People new to text mining are often disillusioned when they figure out how it’s actually done — which is still, in large part, by counting words. They’re willing to believe that computers have developed some clever strategy for finding patterns in language — but think “surely it’s something better than that?”
Uneasiness with mere word-counting remains strong even in researchers familiar with statistical methods, and makes us search restlessly for something better than “words” on which to apply them. Maybe if we stemmed words to make them more like concepts? Or parsed sentences? In my case, this impulse made me spend a lot of time mining two- and three-word phrases. Nothing wrong with any of that. These are all good ideas, but they may not be quite as essential as we imagine.
I suspect the core problem is that most of us learned language a long time ago, and have forgotten how much leverage it provides. We can still recognize that syntax might be worthy of analysis — because it’s elusive enough to be interesting. But the basic phenomenon of the “word” seems embarrassingly crude.
Baby, 1949, from the Galt Museum, on Creative Commons.We need to remember that words are actually features of a very, very high-level kind. As a thought experiment, I find it useful to compare text mining to image processing. Take the picture on the right. It’s pretty hard to teach a computer to recognize that this is a picture that contains a face. To recognize that it contains “sitting” and a “baby” would be extraordinarily impressive. And it’s probably, at present, impossible to figure out that it contains a “blanket.”
Working with text is like working with a video where every element of every frame has already been tagged, not only with nouns but with attributes and actions. If we actually had those tags on an actual video collection, I think we’d recognize it as an enormously valuable archive. The opportunities for statistical analysis are obvious! We have trouble recognizing the same opportunities when they present themselves in text, because we take the strengths of text for granted and only notice what gets lost in the analysis. So we ignore all those free tags on every page and ask ourselves, “How will we know which tags are connected? And how will we know which clauses are subjunctive?”
Natural language processing is going to be important for all kinds of reasons — among them, it can eventually tell us which clauses are subjunctive (should we wish to know). But I think it’s a mistake to imagine that text mining is now in a sort of crude infancy, whose real possibilities will only be revealed after NLP matures. Wordcounts are amazing! An enormous amount of our cultural history is already tagged, in a detailed way that is also easy to analyze statistically. That’s not an embarrassingly babyish method: it’s a huge and obvious research opportunity.
In recent months I’ve had several conversations with colleagues who are friendly to digital methods but wary of claims about novelty that seem overstated. They believe that text mining can add a new level of precision to our accounts of literary history, or add a new twist to an existing debate. They just don’t think it’s plausible that quantification will uncover fundamentally new evidence, or patterns we didn’t previously expect.
If I understand my friends’ skepticism correctly, it’s founded less on a narrow objection to text mining than on a basic premise about the nature of literary study. And where the history of the discipline is concerned, they’re arguably right. In fact, the discipline of literary studies has not usually advanced by uncovering unexpected evidence. As grad students, that’s not what we were taught to aim for. Instead we learned that the discipline moves forward dialectically. You take something that people already believe and “push against” it, or “critique” it, or “complicate” it. You don’t make discoveries in literary study, or if you do they’re likely to be minor — a lost letter from Byron to his tailor. Instead of making discoveries, you make interventions — a telling word.
The broad contours of our discipline are already known, so nothing can grow without displacing something else.
So much flows from this assumption. If we’re not aiming for discovery, if the broad contours of literary history are already known, then methodological conversation can only be a zero-sum game. That’s why, when I say “digital methods don’t have to displace traditional scholarship,” my colleagues nod politely but assume it’s insincere happy talk. They know that in reality, the broad contours of our discipline are already known, and anything within those boundaries can only grow by displacing something else.
These are the assumptions I was also working with until about three years ago. But a couple of years of mucking about in digital archives have convinced me that the broad contours of literary history are not in fact well understood.
For instance, I just taught a course called Introduction to Fiction, and as part of that course I talk about the importance of point of view. You can characterize point of view in a lot of subtle ways, but the initial, basic division is between first-person and third-person perspectives.
Suppose some student had asked the obvious question, “Which point of view is more common? Is fiction mostly written in the first or third person? And how long has it been that way?” Fortunately undergrads don’t ask questions like that, because I couldn’t have answered.
I have a suspicion that first person is now used more often in literary fiction than in novels for a mass market, but if you ask me to defend that — I can’t. If you ask me how long it’s been that way — no clue. I’ve got a Ph.D in this field, but I don’t know the history of a basic formal device. Now, I’m not totally ignorant. I can say what everyone else says: “Jane Austen perfected free indirect discourse. Henry James. Focalizing character. James Joyce. Stream of consciousness. Etc.” And three years ago that might have seemed enough, because the bigger, simpler question was obviously unanswerable and I wouldn’t have bothered to pose it.
But recently I’ve realized that this question is answerable. We’ve got large digital archives, so we could in principle figure out how the proportions of first- and third-person narration have changed over time.
You might reasonably expect me to answer that question now. If so, you underestimate my commitment to the larger thesis here: that we don’t understand literary history. I will eventually share some new evidence about the history of narration. But first I want to stress that I’m not in a position to fully answer the question I’ve posed. For three reasons:
1) Our digital collections are incomplete. I’m working with a collection of about 700,000 18th and 19th-century volumes drawn from HathiTrust.
That’s a lot. But it’s not everything that was written in the English language, or even everything that was published.
2) This is work in progress. For instance, I’ve cleaned and organized the non-serial part of the collection (about 470,000 volumes), but I haven’t started on the periodicals yet. Also, at the moment I’m counting volumes rather than titles, so if a book was often reprinted I count it multiple times. (This could be a feature or a bug depending on your goals.)
3) Most importantly, we can’t answer the question because we don’t fully understand the terms we’re working with. After all, what is “first-person narration?”
The truth is that the first person comes in a lot of different forms. There are cases where the narrator is also the protagonist. That’s pretty straightforward. Then epistolary novels. Then there are cases where the narrator is anonymous — and not a participant in the action — but sometimes refers to herself as I. Even Jane Austen’s narrator sometimes says “I.” Henry Fielding’s narrator does it a lot more. Should we simply say this is third-person narration, or should we count it as a move in the direction of first? Then, what are we going to do about books like Bleak House? Alternating chapters of first and third person. Maybe we call that 50% first person? — or do we assign it to a separate category altogether? What about a novel like Dracula, where journals and letters are interspersed with news clippings?
Suppose we tried to crowdsource this problem. We get a big team together and decide to go through half a million volumes, first of all to identify the ones that are fiction, and secondly, if a volume is fiction, to categorize the point of view. Clearly, it’s going to be hard to come to agreement on categories. We might get halfway through the crowdsourcing process, discover a new category, and have to go back to the drawing board.
Notice that I haven’t mentioned computers at all yet. This is not a problem created by computers, because they “only understand binary logic.” It’s a problem created by us. Distant reading is hard, fundamentally, because human beings don’t agree on a shared set of categories. Franco Moretti has a well-known list of genres, for instance, in Graphs, Maps, Trees. But that list doesn’t represent an achieved consensus. Moretti separates the eighteenth-century gothic novel from the late-nineteenth-century “imperial gothic.” But for other critics, those are two parts of the same genre. For yet other critics, the “gothic” isn’t a genre at all; it’s a mode like tragedy or satire, which is why gothic elements can pervade a bunch of different genres.
This is the darkest moment of this post. It may seem that there’s no hope for literary historians. How can we ever know anything if we can’t even agree on the definitions of basic concepts like genre and point of view? But here’s the crucial twist — and the real center of what I want to say. The blurriness of literary categories is exactly why it’s helpful to use computers for distant reading. With an algorithm, we can classify 500,000 volumes provisionally. Try defining point of view one way, and see what you get. If someone else disagrees, change the definition; you can run the algorithm again overnight. You can’t re-run a crowdsourced cataloguing project on 500,000 volumes overnight.
Second, algorithms make it easier to treat categories as plural and continuous. Although Star Trek teaches us otherwise, computers do not start to stammer and emit smoke if you tell them that an object belongs in two different categories at once. Instead of sorting texts into category A or category B, we can assign degrees of membership to multiple categories. As many as we want. So The Moonstone can be 80% similar to a sensation novel and 50% similar to an imperial gothic, and it’s not a problem. Of course critics are still going to disagree about individual cases. And we don’t have to pretend that these estimates are precise characterizations of The Moonstone. The point is that an algorithm can give us a starting point for discussion, by rapidly mapping a large collection in a consistent but flexibly continuous way.
Then we can ask, Does the gothic often overlap with the sensation novel? What other genres does it overlap with? Even if the boundaries are blurry, and critics disagree about every individual case — even if we don’t have a perfect definition of the term “genre” itself — we’ve now got a map, and we can start talking about the relations between regions of the map.
Can we actually do this? Can we use computers to map things like genre and point of view? Yes, to coin a phrase, we can. The truth is that you can learn a lot about a document just by looking at word frequency. That’s how search engines work, that’s how spam gets filtered out of your e-mail; it’s a well-developed technology. The Stanford Literary Lab suggested a couple of years ago that it would probably work for literary genres as well (see Pamphlet 1), and Matt Jockers has more detailed work forthcoming on genre and diction in Macroanalysis.
There are basically three steps to the process. First, get a training set of a thousand or so examples and tag the categories you want to recognize: poetry or prose, fiction or nonfiction, first- or third-person narration. Then, identify features (usually words) that turn out to provide useful clues about those categories. There are a lot of ways of doing this automatically. Personally, I use a Wilcoxon test to identify words that are consistently common or uncommon in one class relative to others. Finally, train classifiers using those features. I use what’s known as an “ensemble” strategy where you train multiple classifiers and they all contribute to the final result. Each of the classifiers individually uses an algorithm called “naive Bayes,” which I’m not going to explain in detail here; let’s just say that collectively, as a group, they’re a little less “naive” than they are individually — because they’re each relying on slightly different sets of clues.
Confusion matrix from an ensemble of naive Bayes classifiers. (432 test documents held out from a larger sample of 1356.)
How accurate does this end up being? This confusion matrix gives you a sense. Let me underline that this is work in progress. If I were presenting finished results I would need to run this multiple times and give you an average value. But these are typical results. Here I’ve got a corpus of thirteen hundred nineteenth-century volumes. I train a set of classifiers on two-thirds of the corpus, and then test it by using it to classify the other third of the corpus which it hasn’t yet seen. That’s what I mean by saying 432 documents were “held out.” To make the accuracy calculations simple here, I’ve treated these categories as if they were exclusive, but in the long run, we don’t have to do that: documents can belong to more than one at once.
