected” and “imagined” stories. There’s a lot in the paper, but the thing that especially caught my eye was that a neural language model (GPT) does better predicting the next sentence in imagined stories than in recollected stories about biographical events. The authors persuasively interpret this as a sign that imagined stories have been streamlined by a process of “narrativization.”
The stories in that article are very short narratives made up (or recalled) by experimental subjects. But, given my background in literary history, I wondered whether the same contrast might appear between book-length works of fiction and biography. Are fictional narratives in some sense more predictable than nonfiction?
One could say we already know the answer. Fiction is governed by plot conventions, so of course it makes sense that it’s predictable! But an equally intuitive argument could be made that fiction entertains readers by baffling and eluding their expectations about what, specifically, will happen next. Perhaps it ought to be less predictable than nonfiction? In short, there are basic questions about fiction that don’t have clear general answers yet, although we’re getting better at framing the questions. (See e.g. Caroline Levine on The Serious Pleasures of Suspense, Vera Tobin on Elements of Surprise, or Andrew Piper’s chapters on “Plot” and “Fictionality” in Enumerations.)
Plus, even if it were intuitively obvious that fiction is more strongly governed by plot conventions than by surprise, it might be interesting to measure the strength of those conventions in particular works. If we could do that, we’d have new evidence for a host of familiar debates about tradition and innovation.
So, how to do it? Sap et al. measure “narrative flow” by using a neural language model that can judge whether a sentence is likely to occur in a given context. It’s a good strategy for paragraph or page-sized stories, but I suspect sentences may be too small to capture the things we would call “predictable plot patterns” in novels. However, it wasn’t hard to give this strategy a spin, so I did, using a language model called BERT to assess pairs of sentences from 32 biographies and 32 novels. (This is just a toy-sized sample for a semi-thought-experiment; I’m not pretending to finally resolve anything.) At each step, in each book, I asked BERT to judge the probability that sentence B would really follow sentence A. (The code I used is in a GitHub repo.)
The result I got was the opposite of the one reported in Sap et al. There is a statistically significant difference between biography and fiction, but the pairs of sentences in biography appeared more predictable—more likely to follow each other—than the sentences in fiction. I hasten to say, however, that this could be wrong in several ways. First, BERT’s perception that two sentences are likely to follow each other correlates strongly with the length of the sentences. Short sentences (like most sentences in dialogue) seem less clearly connected. Since there’s a lot of dialogue in published fiction, BERT might be, in effect, biased against fiction.

More importantly, sentence-level continuity isn’t necessarily a good measure of surprise in novel-length works. For instance, in fig. 1, you’ll notice that BERT is unruffled when Pride and Prejudice morphs into Flatland. As long as each sentence picks up some discursive cue from the one before, BERT perceives the pairs as plausibly connected. But by the fourth sentence in the chain, Mr Bennet is listening to a lecture from a translucent, blue, four-dimensional being in his sitting room. Human readers would probably be surprised if this happened.
There are ways to generate “sentence embeddings” that might correspond more closely to human surprise. (This is a crowded field, but see for instance Sentence-BERT, Reimers and Gurevych 2019.) Even primitive 2014-era GloVe embeddings do a somewhat better job (Pennington, Socher, and Manning 2014). By averaging the GloVe embeddings for all the words in a sentence, we can represent each sentence as a vector of length 300. Then we can measure the cosine distances between sentences, as I’ve done in the third column of Fig 1. (Here, large numbers indicate a big gap between sentences; it’s the reverse of the “probability” measure provided by BERT, where high numbers represent continuity.) This model of distance is (appropriately) more surprised by the humming blue sphere in row three than by the short sentence of dialogue in row five.
But even if we had a good measure of continuity, sentences might just be too small to capture the patterns that count as “predictability” in a novel. As the example in fig. 1 suggests, a sequence of short steps, individually unsurprising, can leave the reader in a world very different from the place they started. Continuity of this kind is not the “predictability” we would want to measure at book scale.
