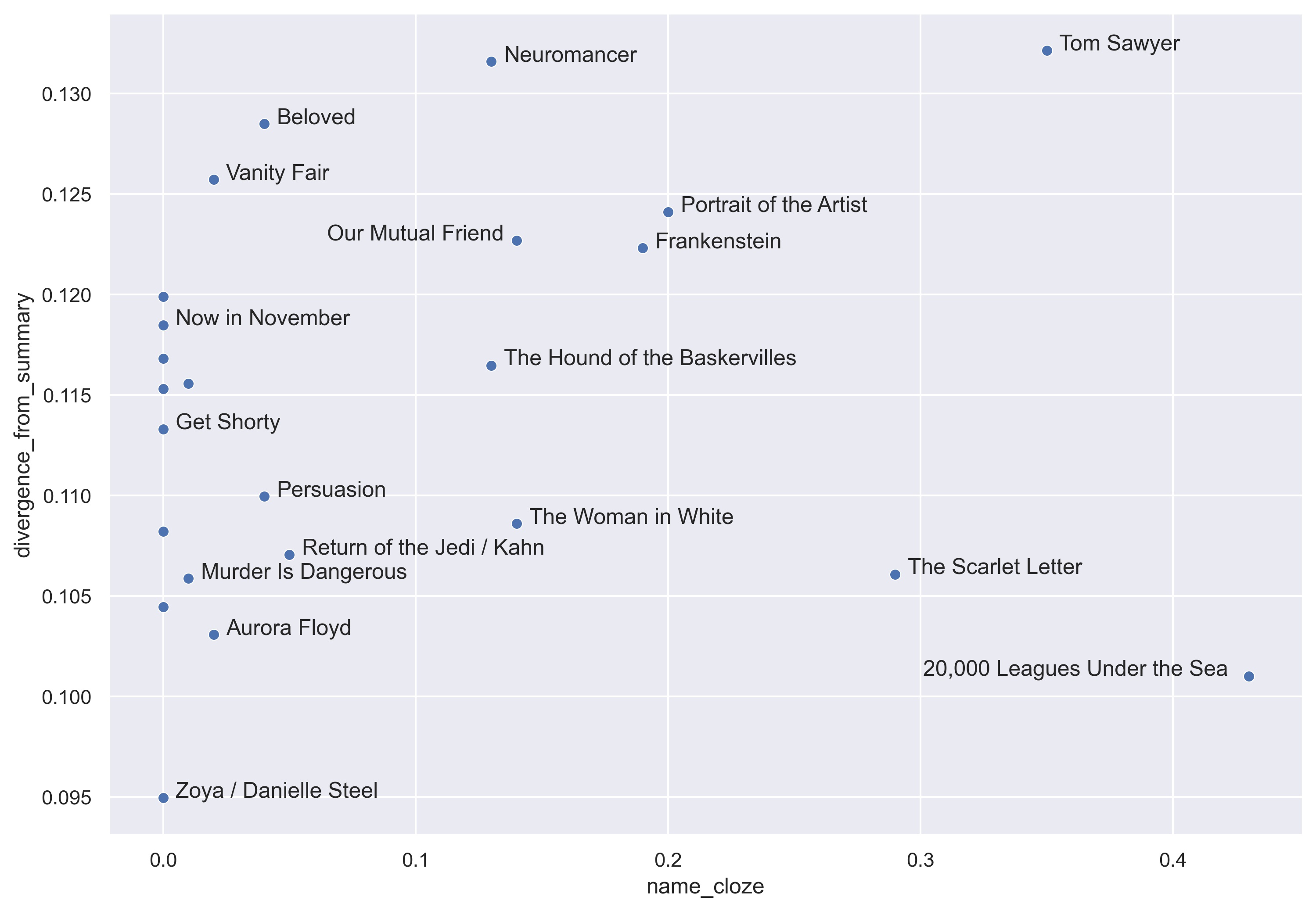
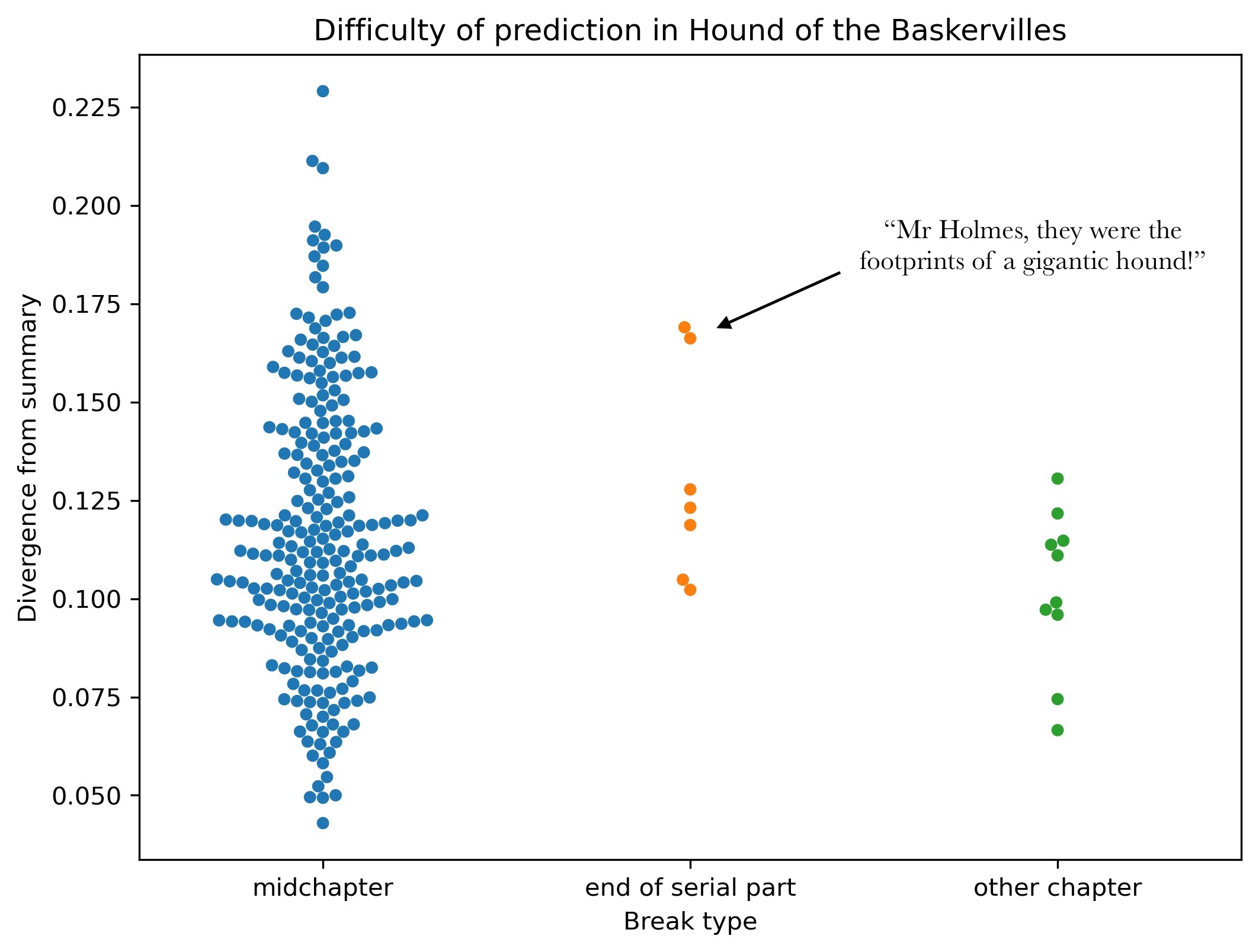
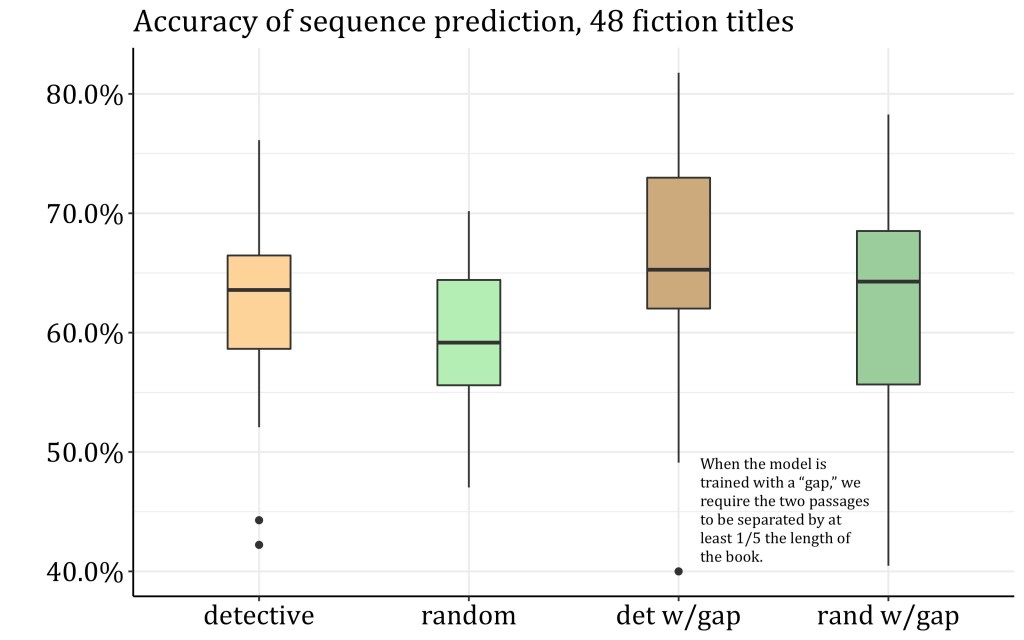
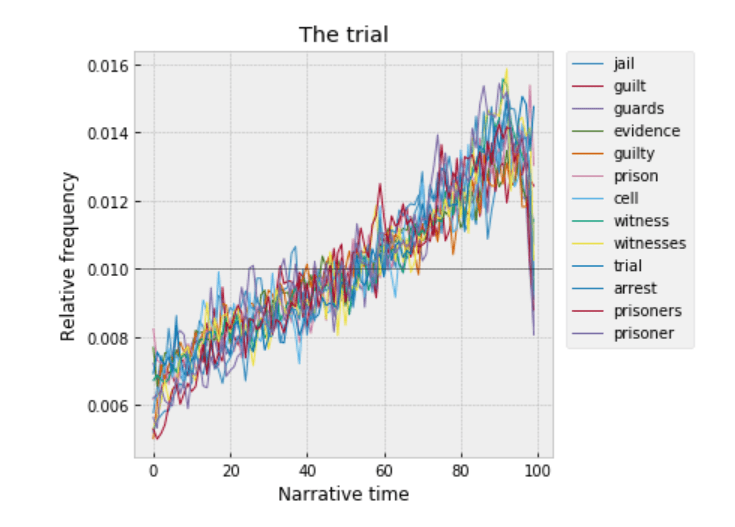
My friends are generally optimistic, forward-looking people, but talking about AI makes many of them depressed. Either AI is scarier than other technologies, or public conversation about it has failed them in some way. Or both.
I think the problem is not just that people have legitimate concerns. What’s weird and depressing about AI discourse right now is the surprising void where we might expect to find a counterbalancing positive vision.
It is not unusual, after all, for new technologies to have a downside. Airplanes were immediately recognized as weapons of war, and we eventually recognized that the CO2 they produce is not great either. But their upside is also vivid: a new and dizzying freedom of motion through three-dimensional space. Is the upside worth the cost? Idk. Saturation bombing has been bad for civilians. But there is at least something in both pans of the scale. It can swing back and forth. So when we think about flight—even if we believe it has been destructive on balance—we can see tension and a possibility of change. We don’t just feel passively depressed.