These results are pretty good, but that’s partly because this test corpus didn’t have a lot of miscellaneous collected works in it. In reality you see a lot of volumes that are a mosaic of different genres — the collected poems and plays of so-and-so, prefaced by a prose life of the author, with an index at the back. Obviously if you try to classify that volume as a single unit, it’s going to be a muddle. But I think it’s not going to be hard to use genre classification itself to segment volumes, so that you get the introduction, and the plays, and the lyric poetry sorted out as separate documents. I haven’t done that yet, but it’s the next thing on my agenda.
One complication I have already handled is historical change. Following up a hint from Michael Witmore, I’ve found that it’s useful to train different classifiers for different historical periods. Then when you get an uncategorized document, you can have each classifier make a prediction, and weight those predictions based on the date of the document.
So what have I found? First of all, here’s the absolute number of volumes I was able to identify as fiction in HathiTrust’s collection of eighteenth and nineteenth-century English-language books. Instead of plotting individual years, I’ve plotted five-year segments of the timeline. The increase, of course, is partly just an absolute increase in the number of books published.
But it’s also an increase specifically in fiction. Here I’ve graphed the number of volumes of fiction divided by the total number of volumes in the collection. The proportion of fiction increases in a straightforward linear way. From 1700-1704, when fiction is only about 5% of the collection, to 1895-99, when it’s 25%. People better-versed in book history may already have known that this was a linear trend, but I was a bit surprised. (I should note that I may be slightly underestimating the real numbers before 1750, for reasons explained in the fine print to the earlier graph — basically, it’s hard for the classifier to find examples of a class that is very rare.)
Features consistently more common in first- or third-person narration, ranked by Mann-Whitney-Wilcoxon rho.
What about the question we started with — first-person narration? I approach this the same way I approached genre classification. I trained a classifier on 290 texts that were clearly dominated by first- or third-person narration, and used a Wilcoxon test to select features that are consistently more common in one set or in the other.
Now, it might seem obvious what these features are going to be: obviously, we would expect first-person and third-person pronouns to be the most important signal. But I’m allowing the classifier to include whatever features it in practice finds. For instance, terms for domestic relationships like “daughter” and “husband” and the relative pronouns “whose” and “whom” are also consistently more common in third-person contexts, and oddly, numbers seem more common in first-person contexts. I don’t know why that is yet; this is work in progress and there’s more exploration to do. But for right now I haven’t second-guessed the classifier; I’ve used the top sixteen features in both lists whether they “make sense” or not.
And this is what I get. The classifier predicts each volume’s probability of belonging to the class “first person.” That can be anywhere between 0 and 1, and it’s often in the middle (Bleak House, for instance, is 0.54). I’ve averaged those values for each five-year interval. I’ve also dropped the first twenty years of the eighteenth century, because the sample size was so low there that I’m not confident it’s meaningful.
Now, there’s a lot more variation in the eighteenth century than in the nineteenth century, partly because the sample size is smaller. But even with that variation it’s clear that there’s significantly more first-person narration in the eighteenth century. About half of eighteenth-century fiction is first-person, and in the nineteenth century that drops down to about a quarter. That’s not something I anticipated. I expected that there might be a gradual decline in the amount of first-person narration, but I didn’t expect this clear and relatively sudden moment of transition. Obviously when you see something you don’t expect, the first question you ask is, could something be wrong with the data? But I can’t see a source of error here. I’ve cleaned up most of the predictable OCR errors in the corpus, and there aren’t more medial s’s in one list than in the other anyway.
And perhaps this picture is after all consistent with our expectations. Eleanor Courtemanche points out that the timing of the shift to third person is consistent with Ian Watt’s account of the development of omniscience (as exemplified, for instance, in Austen). In a quick twitter poll I carried out before announcing the result, Jonathan Hope did predict that there would be a shift from first-person to third-person dominance, though he expected it to be more gradual. Amanda French may have gotten the story up to 1810 exactly right, although she expected first-person to recover in the nineteenth century. I expected a gradual decline of first-person to around 1810, and then a gradual recovery — so I seem to have been completely wrong.
The ratio between raw counts of first- and third-person pronouns in fiction.
Much more could be said about this result. You could decide that I’m wrong to let my classifier use things like numbers and relative pronouns as clues about point of view; we could restrict it just to counting personal pronouns. (That won’t change the result very significantly, as you can see in the illustration on the right — which also, incidentally, shows what happens in those first twenty years of the eighteenth century.) But we could refine the method in many other ways. We could exclude pronouns in direct discourse. We could break out epistolary narratives as a separate category.
All of these things should be tried. I’m explicitly not claiming to have solved this problem yet. Remember, the thesis of this talk is that we don’t understand literary history. In fact, I think the point of posing these questions on a large scale is partly to discover how slippery they are. I realize that to many people that will seem like a reason not to project literary categories onto a macroscopic scale. It’s going to be a mess, so — just don’t go there. But I think the mess is the reason to go there. The point is not that computers are going to give us perfect knowledge, but that we’ll discover how much we don’t know.
For instance, I haven’t figured out yet why numbers are common in first-person narrative, but I suspect it might be because there’s a persistent affinity with travel literature. As we follow up leads like that we may discover that we don’t understand point of view itself as well as we assume.
It’s this kind of complexity that will ultimately make classification interesting. It’s not just about sorting things into categories, but about identifying the places where a category breaks down or has changed over time. I would draw an analogy here to a paper on “Gender in Twitter” recently published by a group of linguists. They used machine learning to show that there are not two but many styles of gender performance on Twitter. I think we’ll discover something similar as we explore categories like point of view and genre. We may start out trying to recognize known categories, like first-person narration. But when you sort a large collection into categories, the collection eventually pushes back on your categories as much as the categories illuminate the collection.
Acknowledgments: This research was supported by the Andrew W. Mellon Foundation through “Expanding SEASR Services” and “The Uses of Scale in Literary Study.” Loretta Auvil, Mike Black, and Boris Capitanu helped develop resources for normalizing 18/19c OCR, many of which are public at usesofscale.com. Jordan Sellers developed the initial training corpus of 19c documents categorized by genre.
Academics have been discussing a crisis “in” or “of” the humanities since the late 1980s. Scholars disagree about the nature of the crisis, but it’s a widely shared premise that one is located somewhere “in the humanities.”
The phrase “digital humanities” invites a connection to this debate. If DH is about the humanities, and “grounded in humanistic values” (Spiro 23), then it stands to reason that it ought to somehow respond to any crisis that threatens “the humanities.” This is the premise that fuels Alan Liu’s well-known argument about DH and cultural criticism. “[T]he digital humanities community,” he argues, has a “special potential and responsibility to assist humanities advocacy.”
I think these assumptions need to be brought into conversation with Geoffrey Harpham’s recent, important book The Humanities and the Dream of America (h/t @noeljackson). Harpham’s central point is simple: our concept of “the humanities” emerged quite recently. Although the individual disciplines grouped under that umbrella are older, the umbrella itself is largely a twentieth-century invention — and only became institutionally central after WWII.
Since the beginning of the twentieth century, when administrators at Columbia, Chicago, Yale, and Harvard began to speak fervently of the moral and spiritual benefits of a university education, “the humanities” has served as the name and the form of the link Arnold envisioned between culture, education, and the state. Particularly after World War II, the humanities began to be opposed not just to its traditional foil, science, but also to social science, whose emergence as a powerful force in the American academy was marked by the founding of the Center for Advanced Study in the Behavioral Sciences at Stanford in 1951 (87).
In research for a forthcoming book (Why Literary Periods Mattered, Stanford UP) I’ve poked around a bit in the institutional history of the early-twentieth-century university, and Harpham’s thesis rings true to me. Although the word has a pre-twentieth-century history, our present understanding of “the humanities” is strongly shaped by an institutional opposition between humanities and social sciences that only made sense in the twentieth century. For whatever it’s worth, Google Books also tends to support Harpham’s contention that the concept of the humanities has only possessed its present prominence since WWII.
Defenses of “culture,” of course, are older. But it hasn’t always been clear that culture was coextensive with the disciplines now grouped together as humanistic. In the middle of the twentieth century, literary critics like René Wellek fervently defended literary culture from philistine encroachment by the discipline of history. The notion that literary scholars and historians must declare common cause against a besieging world of philistines is a very different script, and one that really only emerged in the last thirty years.
Why do I say all this? Am I trying to divide literary scholars from historians? Don’t I see that we have to hang together, or hang separately?
I understand that higher education, as a whole, is under attack from the right. So I’m happy to declare common cause with people who are working to articulate the value of literary studies and history — or for that matter, anthropology and library science. But I don’t think it’s quite inevitable that these battles should be fought under the flag of the humanities.
Or one could argue that we’d be better off fighting for specific concepts like “literature” and “history” and “art.” People outside the university know what those are. It’s not clear that they have a vivid concept of the humanities. It’s a term of recent and mostly academic provenance.
On the other hand, there may be good reason to mobilize around “the humanities.” Certainly the NEH itself is worth defending. Ultimately, this is a question of political strategy, and I don’t have strong opinions about it. I’m very happy to see people defending individual disciplines, or the humanities, or higher education as a whole. In my eyes, it’s all good.
But I do want to push back gently against the notion that scholars in any discipline have a political obligation to organize under the banner of “the humanities,” or an intellectual obligation to define “humanistic” methods. The concept of the humanities may well be a recent invention, shaped by twentieth-century struggles over institutional turf. We talk about “humanistic values” as if they were immemorial. But Erasmus did not share our sense that history and literature have to band together in order to resist encroachment by sociology.
More pointedly: cultural criticism and humanities advocacy are fundamentally different things. There have been many kinds of critical, politically engaged intellectuals; only in the last sixty years have some of them self-identified as humanists.
What does all this mean for the digital humanities? I don’t know. Since “the humanities” are built right into the phrase, perhaps it should belong to people who identify as humanists. But much of the work that interests me personally is now taking place in departments of Library and Information Science, which inherit a social science tradition (as Kari Kraus has recently pointed out). So I would also be happy with a phrase like “digital humanities and social sciences.” Dan Cohen recently used that phrase as a course title, and it’s an interesting move.
Added a few hours after posting: To show a few more of my own cards, I’ll confess that what I love most about DH is the freedom to ignore disciplinary boundaries and follow shared problems wherever they lead. But I’m beginning to suspect that the concept of the humanities may itself discourage interdisciplinary risks. It seems to have been invented (rather recently) to define certain disciplines through their collective difference from the social and natural sciences. If that’s true, “digital humanities” may be an awkward concept for me. I’m a literary historian, and I do feel loyalty to the methods of that discipline. But I don’t feel loyalty to them specifically as different from the sciences.