When readers talk about predictable or unpredictable stories, they’re probably thinking about specific problem situations and possible outcomes. Will the protagonist marry suitor A or suitor B? Can we guess? It may soon be possible to automatically extract implicit questions of this kind from fiction. And the Story Cloze task (Mostafazadeh et al.) showed that it’s possible to answer “what happens next” at paragraph scale. But right now I don’t know how to extract implicit questions, or answer them, at the scale of a novel. So let’s try a simpler—in fact minimal— predictive task. Given two passages selected at random from a book, can we predict which came first? Doing that won’t tell us anything about plot—if “plot” is a causal connection between events. But it will tell us whether book-length works are organized by any predictable large-scale patterns. (As we’ll see in a moment, this is a real question, and in some genres the answer might be “not really.”)
The vector-space representation we developed in the third column of Fig. 1 can be scaled up for this question. “Paragraphs” and “chapters” mean different things in different periods, so for now, it may be better simply to divide stories into arbitrary thousand-word passages. Each passage will be represented as a vector by averaging the GloVe embeddings for the words in it; we’ll subtract one passage from the other and use the difference to decide whether A came before B in the book, or vice-versa.
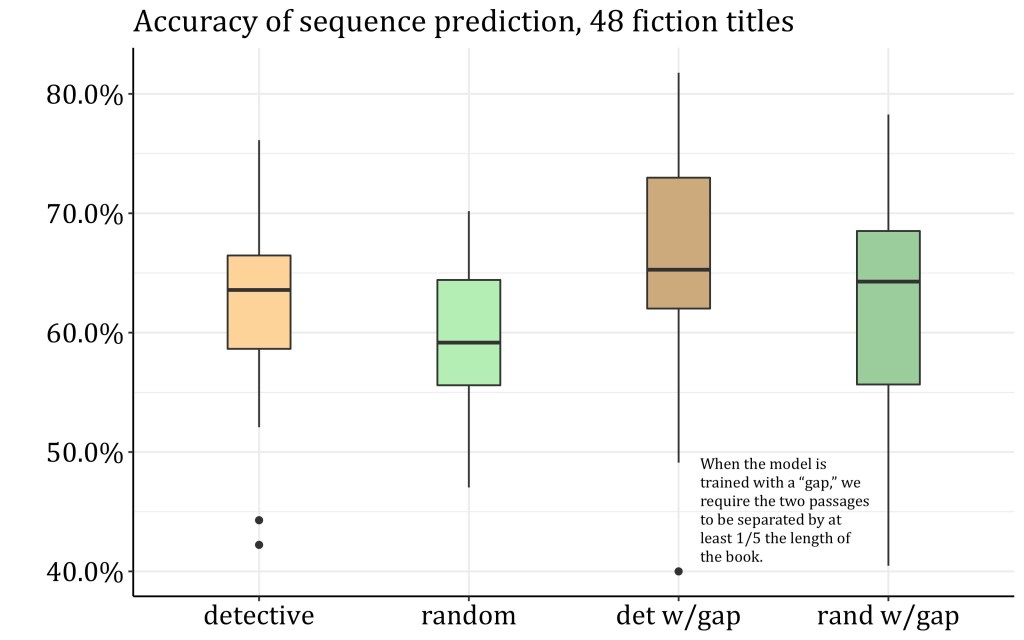
Random accuracy for this task would be 50%, but a model trained on a reasonable number of novels can easily achieve 65-66%, especially if the novels are all in the same genre. That number may not sound impressive, but I suspect it’s not much worse than human accuracy would be—if a human reader were asked to draw the arrow of time connecting two random passages from an unfamiliar book.
