

How big, exactly, does a collection of literary texts have to be before it makes sense to say we’re doing “distant reading”?
It’s a question people often ask, and a question that distant readers often wriggle out of answering, for good reason. The answer is not determined by the technical limits of any algorithm. It depends, rather, on the size of the blind spots in our knowledge of the literary past — and it’s part of the definition of a blind spot that we don’t already know how big it is. How far do you have to back up before you start seeing patterns that were invisible at your ordinary scale of reading? That’s how big your collection needs to be.
But from watching trends over the last couple of years, I am beginning to get the sense that the threshold for distant reading is turning out to be a bit lower than many people are currently assuming (and lower than I assumed myself in the past). To cut to the chase: it’s probably dozens or scores of books, rather than thousands.
I think there are several reasons why we all got a different impression. One is that Franco Moretti originally advertised distant reading as a continuation of 1990s canon-expansion: the whole point, presumably, was to get beyond the canon and recover a vast “slaughterhouse of literature.” That’s still one part of the project — and it leads to a lot of debate about the difficulty of recovering that slaughterhouse. But sixteen years later, it is becoming clear that new methods also allow us to do a whole lot of things that weren’t envisioned in Moretti’s original manifesto. Even if we restricted our collections to explicitly canonical works, we would still be able to tease out trends that are too long, or family resemblances that are too loose, to be described well in existing histories.
The size of the collection required depends on the question you’re posing. Unsupervised algorithms, like those used for topic modeling, are easy to package as tools: just pour in the books, and out come some topics. But since they’re not designed to answer specific questions, these approaches tend to be most useful for exploratory problems, at large scales of inquiry. (One recent project by Emily Barry, for instance, uses 22,000 Supreme Court cases.)
By contrast, a lot of recent work in distant reading has used supervised models to zero in on narrowly specified historical questions about genre or form. This approach can tell you things you didn’t already know at a smaller scale of inquiry. In “Literary Pattern Recognition,” Hoyt Long and Richard So start by gathering 400 poems in the haiku tradition. In a recent essay on genre I talk about several hundred works of detective fiction, but also ten hardboiled detective novels, and seven Newgate novels.
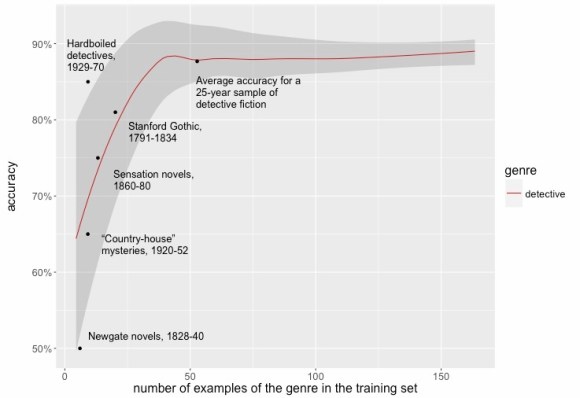
Admittedly, seven is on the low side. I wouldn’t put a lot of faith in any individual dot above. But I do think we can learn something by looking at five subgenres that each contain 7-21 volumes. (In the graph above we learn, for instance, that focused “generational” genres aren’t lexically more coherent than a sample drawn from the whole 160 years of detective fiction — because the longer tradition is remarkably coherent, and pretty easy to recognize, even when you downsample it to ten or twenty volumes.)
I’d like to pitch this reduction of scale as encouraging news. Grad students and assistant professors don’t have to build million-volume collections before they can start exploring new methods. And literary scholars can practice distant reading without feeling they need to buy into any cyclopean ethic of “big data.” (I’m not sure that ethic exists, except as a vaguely-sketched straw man. But if it did exist, you wouldn’t need to buy into it.)
Computational methods themselves won’t even be necessary for all of this work. For some questions, standard social-scientific content analysis (aka reading texts and characterizing them according to an agreed-upon scheme) is a better way to proceed. In fact, if you look back at “The Slaughterhouse of Literature,” that’s what Moretti did with “about twenty” detective stories (212). Shawna Ross recently did something similar, looking at the representation of women’s scholarship at MLA#16 by reading and characterizing 792 tweets.
Humanists still have a lot to learn about social-scientific methods, as Tanya Clement has recently pointed out. (Inter-rater reliability, anyone?) And I think content analysis will run into some limits as we stretch the timelines of our studies: as you try to cover centuries of social change, it gets hard to frame a predefined coding scheme that’s appropriate for everything on the timeline. Computational models have some advantages at that scale, because they can be relatively flexible. Plus, we actually do want to reach beyond the canon.
But my point is simply that “distant reading” doesn’t prescribe a single scale of analysis. There’s a smooth ramp that leads from describing seven books, to characterizing a score or so (still by hand, but in a more systematic way), to statistical reflection on the uncertainty and variation in your evidence, to text mining and computational modeling (which might cover seven books or seven hundred). Proceed only as far as you find useful for a given question.