Added a day after initial posting: And, to be clear, I don’t mean that we need a better name than “digital humanities.” There’s a basic tension between interdisciplinarity and field definition — so any name can become constricting if you spend too much time defining it. For me the bottom line is this: I like the interdisciplinary energy that I’ve found in the DH blogosphere and don’t care what we call it — don’t care, in a radical way — to the extent that I don’t even care whether critics think DH is consonant with, quote, “humanistic values.” Because in truth, some of those values are recent inventions, shaped by pressure to differentiate the humanities from the social sciences — and that move deserves to be questioned every bit as much as DH itself does. /done now
References
Harpham, Geoffrey Galt. The Humanities and the Dream of America. Chicago: University of Chicago Press, 2011. (I should note that I may not agree with all aspects of Harpham’s argument. In particular, I’m not yet persuaded that the concept of ‘the humanities’ is as fully identified with the United States in particular as he argues.)
Liu, Alan. “Where is Cultural Criticism in the Digital Humanities.” Debates in the Digital Humanities. Ed. Matthew K. Gold. (Minnesota: University of Minnesota Press, 2012). 490-509.
Spiro, Lisa. “‘This is Why We Fight’: Defining the Values of the Digital Humanities.” Debates in the Digital Humanities. Ed. Matthew K. Gold. (Minnesota: University of Minnesota Press, 2012). 16-35.
Of all our literary-historical narratives it is the history of criticism itself that seems most wedded to a stodgy history-of-ideas approach—narrating change through a succession of stars or contending schools. While scholars like John Guillory and Gerald Graff have produced subtler models of disciplinary history, we could still do more to complicate the narratives that organize our discipline’s understanding of itself.
A browsable network based on Underwood's model of PMLA. Click through, then mouse over or click on individual topics.The archive of scholarship is also, unlike many twentieth-century archives, digitized and available for “distant reading.” Much of what we need is available through JSTOR’s Data for Research API. So last summer it occurred to a group of us that topic modeling PMLA might provide a new perspective on the history of literary studies. Although Goldstone and Underwood are writing this post, the impetus for the project also came from Natalia Cecire, Brian Croxall, and Roger Whitson, who may do deeper dives into specific aspects of this archive in the near future.
Topic modeling is a technique that automatically identifies groups of words that tend to occur together in a large collection of documents. It was developed about a decade ago by David Blei among others. Underwood has a blog post explaining topic modeling, and you can find a practical introduction to the technique at the Programming Historian. Jonathan Goodwin has explained how it can be applied to the word-frequency data you get from JSTOR.
Obviously, PMLA is not an adequate synecdoche for literary studies. But, as a generalist journal with a long history, it makes a useful test case to assess the value of topic modeling for a history of the discipline.
Goldstone and Underwood each independently produced several different models of PMLA, using different software, stopword lists, and numbers of topics. Our results overlapped in places and diverged in places. But we’ve reached a shared sense that topic modeling can enrich the history of literary scholarship by revealing trends that are presently invisible.
What is a topic?
A “topic model” assigns every word in every document to one of a given number of topics. Every document is modeled as a mixture of topics in different proportions. A topic, in turn, is a distribution of words—a model of how likely given words are to co-occur in a document. The algorithm (called LDA) knows nothing “meta” about the articles (when they were published, say), and it knows nothing about the order of words in a given document.
This is a picture of 5940 articles from PMLA, showing the changing presence of each of 100 "topics" in PMLA over time. (Click through to enlarge; a longer list of topic keywords is here.) For example, the most probable words in the topic arbitrarily numbered 59 in the model visualized above are, in descending order:
che gli piu nel lo suo sua sono io delle perche questo quando ogni mio quella loro cosi dei
This is not a “topic” in the sense of a theme or a rhetorical convention. What these words have in common is simply that they’re basic Italian words, which appear together whenever an extended Italian text occurs. And this is the point: a “topic” is neither more nor less than a pattern of co-occurring words.
Nonetheless, a topic like topic 59 does tell us about the history of PMLA. The articles where this topic achieved its highest proportion were:
Antonio Illiano, “Momenti e problemi di critica pirandelliana: L’umorismo, Pirandello e Croce, Pirandello e Tilgher,” PMLA 83 no. 1 (1968): pp. 135-143
Domenico Vittorini, “I Dialogi ad Petrum Histrum di Leonardo Bruni Aretino (Per la Storia del Gusto Nell’Italia del Secolo XV),” PMLA 55 no. 3 (1940): pp. 714-720
Vincent Luciani, “Il Guicciardini E La Spagna,” PMLA 56 no. 4 (1941): pp. 992-1006
And here’s a plot of the changing proportions of this topic over time, showing moving 1-year and 5-year averages:
We see something about PMLA that is worth remembering for the history of criticism, namely, that it has embedded Italian less and less frequently in its language since midcentury. (The model shows that the same thing is true of French and German.)
What can topics tell us about the history of theory?
Of course a topic can also be a subject category—modeling PMLA, we have found topics that are primarily “about Beowulf” or “about music.” Or a topic can be a group of words that tend to co-occur because they’re associated with a particular critical approach.
Here, for instance, we have a topic from Underwood’s 150-topic model associated with discussions of pattern and structure in literature. We can characterize it by listing words that occur more commonly in the topic than elsewhere, or by graphing the frequency of the topic over time, or by listing a few articles where it’s especially salient.
At first glance this topic might seem to fit neatly into a familiar story about critical history. We know that there was a mid-twentieth-century critical movement called “structuralism,” and the prominence of “structure” here might suggest that we’re looking at the rise and fall of that movement. In part, perhaps, we are. But the articles where this topic is most prominent are not specifically “structuralist.” In the top four articles, Ferdinand de Saussure, Claude Lévi-Strauss, and Northrop Frye are nowhere in evidence. Instead these articles appeal to general notions of symmetry, or connect literary patterns to Neoplatonism and Renaissance numerology.
By forcing us to attend to concrete linguistic practice, topic modeling gives us a chance to bracket our received assumptions about the connections between concepts. While there is a distinct mid-century vogue for structure, it does not seem strongly associated with the concepts that are supposed to have motivated it (myth, kinship, language, archetype). And it begins in the 1940s, a decade or more before “structuralism” is supposed to have become widespread in literary studies. We might be tempted to characterize the earlier part of this trend as “New Critical interest in formal unity” and the latter part of it as “structuralism.” But the dividing line between those rationales for emphasizing pattern is not evident in critical vocabulary (at least not at this scale of analysis).
This evidence doesn’t necessarily disprove theses about the history of structuralism. Topic modeling might not reveal varying “rationales” for using a word even if those rationales did vary. The strictly linguistic character of this technique is a limitation as well as a strength: it’s not designed to reveal motivation or conflict. But since our histories of criticism are already very intellectual and agonistic, foregrounding the conscious beliefs of contending critical “schools,” topic modeling may offer a useful corrective. This technique can reveal shifts of emphasis that are more gradual and less conscious than the ones we tend to celebrate.
It may even reveal shifts of emphasis of which we were entirely unaware. “Structure” is a familiar critical theme, but what are we to make of this?
A fuller list of terms included in this topic would include “character”, “fact,” “choice,” “effect,” and “conflict.” Reading some of the articles where the topic is prominent, it appears that in this topic “point” is rarely the sort of point one makes in an argument. Instead it’s a moment in a literary work (e.g., “at the point where the rain occurs,” in Robert apRoberts 379). Apparently, critics in the 1960s developed a habit of describing literature in terms of problems, questions, and significant moments of action or choice; the habit intensified through the early 1980s and then declined. This habit may not have a name; it may not line up neatly with any recognizable school of thought. But it’s a fact about critical history worth knowing.
Note that this concern with problem-situations is embodied in common words like “way” and “cannot” as well as more legible, abstract terms. Since common words are often difficult to interpret, it can be tempting to exclude them from the modeling process. It’s true that a word like “the” isn’t likely to reveal much. But subtle, interesting rhetorical habits can be encoded in common words. (E.g. “itself” is especially common in late-20c theoretical topics.)
We don’t imagine that this brief blog post has significantly contributed to the history of criticism. But we do want to suggest that topic modeling could be a useful resource for that project. It has the potential to reveal shifts in critical vocabulary that aren’t well described, and that don’t fit our received assumptions about the history of the discipline.
Why browse topics as a network?
The fact that a word is prominent in topic A doesn’t prevent it from also being prominent in topic B. So certain generalizations we might make about an individual topic (for instance, that Italian words decline in frequency after midcentury) will be true only if there’s not some other “Italian” topic out there, picking up where the first one left off.
For that reason, interpreters really need to survey a topic model as a whole, instead of considering single topics in isolation. But how can you browse a whole topic model? We’ve chosen relatively small numbers of topics, but it would not be unreasonable to divide literary scholarship into, say, 500 topics. Information overload becomes a problem.
A browsable image map of 150 topics from PMLA. After you click through you can mouseover (or click) individual topics for more information.We’ve found network graphs useful here. Click on the image of the network on the right to browse Underwood’s 150-topic model. The size of each node (roughly) indicates the number of words in the topic; color indicates the average date of words. (Blue topics are older; yellow topics are more recent.) Topics are linked to each other if they tend to appear in the same articles. Topics have been labeled with their most salient word—unless that word was already taken for another topic, or seemed misleading. Mousing over a topic reveals a list of words associated with it; with most topics it’s also possible to click through for more information.
The structure of the network makes a loose kind of sense. Topics in French and German form separate networks floating free of the main English structure. Recent topics tend to cluster at the bottom of the page. And at the bottom, historical and pedagogical topics tend to be on the left, while formal, phenomenological, and aesthetic categories tend to be on the right.
But while it’s a little eerie to see patterns like this emerge automatically, we don’t advise readers to take the network structure too seriously. A topic model isn’t a network, and mapping one onto a network can be misleading. For instance, topics that are physically distant from each other in this visualization are not necessarily unrelated. Connections below a certain threshold go unrepresented.
Goldstone’s 100-topic model of PMLA; click through to enlarge.Moreover, as you can see by comparing illustrations in this post, a little fiddling with dials can turn the same data into networks with rather different shapes. It’s probably best to view network visualization as a convenience. It may help readers browse a model by loosely organizing topics—but there can be other equally valid ways to organize the same material.
How did our models differ?
The two models we’ve examined so far in this post differ in several ways at once. They’re based on different spans of PMLA‘s print run (1890–1999 and 1924–2006). They were produced with different software. Perhaps most importantly, we chose different numbers of topics (100 and 150).
But the models we’re presenting are only samples. Goldstone and Underwood each produced several models of PMLA, changing one variable at a time, and we have made some closer apples-to-apples comparisons.