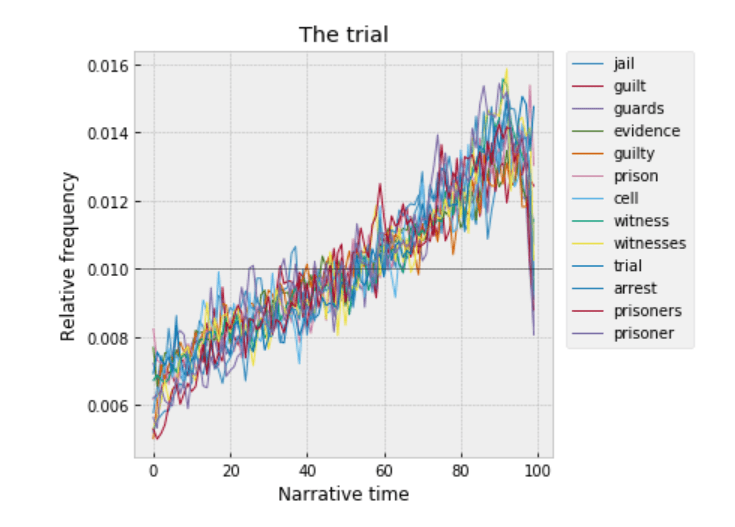
In fact, why is it possible to do this at all? Since the two passages may be separated by a hundred-odd pages, our model clearly isn’t registering any logical relationships between events. Instead, it’s probably relying on patterns described in previous work by David McClure and Scott Enderle. McClure and Enderle have shown that there are strong linguistic gradients across narrative time in fiction. References to witnesses, guilt, and jail, for instance, tend to occur toward the end of a book (if they occur at all).
Our model may draw even stronger clues from simple shifts of rhetorical perspective like the one in figure 3: indefinite articles appear early in a book, when “a mysterious old man” enters “a room.” A few pages later, he will either acquire a name or become “the old man” in “the room.”
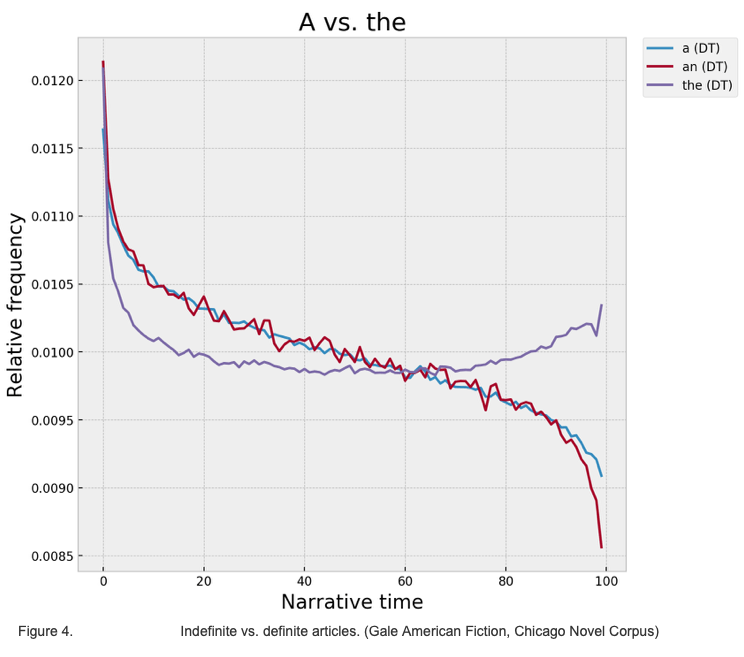
We probably wouldn’t call that shift of perspective “plot.” On the other hand, before we dismiss these gradients as merely linguistic rather than narrative phenomena, it’s worth noting that they seem to be specific to fiction. When I try to use the same general strategy to predict the direction of time between pairs of passages in biographies, the model struggles to do better than random guessing. Even with the small toy sample I’m using below (32 novels and 32 biographies), there is clearly a significant difference between the two genres. So, although BERT may not see it, fictional narratives are more predictable than nonfiction ones when we back out to look at the gradient of time across a whole book. There is a much clearer difference between before and after in fiction.