Is “super-intelligence” the upside for AI?
What people seem to want to put on the “positive” side of the balance for AI is is a 1930s-era dystopia skewered well by Helen De Cruz.

The upside of AI, apparently, is that super-intelligence replaces human agency. This is supposed to have good consequences: accelerating science and so on. But it’s not exactly motivating, because it’s not clear what we get to do in this picture.
Sam Altman’s latest blog post (“The Gentle Singularity”) reassures us by telling us we will always feel there’s something to do. “I hope we will look at the jobs a thousand years in the future and think they are very fake jobs, and I have no doubt they will feel incredibly important and satisfying to the people doing them.”
If this is the upside on offer, I’m not surprised people are bored and depressed. First, it’s an unappealing story, as Ryan Moulton explains:
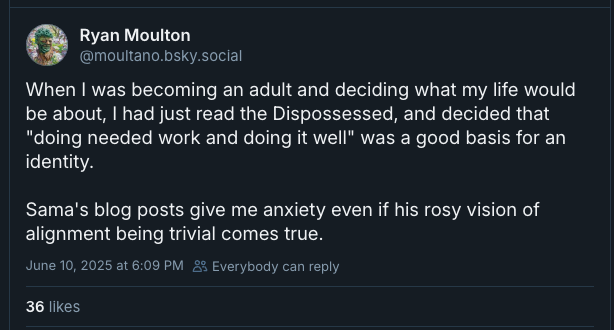
Secondly, as Ryan hints in his last sentence, Altman’s vision of the future isn’t very persuasive. Stories about fully automated societies where superintelligent AI makes the strategic decisions, coordinates the supply chains, &c, quietly assume that we can solve “alignment” not only for models but for human beings. Bipedal primates are expected to naturally converge on a system that allows decisions to be made by whatever agency is smartest or produces best results. Some version of this future has sounded rational and plausible to nerds since Plato. But somehow we nerds consistently fail to make it reality—in spite of our presumably impressive intelligence. If you want a vision of the future of “super-intelligence,” consider the fate of the open web or the NSF.
I’m not just giving a fatalistic shrug about politics and markets here. I think cutting the NSF was a bad idea, but there are good reasons why we keep failing to eliminate human disagreement. It’s a load-bearing part of the system. If you or I tried to automate, say, NSF review panels, our automated system would develop blind spots, and would eventually need external criticism. (For a good explanation of why, see Bryan Wilder’s blog post on automated review.) Conceivably that external criticism could be provided by AI. But if so, the AI would need to be built or controlled by someone else—someone independent of us. If a task is really important, you need legal persons who can’t edit or delete each other arguing over it.
AI as a cultural technology
The irreducible centrality of human conflict is one reason why I doubt that “super-intelligence” is the right frame for thinking about economic and social effects of AI. However smart it gets, a system that lacks independent legal personhood is not a good substitute for a human reviewer or manager. Nor do I think it’s likely that fractious human polities will redefine legal personhood so it can be multiplied by hitting command-C followed by command-V.
A more coherent positive picture of a future with AI has started to emerge. As the title of Ethan Mollick’s Co-Intelligence implies, it tends to involve working with AI assistance, not resigning large sectors of the economy to a super-intelligence. I’ve outlined one reason to expect that path above. Arvind Narayanan and Sayash Kapoor have provided a more sustained argument that AI capability is unlikely to exponentially exceed human capability across a wide range of tasks.
One reason they don’t expect that trajectory is that the recent history of AI has not tended to support assumptions about the power of abstract and perfectly generalizable intelligence. Progress was rapid over the last ten years—but not because we first discovered the protean core of intelligence itself, which then made all merely specific skills possible. Instead, models started with vast, diverse corpora of images and texts, and learned how to imitate them. This approach was frustrating enough to some researchers that they dismissed the new models as mere “parrots,” entities that fraudulently feign intelligence by learning a huge repertoire of specific templates.