Broadly, the conclusion we’ve reached is that there’s both a great deal of fluidity and a great deal of consistency in this process. The algorithm has to estimate parameters that are impossible to calculate exactly. So the results you get will be slightly different every time. If you run the algorithm on the same corpus with the same number of topics, the changes tend to be fairly minor. But if you change the number of topics, you can get results that look substantially different.
On the other hand, to say that two models “look substantially different” isn’t to say that they’re incompatible. A jigsaw puzzle cut into 100 pieces looks different from one with 150 pieces. If you examine them piece by piece, no two pieces are the same—but once you put them together you’re looking at the same picture. In practice, there was a lot of overlap between our models; on the older end of the spectrum you often see a topic like “evidence fact,” while the newer end includes topics that foreground narrative, rhetoric, and gender. Some of the more surprising details turned out to be consistent as well. For instance, you might expect the topic “literary literature” to skew toward the older end of the print run. But in fact this is a relatively recent topic in both of our models, associated with discussion of canonicity. (Perhaps the owl of Minerva flies only at dusk?)
Contrasting models: a short example
While some topics look roughly the same in all of our models, it’s not always possible to identify close correlates of that sort. As you vary the overall number of topics, some topics seem to simply disappear. Where do they go? For example, there is no exact counterpart in Goldstone’s model to that “structure” topic in Underwood’s model. Does that mean it is a figment? Underwood isolated the following article as the most prominent exemplar:
Robert E. Burkhart, The Structure of Wuthering Heights, Letter to the Editor, PMLA 87 no. 1 (1972): 104–5. (Incidentally, jstor has miscategorized this as a “full-length article.”)
Goldstone’s model puts more than half of Burkhart’s comment in three topics:
0.24 topic 38 time experience reality work sense form present point world human process structure concept individual reader meaning order real relationship
0.13 topic 46 novels fiction poe gothic cooper characters richardson romance narrator story novelist reader plot novelists character reade hero heroine drf
0.12 topic 13 point reader question interpretation meaning make reading view sense argument words word problem makes evidence read clear text readers
The other prominent documents in Underwood’s 109 are connected to similar topics in Goldstone’s model. The keywords for Goldstone’s topic 38, the top topic here, immediately suggest an affinity with Underwood’s topic 109. Now compare the time course of Goldstone’s 38 with Underwood’s 109 (the latter is above):
It is reasonable to infer that some portion of the words in Underwood’s “structure” topic are absorbed in Goldstone’s “time experience” topic. But “time experience reality work sense” looks less like vocabulary for describing form (although “form” and “structure” are included in it, further down the list; cf. the top words for all 100 topics), and more like vocabulary for talking about experience in generalized ways—as is also suggested by the titles of some articles in which that topic is substantially present:
“The Vanishing Subject: Empirical Psychology and the Modern Novel”
“Metacommentary”
“Toward a Modern Humanism”
“Wordsworth’s Inscrutable Workmanship and the Emblems of Reality”
This version of the topic is no less “right” or “wrong” than the one in Underwood’s model. They both reveal the same underlying evidence of word use, segmented in different but overlapping ways. Instead of focusing our vision on affinities between “form” and “structure”, Goldstone’s 100-topic model shows a broader connection between the critical vocabulary of form and structure and the keywords of “humanistic” reflection on experience.
The most striking contrast to these postwar themes is provided by a topic which dominates in the prewar period, then gives way before “time experience” takes hold. Here are box plots by ten-year intervals of the proportions of another topic, Goldstone’s topic 40, in PMLA articles:
Underwood’s model shows a similar cluster of topics centering on questions of evidence and textual documentation, which similarly decrease in frequency. The language of PMLA has shown a consistently declining interest in “evidence found fact” in the era of the postwar research university.
So any given topic model of a corpus is not definitive. Each variation in the modeling parameters can produce a new model. But although topic models vary, models of the same corpus remain fundamentally consistent with each other.
Using LDA as evidence
It’s true that a “topic model” is simply a model of how often words occur together in a corpus. But information of that kind has a deeper significance than we might at first assume. A topic model doesn’t just show you what people are writing about (a list of “topics” in our ordinary sense of the word). It can also show you how they’re writing. And that “how” seems to us a strong clue to social affinities—perhaps especially for scholars, who often identify with a methodology or critical vocabulary. To put this another way, topic modeling can identify discourses as well as subject categories and embedded languages. Naturally we also need other kinds of evidence to produce a history of the discipline, including social and institutional evidence that may not be fully manifest in discourse. But the evidence of topic modeling should be taken seriously.
As you change the number of topics (and other parameters), models provide different pictures of the same underlying collection. But this doesn’t mean that topic modeling is an indeterminate process, unreliable as evidence. All of those pictures will be valid. They are taken (so to speak) at different distances, and with different levels of granularity. But they’re all pictures of the same evidence and are by definition compatible. Different models may support different interpretations of the evidence, but not interpretations that absolutely conflict. Instead the multiplicity of models presents us with a familiar choice between “lumping” or “splitting” cultural phenomena—a choice where we have long known that multiple levels of analysis can coexist. This multiplicity of perspective should be understood as a strength rather than a limitation of the technique; it is part of the reason why an analysis using topic modeling can afford a richly detailed picture of an archive like PMLA.
Appendix: How did we actually do this?
The PMLA data obtained from JSTOR was independently processed by Goldstone and Underwood for their different LDA tools. This created some quantitative subtleties that we’ve saved for this appendix to keep this post accessible to a broad audience. If you read closely, you’ll notice that we sometimes talk about the “probability” of a term in a topic, and sometimes about its “salience.” Goldstone used MALLET for topic modeling, whereas Underwood used his own Java implementation of LDA. As a result, we also used slightly different formulas for ranking words within a topic. MALLET reports the raw probability of terms in each topic, whereas Underwood’s code uses a slightly more complex formula for term salience drawn from Blei & Lafferty (2009). In practice, this did not make a huge difference.
MALLET also has a “hyperparameter optimization” option which Goldstone’s 100-topic model above made use of. Before you run screaming, “hyperparameters” are just dials that control how much fuzziness is allowed in a topic’s distribution across words (beta) or across documents (alpha). Allowing alpha to vary allows greater differentiation between the sizes of large topics (often with common words), and smaller (often more specialized) topics. (See “Why Priors Matter,” Wallach, Mimno, and McCallum, 2009.) In any event, Goldstone’s 100-topic model used hyperparameter optimization; Underwood’s 150-topic model did not. A comparison with several other models suggests that the difference between symmetric and asymmetric (optimized) alpha parameters explains much of the difference between their structures when visualized as networks.
Goldstone’s processing scripts are online in a github repository. The same repository includes R code for making the plots from Goldstone’s model. Goldstone would also like to thank Bob Gerdes of Rutgers’s Office of Instructional and Research Technology for support for running mallet on the university’s apps.rutgers.edu server, Ben Schmidt for helpful comments at a THATCamp Theory session, and Jon Goodwin for discussion and his excellent blog posts on topic-modeling jstor data.
Force-directed graphs are tricky. At their best, the perspective they offer can be very helpful; data points cluster into formations that feel intuitive and look approachable. At their worst, though, they can be too cluttered, and the algorithms that make everything fall into place can deceive as much as they clarify.
But there’s still a good chance that, despite the problems that come along with making a network model of anything (and the problems introduced by making network models of texts), they can still be helpful for interpreting topic models. Visualizations aren’t exactly analysis, so what I share below is meant to raise more questions than answers. We also tried to represent as many aspects of the data as possible without breaking (or breaking only a little) the readability of the visualizations. There were some very unsuccessful tries before we arrived at what is below.
A Few Remarks on Method
As part of our work together, Ted has run some topic models on his 19th century literature dataset and computed the correlation of each topic to other topics. We decided to try this out to see topic distribution among genres, and to get a feel for how topics clustered with one another. Which documents belong to what topic aren’t important for now, although in time I’d like to have the nodes link to the text of the documents. Ted has also calculated the predominant genre to which each topic belongs. And, after building a network model where topic correlation equals edge value, I’ve run the Girvan-Newman algorithm to assess how the topics would cluster by their associations with other topics (I like this approach to grouping better than others for examinations of overall graph structure like this one, as we’re not as interested in individual cliques or clusters). What we get then, is two different ways to categorize the topic: on the one hand we have the genre the topic appears in most (with the genres being assigned to individual documents by a human expert), and on the other we see groupings based on co-occurence with other topics.
The visualizations shown here are all built using d3.js, the excellent open source javascript library created by Mike Bostock. Each of the graphs are force-directed: all nodes possess a negative charge and repel from one another. All links bond to these nodes and hold them together. Many force-directed models set their links to behave like springs and contract to the shortest possible distance between nodes, but these graphs below don’t exactly use Hooke’s law to calculate bond length. Instead, they aim for a specific bond length (in this case, 20 pixels) and draw a link as close as possible to that length given the charges acting on it.
I wanted physical proximity of nodes to one another to means something, so the graphs below have variable bond strengths, which means that depending on the value of the bond (which in these graphs is a function of the correlation of a topic with the topic to which it is linked), it will resist or cooperate with being “stretched” (or really, drawn at a longer distance as other stronger bonds take precedence in being drawn closer to the ideal length of 20px). This has implications for how to interpret distance between nodes in these images. The X and Y axes have no set value, so distance does not equal correlation. This is more of a Newtonian than Euclidean space, which means that a short link can indicate a strong bond between nodes, but strong bonds can also be stretched by opposing forces (like other bonds) exerted on nodes at either end of the bond. So distance between nodes can be significant, but only once considered in context of the whole model and its constitutive metaphor of a physical system. Click on the image below for a sample of what we’re talking about:
D3 allows this is to be an interactive visual, and mousing over an individual node will reveal the first ten words of the topic it represents. Also, clicking on a node allows for pulling and rearranging the graph. Doing this a few times helps reinforce the idea that distance between nodes is the result of a set of simulated physical properties. The colors assigned to the Newman groups are arbitrary, but there’s a key on the left to help distinguish among similar colors.
Comparing Two Graphs
Network graphs are more useful when you can compare them to other network graphs. We split the dataset into two halves, and Ted generated 100 topics for each half of the century. We used slightly different genre labels, but we calculated Newman groups again to produce the two graphs below (again, click through to interact with the graph):
Like the first graph, Newman color assignments are arbitrary; what’s purple in the first 50 years of topics has nothing to do with what’s purple in the next 50 years of topics. I’ve modified these graphs in two key ways to help with reading them. Firstly, bond thickness now variable, and it is a function of bond strength (bond strength derived from correlation). This helps assess if a bond is longer because it’s being stretched or because it’s weak, or both. Secondly, I’ve added node “halos” to emphasize the degree to which the nodes cluster, as well as highlight the Newman groups.