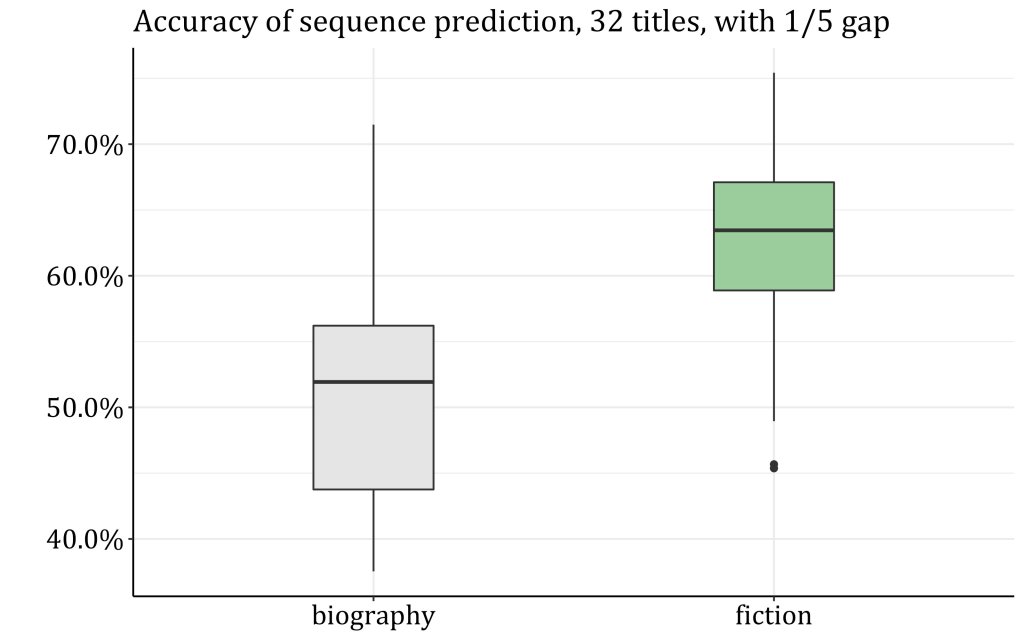
“A predictable difference between before and after” is something a good bit cruder than we ordinarily mean by “plot.” But the fact that this difference is specific to fiction makes me think that a model of this kind may after all confirm some part of what we meant in speculating “fictional plots are shaped by conventions that make them more predictable than nonfiction.”
Of course, to really understand plot, we will need to pair these loose book-sized arcs with a more detailed understanding of the way characters’ actions are connected as we move from one page to the next. For that kind of work, I invite you to survey the actual papers accepted for the Workshop on Narrative Understanding <gestures at the program>, which are advancing the state of the art, for instance, on event extraction.
But I can’t resist pointing out that even the crude vector-space model I have played with here can give us some leverage on page-level surprise, and in doing so, complicate the story I’ve just told. One odd detail I’ve noticed is that the predictability of a narrative at book scale (measured as our ability to predict the direction of time between two widely separated passages) correlates with a kind of unpredictability as we move from one sentence, page, or thousand-word passage to the next.
For instance, one way to describe the stability of a sequence is to measure “autocorrelation.” If we shift a time series relative to itself, moving it back by one step, how much does the original series correlate with the lagged version?