A somewhat more positive response to this breakthrough, embraced by Henry Farrell, Alison Gopnik, Cosma Shalizi, and James Evans, has been to characterize AI as a “cultural technology.” Cultural technologies work by transmitting and enacting patterns of behavior. Other examples might include libraries, the printing press, or language itself.
Is this new cultural technology just a false start or a consolation prize in a hypothetical race whose real goal is still the protean core of intelligence? Many AI researchers seem to think so. The term “AGI” is often used. Some researchers, like Yann LeCun, argue that getting to AGI will require a radically different approach. Others suspect that transformer models or diffusion models can do it with sufficient scale.
I don’t know who’s right. But I also don’t care very much. I’m not certain I believe in absolutely general intelligence—and I know that I don’t believe culture is a less valuable substitute for it.
On the contrary. I’m fond of Christopher Manning’s observation that, where sheer intelligence is concerned, human beings are not orders of magnitude different from bonobos. What gave us orders of magnitude greater power to transform this planet, for good or ill, was language. Language vastly magnified our ability to coordinate patterns of collective behavior (culture), and transmit those patterns to our descendants. Writing made cultural patterns even more durable. Now generative language models (and image and sound models) represent another step change in our ability to externalize and manipulate culture.
Why “cultural technology” doesn’t make anyone less depressed
I’ve suggested that a realistic, potentially positive vision of AI has started to coalesce. It involves working with AI as a “normal technology” (Naranayan and Kapoor), one in a long sequence of “cultural technologies” (Gopnik, Farrell, et al) that have extended the collective power of human beings.
So why are my friends still depressed?
Well, if they think the negative consequences of AI will outweigh positive effects, they have every right to be depressed, because no one has proven that’s wrong. It is absolutely still possible that AI will displace people from existing jobs, force retraining, increase concentration of power, and (further) destabilize democracy. I don’t think anyone can prove that the upside of AI outweighs those possible downsides. The cultural and political consequences of technology are hard to predict, and we are not generally able to foresee them at this stage.

But as I hinted at the beginning of this post, I’m not trying to determine whether AI is good or bad on balance. It can be hard to reach consensus about that, even with a technology as mature as internal combustion or flight. And, even with very mature technologies, it tends to be more useful to try to change the balance of effects than to debate whether it’s currently positive.
So the goal of this post is not to weigh costs and benefits, or argue with skeptics. It is purely to sharpen our sense of the potential upside latent in a vision of AI as “cultural technology.” I think one reason that phrase hasn’t cheered anyone up is that it has been perceived as a deflating move, not an inspiring one. The people disposed to be interested in AI mostly got hooked by a rather different story, about protean general intelligences closely analogous to human beings. If you tell AI enthusiasts “no, this is more like writing,” they tend to get as depressed as the skeptics. My goal here is to convince people who use AI that “this is like writing” is potentially exciting—and to specify some of the things we would need to do to make it exciting.
Mapping and editing culture
So what’s great about writing? It is more durable than the spoken word, of course. But just as importantly, writing allows us to take a step back from language, survey it, fine-tune it, and construct complex structures where one text argues with two others, each of which footnotes fifty others. It would be hard to imagine science without the ability writing provides to survey language from above and use it as building material.
Generative AI represents a second step change in our ability to map and edit culture. Now we can manipulate, not only specific texts and images, but the dispositions, tropes, genres, habits of thought, and patterns of interaction that create them. I don’t think we’ve fully grasped yet what this could mean.
I’ll try to sketch one set of possibilities. But I know in advance that I will fail here, just as someone in 1470 would have failed to envision the scariest and most interesting consequences of printing. At least maybe we’ll get to the point of seeing that it’s not mostly “cheaper Bibles.”
Here’s a Bluesky post that used generative AI to map the space of potential visual styles using a “style reference” (sref).