Here’s an alternative graph that colors the nodes by genre instead of Newman group, leaving only the halo to represent group affiliation:
I won’t pretend that any of these are easy to read immediately, but one of our experiments in this was to try to represent as many dimensions as possible to create an exploratory framework for a topic model. Halo and node diameter are set, but the two elements on the visualization are independent and could represent topic size, degree of genre predominance in a topic, etc.
My hope is that these visualizations can be insightful and might help us work through the benefits and disadvantages of force-directed layouts for visualizing topic models.
As for interpretation and analysis, here is the part where I punt to domain experts in 19th century literature and history…
I’ve been collaborating with Michael Simeone of I-CHASS on strategies for visualizing topic models. Michael is using d3.js to build interactive visualizations that are much nicer than what I show below, but since this problem is probably too big for one blog post I thought I might give a quick preview.
Basically the problem is this: How do you visualize a whole topic model? It’s easy to pull out a single topic and visualize it — as a word cloud, or as a frequency distribution over time. But it’s also risky to focus on a single topic, because in LDA, the boundaries between topics are ontologically sketchy.
After all, LDA will create as many topics as you ask it to. If you reduce that number, topics that were separate have to fuse; if you increase it, topics have to undergo fission. So it can be misleading to make a fuss about the fact that two discourses are or aren’t “included in the same topic.” (Ben Schmidt has blogged a nice example showing where this goes astray.) Instead we need to ask whether discourses are relatively near each other in the larger model.
But visualizing the larger model is tricky. The go-to strategy for something like this in digital humanities is usually a network graph. I have some questions about that strategy, but since examples are more fun than abstract skepticism, I should start by providing an illustration. The underlying topic model here was produced by LDA on the top 10k words in 872 volume-length documents. Then I produced a correlation matrix of topics against topics. Finally I created a network in Gephi by connecting topics that correlated strongly with each other (see the notes at the end for the exact algorithm). Topics were labeled with their single most salient word, except in three cases where I changed the label manually. The size of each node is roughly log-proportional to the number of tokens in the topic; nodes are colored to reflect the genre most prominent in each topic. (Since every genre is actually represented in every topic, this is only a rough and relative characterization.) Click through for a larger version.
Since single-word labels are usually misleading, a graph like this would be more useful if you could mouseover a topic and get more information. E.g., the topic labeled “cases” (connecting the dark cluster at top to the rest of the graph) is actually “cases death dream case heard saw mother room time night impression.” (Added Nov 20: If you click through, I’ve now edited the underlying illustration as an image map so you get that information when you mouseover individual topics.)
A network graph does usefully dramatize several important things about the model. It reveals, for instance, that “literary” topics tend to be more strongly connected with each other than nonfiction topics (probably because topics dominated by nonfiction also tend to have a relatively specialized vocabulary).
On the other hand, I think a graph like this could easily be over-interpreted. Graphs are good models for structures that are really networks: i.e., structures with discrete nodes that may or may not be related to each other. But a topic model is not really a network. For one thing, as I was pointing out above, the boundaries between topics are at bottom arbitrary, so these nodes aren’t in reality very discrete. Also, in reality every topic is connected to every other. But as Scott Weingart has been pointing out, you usually have to cut edges to produce a network, and this means that you’re always losing some of the data. Every correlation below some threshold of significance will be lost.
That’s a nontrivial loss, because it’s not safe to assume that negative correlations between topics don’t matter. If two topics absolutely never occur together, that’s a meaningful relation! For instance, if language about the slave trade absolutely never occurred in books of poetry, that would tell us something about both discourses.
So I think we’ll also want to consider visualizing topic models through a strategy like PCA (Principal Component Analysis). Instead of simplifying the model by cutting selected edges, PCA basically “compresses” the whole model into two dimensions. That way you can include all of the data (even the evidence provided by negative correlations). When I perform PCA on the same 1850-99 model, I get this illustration. I’m afraid it’s difficult to read unless you click through and click again to magnify:
I think that’s a more accurate visualization of the relationship between topics, both because it rests on a sounder basis mathematically, and because I observe that in practice it does a good job of discriminating genres. But it’s not as fun as a network visually. Also, since specialized discourses are hard to differentiate in only two dimensions, specialized scientific topics (“temperature,” “anterior”) tend to clump in an unreadable electron cloud. But I’m hoping that Michael and I can find some technical fixes for that problem.
Technical notes: To turn a topic model into a correlation matrix, I simply use Pearson correlation to compare topic distributions over documents. I’ve tried other strategies: comparing distributions over the lexicon, for instance, or using cosine similarity instead of correlation.
The network illustration above was produced with Gephi. I selected edges with an ad-hoc algorithm: 1) take the strongest correlation for each topic 2) if the second-strongest correlation is stronger than .2, include that one too. 3) include additional edges if the correlation is stronger than .38. This algorithm is mathematically indefensible, but it produces pretty topic maps.
I find that it works best to perform PCA on the correlation matrix rather than the underlying word counts. Maybe in the future I’ll be able to explain why, but for now I’ll simply commend these lines of R code to readers who want to try it at home:
pca <- princomp(correlationmatrix)
x <- predict(pca)[,1]
y <- predict(pca)[,2]
The Artist in Despair Over the Magnitude of Antique Fragments, by Henry Fuseli.Just a quick note here to acknowledge a collaborative project that I hope will generate some useful resources for scholars interested in text mining. We don’t have many resources up on the website yet, but watch this space.
The principal investigators most actively involved in Uses of Scale are Ted Underwood (University of Illinois, Urbana-Champaign), Robin Valenza (University of Wisconsin, Madison), and Matt Wilkens (Notre Dame). All of us have been mining large collections of printed books, ranging from the early modern period to the twentieth century. We’ll be joining forces this year to reflect critically on problems of scale in literary research — including the questions that arise when we try to connect different scales of analysis. But we also hope to generate a few resources that are immediately and practically useful for scholars attempting to “scale up” their research projects (resources, for instance, for correcting OCR). There’s already a bare-bones list of OCR-correction rules on the website, as well a description of a more ambitious project now underway.
h/t @frankridgway – who now, performatively, does DHWhen I saw the meme to the right come across my facebook newsfeed — and then get widely shared! — I realized that the field of digital humanities is confronting a PR crisis. In literary studies, a lot of job postings are suddenly requesting interest or experience in DH. This requirement was not advertised when people began their dissertations, and candidates are understandably ticked off by the late-breaking news.
I know where they’re coming from, since I’ve spent much of the past twenty years having to pretend that my work was relevant to a wide variety of theoretical questions I wasn’t all that passionate about. Especially in job interviews. Did my work engage de Man’s well-known essays on the topic? “Bien sûr.” Had I considered postcolonial angles? “Of course. It would be unethical not to.” And so on. There’s nothing scandalous about this sort of pretense. Not every theme can be central to every project, but it’s still fair to ask people how their projects might engage a range of contemporary debates.
The problem we’re confronting now in DH is that people don’t feel free to claim a passing acquaintance with our field. If they’re asked about Marxist theory, they can bullshit by saying “Althusser, Williams, blah blah blah.” But if they’re asked about DH, they feel they have to say “no, I really don’t do DH.” Which sounds bracingly straightforward. Except, in my opinion, bracingly straightforward is bad for everyone’s health. It locks deserving candidates out of jobs they might end up excelling in, and conversely, locks DH itself out of the mainstream of departmental conversation.
I want to give grad students permission to intelligently bullshit their way through questions about DH just as they would any other question. For certain jobs — to be sure — that’s not going to fly. At Nebraska or Maryland or George Mason or McGill, they may want someone who can reverse the polarity on the Drupal generator, and a general acquaintance with DH discourse won’t be enough. But at many other institutions (including, cough, many elite ones) they’re just getting their toes wet, and may merely be looking for someone informed about the field and interested in learning more about it. In that case “intelligent, informed BS” is basically what’s desired.
What makes this tricky is that DH — unlike some other theoretical movements — does have a strong practical dimension. And that tends to harden boundaries. It makes grad students (and senior faculty) feel that no amount of information about DH will ever be useful to them. “If I don’t have time to build a web page from scratch, I’m never going to count as a digital humanist, so why should I go to reading groups or surf blogs?”
“Don’t be a square …”Naturally, I do want to encourage people to pick up some technical skills. They’re fun. But I think it’s also really important for the health of the field that DH should develop the same sort of penumbra of affiliation that every other scholarly movement has developed. It needs to be possible to intelligently shoot the breeze about DH even if you don’t “do” it.
There are a lot of ways to develop that kind of familiarity, from reading Matt Gold’s Debates in Digital Humanities, to surfing blogs, to blogging for yourself, to Lisa Spiro’s list of starting places in DH, to following people on Twitter, to thinking about digital pedagogy with NITLE, to affiliation with groups like HASTAC or NINES or 18th Connect. (Please add more suggestions in comments!) Those of us who are working on digital research projects should make it a priority to draw in local collaborators and/or research assistants. Even if grad students don’t have time to develop their own digital research project from the ground up, they can acquire some familiarity with the field. Finally, in my book, informed critique of DH also counts as a way of “doing DH.” When interviewers ask you whether you do DH, the answer can be “yes, and I’m specifically concerned about the field’s failure to address X.”
Bottom line: grad students shouldn’t feel that they’re being asked to assume a position as “digital” or “analog” humanists, any more than they’re being asked to declare themselves “for” or “against” close reading and feminism. DH is not an identity category; it’s a project that your work might engage, indirectly, in a variety of ways.
In recent weeks, journals published two papers purporting to draw broad cultural inferences from Google’s ngram corpus. The first of these papers, in PLoS One, argued that “language in American books has become increasingly focused on the self and uniqueness” since 1960. The second, in The Journal of Positive Psychology, argued that “moral ideals and virtues have largely waned from the public conversation” in twentieth-century America. Both articles received substantial attention from journalists and blogs; both have been discussed skeptically by linguists and digital humanists. (Mark Liberman’s takes on Language Log are particularly worth reading.)
I’m writing this post because systems of academic review and communication are failing us in cases like this, and we need to step up our game. Tools like Google’s ngram viewer have created new opportunities, but also new methodological pitfalls. Humanists are aware of those pitfalls, but I think we need to work a bit harder to get the word out to journalists, and to disciplines like psychology.
The basic methodological problem in both articles is that researchers have used present-day patterns of association to define a wordlist that they then take as an index of the fortunes of some concept (morality, individualism, etc) over historical time. (In the second study, for instance, words associated with morality were extracted from a thesaurus and crowdsourced using Mechanical Turk.)