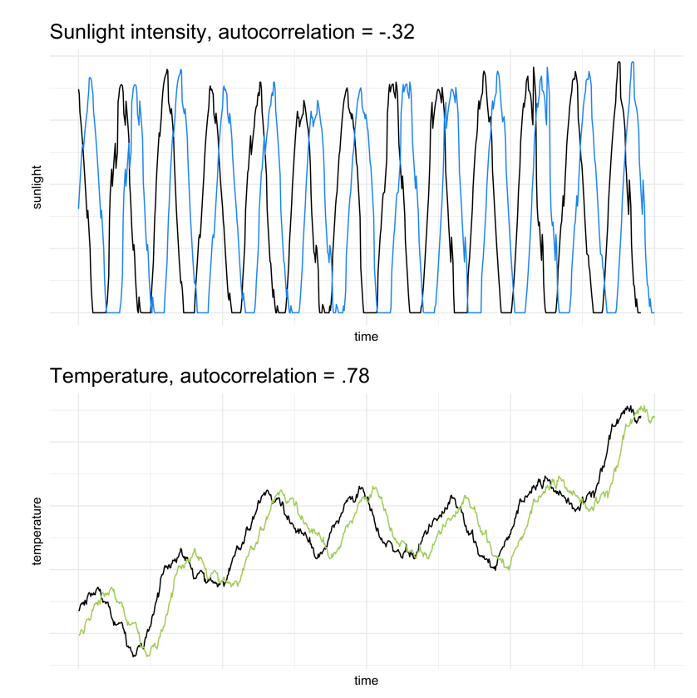
A process with a lot of inertia (e.g., change in temperature across a year) might still have the same basic shape if we shift it backward eight hours. The amount of sunlight in Seattle, on the other hand, fluctuates daily and will be largely out of phase with itself if we shift it backward eight hours; the correlation between those two curves will be pretty low, or even negative as above.
Since we’re representing each passage of a book as a vector of 300 numbers, this gives us 300 time series—300 curves—for each volume. It is difficult to say what each curve represents; the individual components of a word embedding don’t come with interpretable labels. But we can measure the narrative’s general degree of inertia by asking how strongly these curves are, collectively, autocorrelated. Crudely: I shift each time series back one step (1000 words) and measure the Pearson correlation coefficient between the lagged and unlagged version. Then I take the mean correlation for all 300 series.*
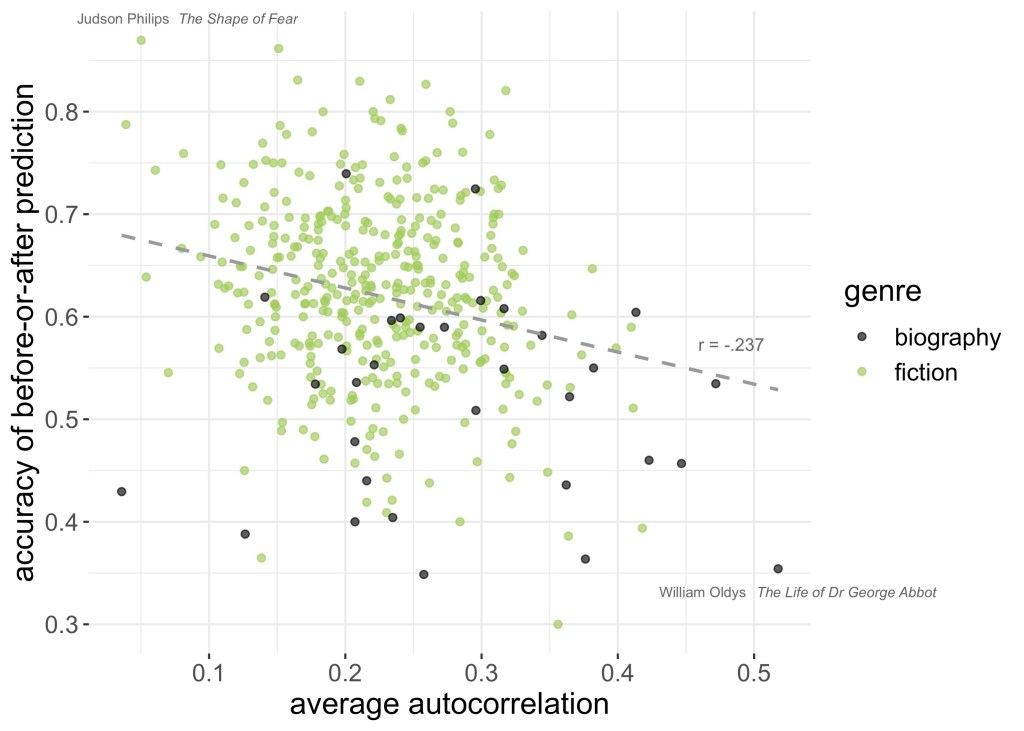
The result is unintuitive. You might think it would be easier to predict the direction of narrative time in books where variables change slowly—as temperature does—tracing a reliable arc. But instead it turns out that prediction is more accurate in books where these curves behave a bit like sunlight, fluctuating substantially every 1000 words. (The linear relationship with autocorrelation is r = -.237 in fig 7, though I suspect the real relationship isn’t linear.) Also, biography appears to be distinguished from fiction by higher autocorrelation (lower volatility).