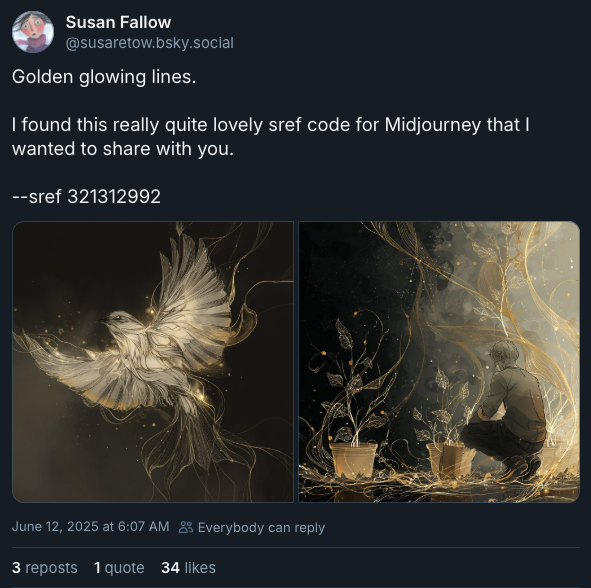
In the early days of text-to-image models, special phrases were passed around like magic words. Adding “Unreal Engine” or “HD” or “by James Gurney” produced specific stylistic effects. But the universe of possible styles is larger than a dictionary of media, artistic schools, or even artists’ names can begin to cover. If we had a way to map that universe, we could explore blank spaces on the map.
Midjourney invented “style references” as simple way to do that. You create a reference by choosing between pairs of images that represent opposing vectors in a stylistic plane. In the process of making those choices, you construct your own high-dimensional vector. Once you have a code for the vector, you can use it as an newly invented adjective, and dial its effect up or down.

“Style references” are modest things, of course. But if we can map a space of possibility for image models, and invent new adjectives to describe directions in that space, we should be able to do the same for language models.
And “style” is not the only thing we could map. In exploring language, it seems likely that we will be mapping different ways of thinking. The experiment called “Golden Gate Claude” was an early, crude demonstration of what this might mean. Anthropic mapped the effect of different neurons in a model, and used that knowledge to tune up one neuron and create a version of Claude deeply obsessed with the Golden Gate Bridge. Given any topic, it would eventually bring the conversation around to fog, or the movie Vertigo — which would remind it, in turn, of San Francisco’s iconic Golden Gate Bridge.
Golden Gate Claude was more of a mental illness than a practical tool. (It reminded me of Vertigo in more than one sense.) But making the model obsessed with a specific landmark was a deliberate simplification for dramatic effect. Anthropic’s map of their model had a lot more nuance available, if it had been needed.

The image above is map of conceptual space based on neurons in a single model. You could think of it as a map of a single mind, or (if you prefer) a single pattern of language use. But models also differ from each other, and there’s no reason why we need to be limited to considering one at a time.
Academics working in this space (both in computer science and in the social sciences) are increasingly interested in using language models to explore cultural pluralism. As we develop models trained on different genres, languages, or historical periods, these models could start to function as reference points in a larger space of cultural possibility that represents the differences between maps like the one above. It ought to be possible to compare different modes of thought, edit them, and create new adjectives (like style references) to describe directions in cultural space.
If we can map cultural space, could we also discover genuinely new cultural forms and new ways of thinking? I don’t know why not. When writing was first invented it was, obviously, a passive echo of speech. “It is like a picture, which can give no answer to a question, and has only a deceitful likeness of a living creature” (Phaedrus).
But externalizing language, and fixing it in written marks, eventually allowed us to construct new genres (the scientific paper, the novel, the index) that required more sustained attention or more mobility of reference than the spoken word could support. Models of culture should similarly allow us to explore a new space of human possibility by stabilizing points of reference within it.
Wait, is editing culture a good idea?
“A new ability to map and explore different modes of reasoning” may initially sound less useful than a super-intelligence that just produces the right answer to our problems. And, look, I’m not suggesting that mapping culture is the only upside of AI. Drug discovery sounds great too! But if you believe human conflict is our most important and durable problem, then a technology that could improve human self-understanding might eventually outweigh a million new drugs.