The fallacy involved here has little to do with hot-button issues of quantification. A basic premise of historicism is that human experience gets divided up in different ways in different eras. If we crowdsource “leadership” using twenty-first-century reactions on Mechanical Turk, for instance, we’ll probably get words like “visionary” and “professional.” “Loud-voiced” probably won’t be on the list — because that’s just rude. But to Homer, there’s nothing especially noble about working for hire (“professionally”), whereas “the loud-voiced Achilles” is cut out to be a leader of men, since he can be heard over the din of spears beating on shields (Blackwell).The laws of perspective apply to history as well. We don’t have an objective overview; we have a position in time that produces its own kind of distortion and foreshortening. Photo 2004 by June Ruivivar.
The authors of both articles are dimly aware of this problem, but they imagine that it’s something they can dismiss if they’re just conscientious and careful to choose a good list of words. I don’t blame them; they’re not coming from historical disciplines. But one of the things you learn by working in a historical discipline is that our perspective is often limited by history in ways we are unable to anticipate. So if you want to understand what morality meant in 1900, you have to work to reconstruct that concept; it is not going to be intuitively accessible to you, and it cannot be crowdsourced.
The classic way to reconstruct concepts from the past involves immersing yourself in sources from the period. That’s probably still the best way, but where language is concerned, there are also quantitative techniques that can help. For instance, Ryan Heuser and Long Le-Khac have carried out research on word frequency in the nineteenth-century novel that might superficially look like the psychological articles I am critiquing. (It’s Pamphlet 4 in the Stanford Literary Lab series.) But their work is much more reliable and more interesting, because it begins by mining patterns of association from the period in question. They don’t start from an abstract concept like “individualism” and pick words that might be associated with it. Instead, they find groups of words that are associated with each other, in practice, in nineteenth-century novels, and then trace the history of those groups. In doing so, they find some intriguing patterns that scholars of the nineteenth-century novel are going to need to pay attention to.
It’s also relevant that Heuser and Le-Khac are working in a corpus that is limited to fiction. One of the problems with the Google ngram corpus is that really we have no idea what genres are represented in it, or how their relative proportions may vary over time. So it’s possible that an apparent decline in the frequency of words for moral values is actually a decline in the frequency of certain genres — say, conduct books, or hagiographic biographies. A decline of that sort would still be telling us something about literary culture; but it might be telling us something different than we initially assume from tracing the decline of a word like “fidelity.”
So please, if you know a psychologist, or journalist, or someone who blogs for The Atlantic: let them know that there is actually an emerging interdisciplinary field developing a methodology to grapple with this sort of evidence. Articles that purport to draw historical conclusions from language need to demonstrate that they have thought about the problems involved. That will require thinking about math, but it also, definitely, requires thinking about dilemmas of historical interpretation.
References
My illustration about “loud-voiced Achilles” is a very old example of the way concepts change over time, drawn via Friedrich Meinecke from Thomas Blackwell, An Enquiry into the Life and Writings of Homer, 1735. The word “professional,” by the way, also illustrates a kind of subtly moralized contemporary vocabulary that Kesebir & Kesebir may be ignoring in their account of the decline of moral virtue. One of the other dilemmas of historical perspective is that we’re in our own blind spot.
This post is an outline of discussion topics I’m proposing for a workshop at NASSR2012 (a conference of Romanticists). I’m putting it on the blog since some of the links might be useful for a broader audience.
In the morning I’ll give a few examples of concrete literary results produced by text mining. I’ll start the afternoon workshop by opening two questions for discussion: first, what are the obstacles confronting a literary scholar who might want to experiment with quantitative methods? Second, how do those methods actually work, and what are their limits?
I’ll also invite participants to play around with a collection of 818 works between 1780 and 1859, using an R program I’ve provided for the occasion. Links for these materials are at the end of this post.
I. HOW DIFFICULT IS IT TO GET STARTED?
There are two kinds of obstacles: getting the data you need, and getting the digital skills you need.
1. Is it really necessary to have a large collection of texts?
This is up for debate. But I tend to think the answer is “yes.”
Not because bigger is better, or because “distant reading” is the new hotness. It’s still true that a single passage, perceptively interpreted, may tell us more than a thousand volumes.
But if you want to interpret a single passage, you fortunately already have a wrinkled protein sponge that will do a better job than any computer. Quantitative analysis starts to make things easier only when we start working on a scale where it’s impossible for a human reader to hold everything in memory. Your mileage may vary, but I’d say, more than ten books?
And actually, you need a larger collection than that, because quantitative analysis tends to require context before it becomes meaningful. It doesn’t mean much to say that the word “motion” is common in Wordsworth, for instance, until we know whether “motion” is more common in his works than in other nineteenth-century poets. So yes, text-mining can provide clues that lead to real insights about a single author or text. But it’s likely that you’ll need a collection of several hundred volumes, for comparison, before those clues become legible.
Words that are consistently more common in works by William Wordsworth than in other poets from 1780 to 1850. I’ve used Wordle’s graphics, but the words have been selected by a Mann-Whitney test, which measures overrepresentation relative to a context — not by Wordle’s own (context-free) method. See the R script at the end of this post.
This isn’t to deny that there are interesting things that can be done digitally with a single text: digital editing, building timelines and maps, and so on. I just doubt that quantitative analysis adds much value at that scale. (And to give credit where it’s due: Mark Olsen was saying all this back in the 90s — see References.)
2. So, where do I get all those texts?
That’s what I was asking myself 18 months ago. A lot of excitement about digital humanities is premised on the notion that we already have large collections of digitized sources waiting to be used. But it’s not true, because page images are not the same thing as clean, machine-readable text.
If you’re interested in twentieth-century secondary sources, the JSTOR Data for Research API can probably get you what you need. Primary sources are a harder problem. In our own (Romantic) era, optical character recognition (OCR) is unreliable. The ratio of words transcribed accurately ranges from around 80% to around 98%, depending on print quality and typographical quirks like the notorious “long s.” For a lot of text-mining purposes, 95% might be fine, if the errors were randomly distributed. But they’re not random: errors cluster in certain words and periods.
What you see in a page image.
The problem can be addressed in several different ways. There are a few collections (like ECCO-TCP and the Brown Women Writers Project) that transcribe text manually. That’s an ideal solution, but coverage of that kind is stronger in the eighteenth than the nineteenth century.
What you may see as OCR.
So Jordan Sellers and I have supplemented those collections by automatically correcting 19c OCR that we got from the Internet Archive. Our strategy involved statistically cautious, period-specific spellchecking, combined with enough reasoning about context to realize that “mortal fin” is probably “mortal sin,” even though “fin” is a correctly spelled word. It’s not a perfect solution, but in our period it works well enough for text-mining purposes. We have corrected about 2,000 volumes this way, and are happy to share our texts and metadata, as well as the spellchecker itself (once I get it packaged well enough to distribute). I can give you either a zip file containing the 19c texts themselves, or a tab-separated file containing docIDs, words, and word counts for the whole collection. In either scheme, the docIDs are keyed to this metadata file.
Of course, selecting titles for a collection like this raises intractable questions about representativeness. We tried to maximize diversity while also selecting volumes that seemed to have reached a significant audience. But other scholars may have other priorities. I don’t think it would be useful to seek a single right answer about representativeness; instead, I’d like to see multiple scholars building different kinds of collections, making them all public, and building on each other’s work. Then we would be able to test a hypothesis against multiple collections, and see whether the obvious caveats about representativeness actually make a difference in any given instance.
3. Is it necessary to learn how to program?
I’m not going to try to answer that question, because it’s complex and better addressed through discussion.
I will tell a brief story. I went into this gig thinking that I wouldn’t have to do my own programming, since there were already public toolsets for text-mining (Voyant, MONK, MALLET, TAPoR, SEASR) and for visualization (Gephi). I figured I would just use those.
But I rapidly learned otherwise. Tools like MONK and Voyant taught me what was possible, but they weren’t well adapted for managing a very large collection of texts, and didn’t permit me to make my own methodological innovations. When you start trying to do either of those things, you rapidly need “nonstandard parts,” which means that someone in the team has to be able to program.
That doesn’t have to be a daunting prospect, because the programming involved is of a relatively forgiving sort. It’s not easy, but it’s also not professional software development. So if you want to do it yourself, that’s a plausible aspiration. Alternately, if you want to collaborate with someone, you don’t necessarily need to find “a computer scientist.” A graduate student or fellow humanist who can program will do just fine.
If you do want to learn to program, I would recommend starting with either Python or R. Of the two languages, Python is certainly easier. It’s intuitive, and well-documented, and great for working with text. If you expect to use existing tools (like MALLET), and just need some “glue” to connect them to each other, Python is probably the way to go. R is a more specialized and less intuitive language. But it happens to be specialized in some ways that are useful for text mining. In particular, it has built-in statistical functions, and a built-in plotting/graphing capacity. I’ve used it for the sample exercise that accompanies this post. But if you’re learning to program for the first time, Python might be a better all-around choice, and you could in principle extend it to do everything R does. [Later addition: You could do worse than start with The Programming Historian.]
II. WHAT CAN WE ACTUALLY DO WITH QUANTITATIVE METHODS?
What follows is just a list of elements. Interesting research projects tend to combine several of these elementary operations in ad-hoc ways suited to a particular question. The list of elements runs a little long, so let me cut to the chase: the overall theme I’m trying to convey is that you can build complex arguments on a very simple foundation. Yes, at bottom, text mining is often about counting words. But a) words matter and b) they hang together in interesting ways, like individual dabs of paint that together start to form a picture.
So, to return to the original question: what can we do?
1) Categorize documents. You can “categorize” in several different senses.
a) Information retrieval: retrieve documents that match a query. This is what you do every time you use a search engine.
b) (Supervised) classification: a program can learn to correctly distinguish texts by a given author, or learn (with a bit more difficulty) to distinguish poetry from prose, tragedies from history plays, or “gothic novels” from “sensation novels.” (See “Quantitative Formalism,” Pamphlet 1 from the Stanford Literary Lab.) The researcher has to provide examples of different categories, but doesn’t have to specify how to make the distinction: algorithms can learn to recognize a combination of features that is the “fingerprint” of a given category.
An example of clustering from “Quantitative Formalism,” Allison, Heuser, Jockers, Moretti, and Witmore, Stanford Literary Lab.
c) (Unsupervised) clustering: a program can subdivide a group of documents using general measures of similarity instead of predetermined categories. This may reveal patterns you don’t expect.