So yes, fiction is more predictable than nonfiction across the sweep of a whole narrative (because the beginnings and ends of novels are rhetorically very distinct). But the same observation doesn’t necessarily hold as we move from page to page, or sentence to sentence. At that scale, fiction may be more volatile than nonfiction is. I don’t yet know why! We could speculate that this has something to do with an imperative to surprise the reader—but it might also be as simple as the alternation of dialogue and description, which creates a lot of rapid change in the verbal texture of fiction. In short, I’m pointing to a question rather than answering one. There appear to be several different kinds of “predictability” in narrative, and teasing them apart might give us some simple insights into the structural differences between fiction and nonfiction.
- Postscript: Everything above is speculative and exploratory. I’ve shared some code and data in a repository, but I wouldn’t call it fully replicable. There are more sophisticated ways to measure autocorrelation. If any economists read this, it will occur to them that we could also “predict the future course of a story” using full vector autoregression or an ARIMA model. I’ve tried that, but my sense is that the results were actually dominated by the two factors explored separately above (before-and-after predictability and the autocorrelation of individual variables with themselves). Also, to make any of this really illuminate literary history, we will need a bigger and better corpus, allowing us to ask how patterns like this intersect with genre, prestige, and historical change. A group of researchers at Illinois, including Wenyi Shang and Peizhen Wu, are currently pursuing those questions.
References:
Edwin A. Abbott, Flatland: A Romance of Many Dimensions (London: 1884).
Sanjeev Arora, Yingyu Liang, Tengyu Ma, “A Simple but Tough-to-Beat Baseline for Sentence Embeddings.” ICLR 2017.
Austen, Jane. Pride and Prejudice. London: Egerton, 1813.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
Caroline Levine, The Serious Pleasures of Suspense (Charlottesville, University of Virginia Press, 2003).
David McClure, “A Hierarchical Cluster of Words Across Narrative Time,” 2017.
Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, James Allen. A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories. NAACL 2016.
Shay Palachy, “Document Embedding Techniques: A Review of Notable Literature on the Topic,” Towards Data Science, September 9, 2019.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. EMNLP 2014.
Andrew Piper, Enumerations (Chicago: University of Chicago Press, 2018).
Nils Reimers and Iryna Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” EMNLP-IJCNLP 2019.
Maarten Sap, Eric Horvitz, Yejin Choi, Noah A. Smith, James Pennebaker. Recollection Versus Imagination: Exploring Human Memory and Cognition via Neural Language Models. ACL 2020.
Vera Tobin, Elements of Surprise: Our Mental Limits and the Satisfactions of Plot (Cambridge: Harvard University Press, 2018).

8 replies on “How predictable is fiction?”
[…] Read full post here. […]
Thanks for the great post Ted! I was wondering, what were the 32 works of fiction you used and if you had any ideas for collecting a larger corpus?
[…] Read More […]
[…] How Predictable Is Fiction? (tedunderwood.com) […]
“The difference between fiction and reality is that fiction has to make sense” – Tom Clancy
[…] by /u/nastratin [link] […]
[…] few weeks ago, I came across a blog post entitled “How predictable is fiction?”. The author, Ted Underwood, attempts to measure the predictability of a narrative by relying on […]
Thank you for sharing, it’s great