I don’t mean that language models will eliminate conflict. I said above that conflict is a load-bearing part of society. And language models are likely to be used as ideological weapons—just as pamphlets were, after printing made them possible. But an ideological weapon that can be quizzed and compared to other ideologies implies a level of putting-cards-on-the-table beyond what we often get in practice now. There is at least a chance, as we have seen with Grok, that people who try to lie with an interactive model will end up exposing their own dishonest habits of thought.
So what does this mean concretely? Will maps of cultural space ever be as valuable economically as personal assistants who can answer your email and sound like Scarlett Johansson?
Probably not. Using language models to explore cultural space may not be a great short-term investment opportunity. It’s like — what would be a good analogy? A little piece of amber that, weirdly, attracts silk after rubbing. Or, you know, a little wheel containing water that spins when you heat it and steam comes out the spouts. In short, it is a curiosity that some of us will find intriguing because we don’t yet understand how it works. But if you’re like me, that’s the best upside imaginable for a new technology.
Wait. You’ve suggested that “mapping and editing culture” is a potential upside of AI, allowing us to explore a new space of human potential. But couldn’t this power be misused? What if the builders of Grok don’t “expose their own dishonesty,” but successfully manipulate the broader culture?
Yep, that could happen. I stressed earlier that this post was not going to try to weigh costs against benefits, because I don’t know—and I don’t think anyone knows—how this will play out. My goal here was “purely to sharpen our sense of the potential upside of cultural technology,” and help “specify what we would need to do to make it exciting.” I’m trying to explain a particular challenge and show how the balance could swing back and forth on it. A guarantee that things will, in fact, play out for the best is not something I would pretend to offer.
A future where human beings have the ability to map and edit culture could be very dark. But I don’t think it will be boring or passively depressing. If we think this sounds boring, we’re not thinking hard enough.
References
Altman, S. (2025, June 10). The Gentle Singularity. Retrieved July 2, 2025, from https://blog.samaltman.com/the-gentle-singularity blog.samaltman.com
Anthropic Interpretability Team. (2024, April). Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet. Transformer Circuits Thread. Retrieved July 2, 2025, from https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610–623). Association for Computing Machinery. https://doi.org/10.1145/3442188.3445922 researchgate.net
Farrell, H., Gopnik, A., Shalizi, C., & Evans, J. (2025, March 14). Large AI models are cultural and social technologies. Science, 387(6739), 1153–1156. https://doi.org/10.1126/science.adt9819 pubmed.ncbi.nlm.nih.gov
Manning, C. D. (2022). Human language understanding & reasoning. Daedalus, 151(2), 127–138. https://doi.org/10.1162/daed_a_01905 virtual-routes.org
Mollick, E. (2024). Co-Intelligence: Living and working with AI. Penguin Random House. penguinrandomhouse.com
Narayanan, A., & Kapoor, S. (2025, April 15). AI as normal technology: An alternative to the vision of AI as a potential superintelligence. Knight First Amendment Institute. kfai-documents.s3.amazonaws.com
Sorensen, T., Moore, J., Fisher, J., Gordon, M., Mireshghallah, N., Rytting, C. M., Ye, A., Jiang, L., Lu, X., Dziri, N., Althoff, T., & Choi, Y. (2024). A roadmap to pluralistic alignment. arXiv. https://arxiv.org/abs/2402.05070
Standard Ebooks. (2022). Phaedrus (B. Jowett, Trans.). Retrieved July 2, 2025, from https://standardebooks.org/ebooks/plato/dialogues/benjamin-jowett/text/single-page
Varnum, M. E. W., Baumard, N., Atari, M., & Gray, K. (2024). Large language models based on historical text could offer informative tools for behavioral science. Proceedings of the National Academy of Sciences of the United States of America, 121(42), e2407639121. https://doi.org/10.1073/pnas.2407639121
Wilder, B. (2025). Equilibrium effects of LLM reviewing. Retrieved July 2, 2025, from https://bryanwilder.github.io/files/llmreviews.html bryanwilder.github.io