All three of these techniques can achieve amazing results armed with what seems like very crude information about the documents they’re categorizing. We know, intuitively, that merely counting words is not enough to distinguish a tragedy from a history play. But our intuitions are simply wrong — see the lit lab pamphlet I cited above. It turns out that there’s an enormous amount of information contained in relative word frequencies, even if you know nothing about sequence or syntax. As you consider other aspects of text mining, it’s useful to keep this intuitive misfire in mind. Relatively simple statistical techniques often characterize discourse a good deal better than our intuitions would predict.
2) Contrast the vocabulary of different corpora. In a way, this reverses the logic of classifying documents (1b). Instead of using features to sort documents into categories, you start with two categories of documents and contrast them to identify distinctive features.
For instance, you can discover which words (or phrases) are overrepresented in one author or genre (relative to, say, the rest of nineteenth-century literature). It can admittedly be a challenge to interpret the results: this is a kind of evidence we aren’t accustomed to yet. But lists of overrepresented words can be a fruitful source of critical leads to pursue in more traditional ways.
3) Trace the history of particular features (words or phrases) over time. This could be viewed as a special category of corpus comparison, where you’re comparing corpora segmented on the time axis.
The best-known example here would be Google’s ngram viewer. Digital humanists love to criticize the ngram viewer, partly for valid reasons (there’s no way to know what texts are being used). But it has probably been the single most influential application of text mining, so clearly people are finding this simple kind of diachronic visualization useful. A couple of other projects have built on the same dataset, slicing it in different ways. Mark Davies of BYU built an interface that lets you survey the history of collocations. Our team at Illinois built an interface that mines 18-19c correlations in the ngram dataset; it turns out that correlated words have a high likelihood of being related in other ways as well, and these can be intriguing leads: see what words correlate with “delicacy” in our period, for instance. Harvard has built Bookworm, which can be understood as a smaller but more flexible and better-documented version of the ngram viewer (built on the Open Library instead of Google Books).
Words whose frequencies correlate strongly over time are often related in other ways as well. Ngram viewer by Auvil, Capitanu, Heuser and Underwood, based on corrected Google dataset.
Of special interest to Romanticists: a project that isn’t built on the ngram dataset but that does use diachronic correlation-mining as a central methodology. In Stanford Lit Lab Pamphlet 4, Ryan Heuser and Long Le-Khac have traced some very interesting, strongly correlated changes in novelistic diction over the course of the 19th century.
Finally, anyone who wants to make a diachronic argument about diction should read Ben Schmidt’s simple, elegant experiment peeling apart two different components of change: generational succession and historical change within the diction of a single age-cohort.
4) Cluster features that tend to be associated in a given corpus of documents (aka topic modeling). In a way, this reverses the logic of clustering documents (1c). Instead of grouping documents that tend to share the same words, you group words that tend to appear in the same documents, or parts of documents. This produces something that looks like a semantic map of the period or corpus you’re studying. (It would be more accurate to call it a discursive map, because topics don’t actually have to be unified semantically. They are more analogous to “discourses.”)
There are a lot of ways to cluster features, ranging from older approaches (Latent Semantic Analysis), to the new, hip approach — “Bayesian topic modeling,” which has the advantage that it clusters individual occurrences of words (tokens) instead of word types. As a result, it can distinguish different senses of a word. (Scott Weingart has written a clear and comprehensive introduction to topic modeling for humanists.)
Topic modeling has become justifiably popular for several reasons. First and foremost, a “discursive map” can be a nice thing to have; it lends itself easily to interpretation. Also, frankly, this approach doesn’t require a whole lot of improvisation. You just pour text files into a tool like MALLET, and out come a list of topics, looking meaningful and authoritative. It’s important to remember that topic-modeling is in fact an imprecise process. Slightly different inputs (for instance, a different stopword list) can produce very different outputs.
5) Entity extraction. If you’re mainly interested in proper nouns (personal names or place names, or dates and prices) there are tools like OpenNLP that can extract these from text, using syntactic patterns as clues.
6) Visualization. Perhaps this isn’t technically a form of analysis, but in practice it’s important enough that it deserves to be treated as a separate analytical step. It’s impractical to list all possible forms of visualization here, but for instance, results can be visualized:
a) Geographically — to reflect, for instance, density of references to different parts of the world. (See
b) As a network graph — to reflect strength of affinity between different entities (characters, or topics, or what have you).
c) Through “Principal Component Analysis,” if you have multidimensional data that need to be flattened to two dimensions for ease of comprehension.
Putting things together.
There’s no limit to the number of ways you can combine these different operations. Matt Wilkens has extracted references to named entities from fiction, and then visualized their density geographically. Robert K. Nelson has performed topic modeling on the print run of a Civil-War-era newspaper, and then graphed the frequency of each topic over time. You could go a step further and look for correlations between topics (either over time, or in terms of their distribution over documents). Then you could visualize the relationships between topics as a network.
What’s the goal uniting all this experimentation? I suspect there are two different but equally valid goals. In some cases, we’re going to find patterns that actually function as evidence to support literary-historical arguments. (In a number of the examples cited above, I think that’s starting to happen.) In other cases, text mining may work mainly as an exploratory technique, revealing clues that need to be fleshed out and written up using more traditional critical methods. The boundary between those two applications will be hotly debated for years, so I won’t attempt to define it here.
III. SAMPLE DATA AND SCRIPT FOR EXPLORATION.
I don’t know whether we’ll really have time for this, but I ought to at least offer you a chance to do hands-on stuff. So here’s a medium-sized project.
Finally, I’ve provided an R script that will let you define different chunks of the collection and compare them against each other, to identify words that are significantly overrepresented in a given author, genre, or period. The script will try two different measures of “overrepresentation”: the first, “log-likelihood,” is based on the aggregate frequency of words in the corpus you selected, adding all the volumes in the corpus together. The second, “Mann-Whitney rho,” tries to locate words that are consistently more common in corpus X by paying attention to individual volumes. For more on how that works, see this blog post.
Of course, the R script won’t work until you download R and open it from within R. Please understand that this is a very rough, ad-hoc piece of work for this one occasion, not a polished piece of software that I expect people to use for the long term.
Postscript about the word “mining.”
I know it has an industrial sound; I know humanists like “analysis” more. But I’m sticking with the mining metaphor on the principle of truth in advertising. I think that word accurately conveys the scale of this enterprise, and the fact that it’s often more exploratory than probative. Besides, “mining” is vivid, and that has its own sort of humanistic value.
References (that aren’t already implicit in links)
Mark Olsen, “Signs, Symbols, and Discourses: A New Direction for Computer-Aided Literature Studies” Computers and the Humanities 27 (1993): 309-314.



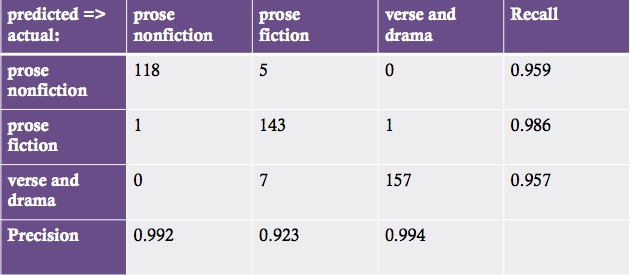
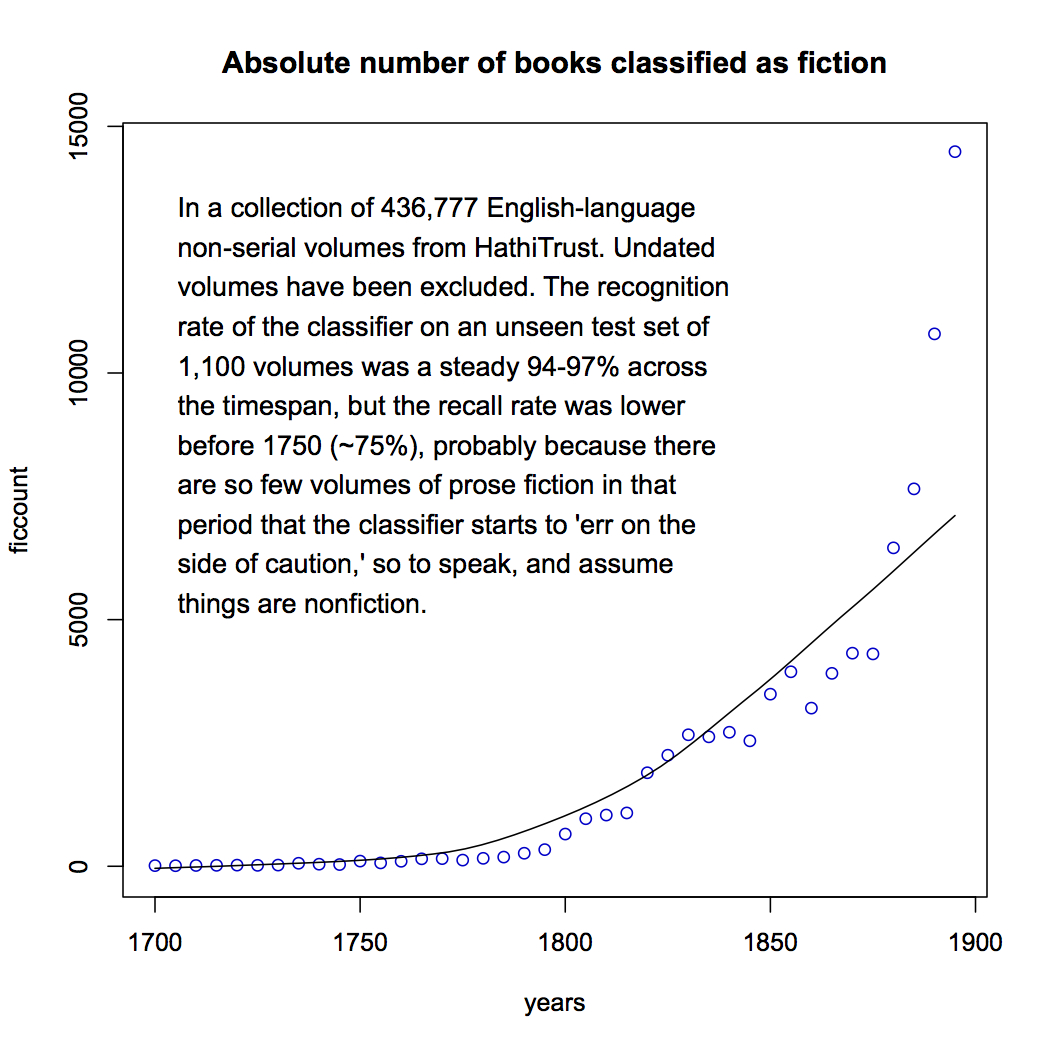
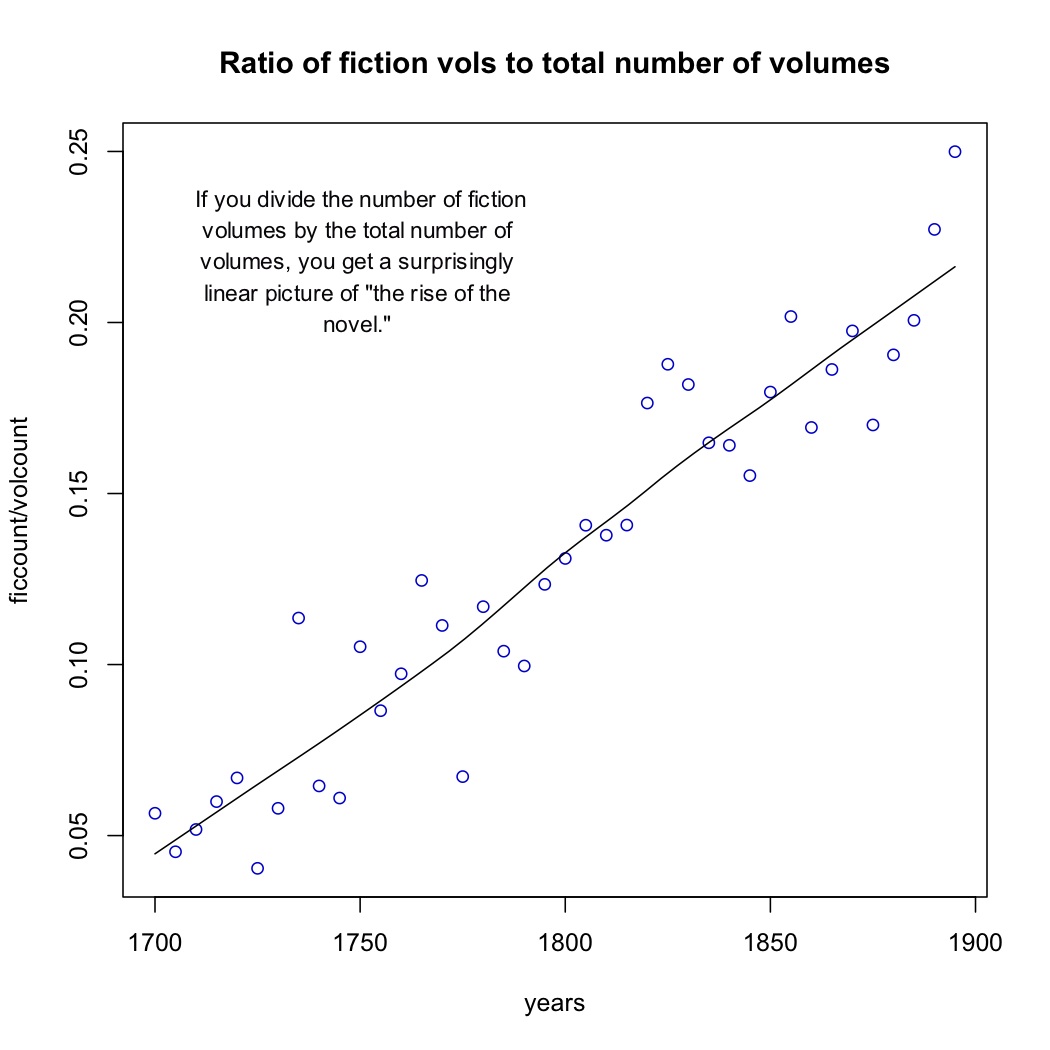
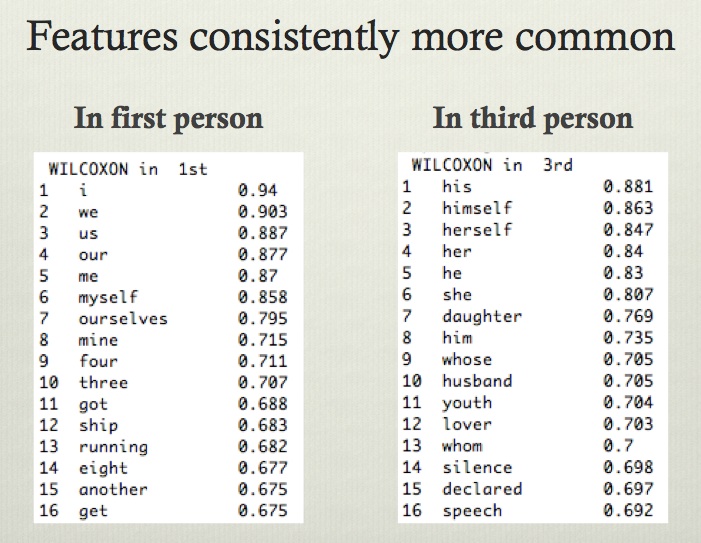



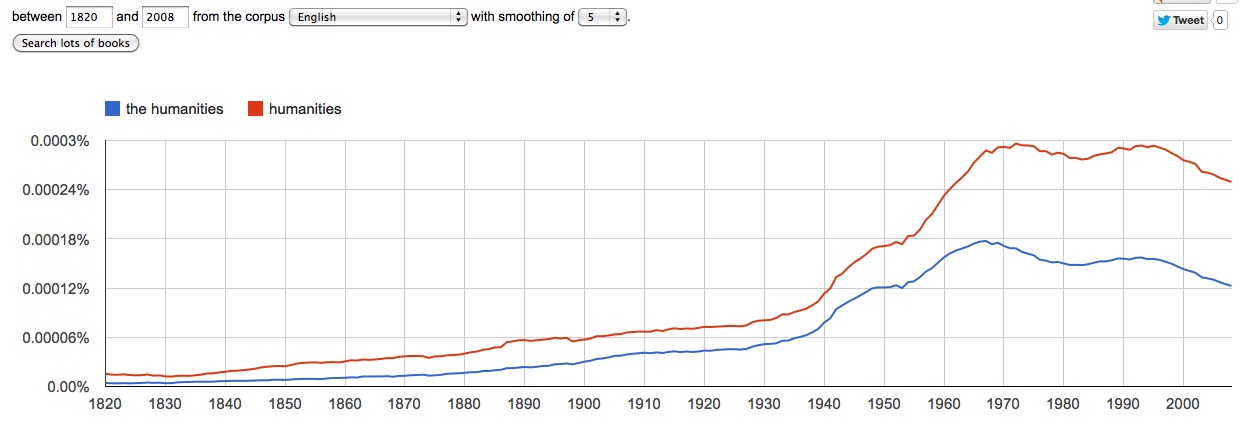

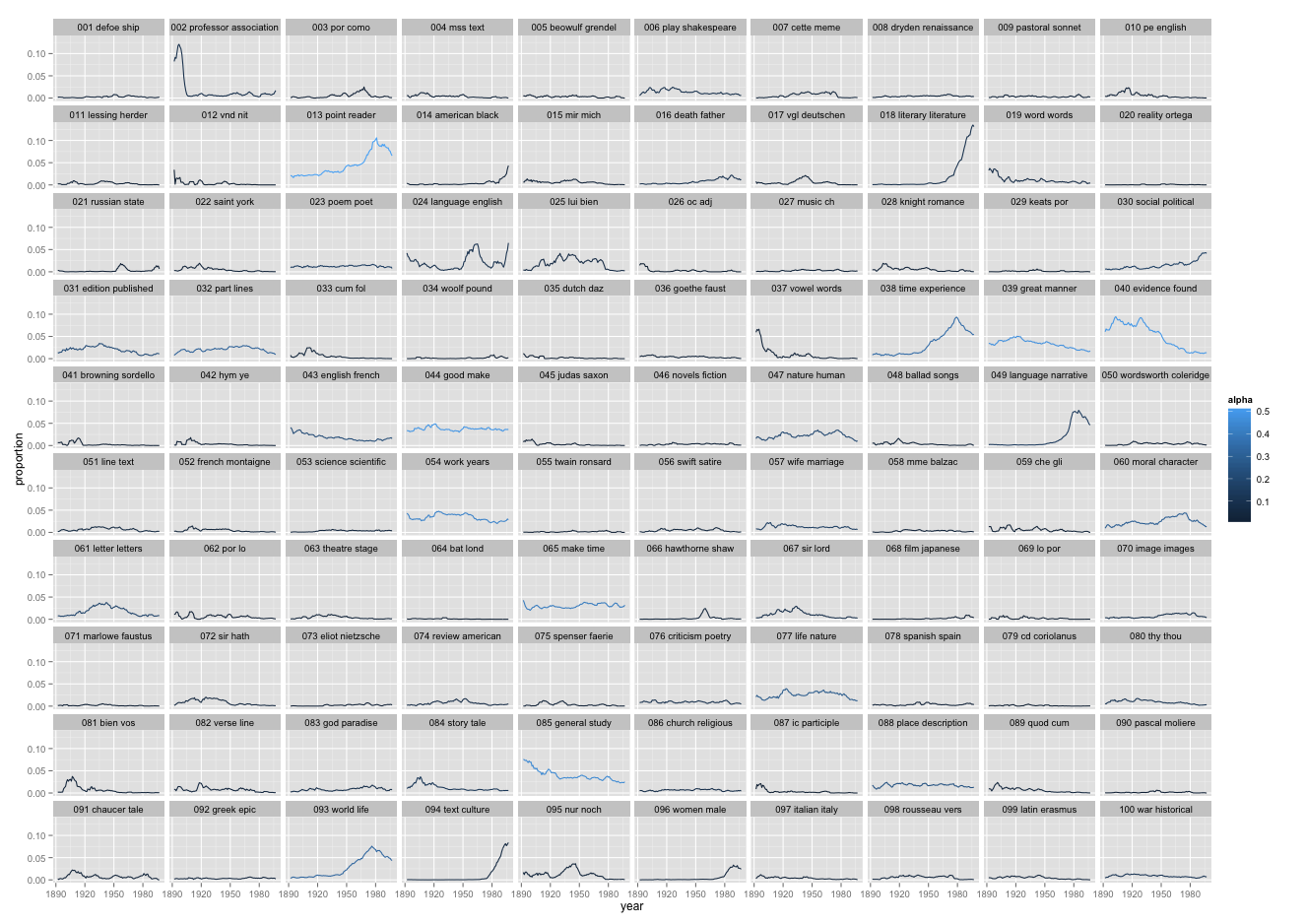
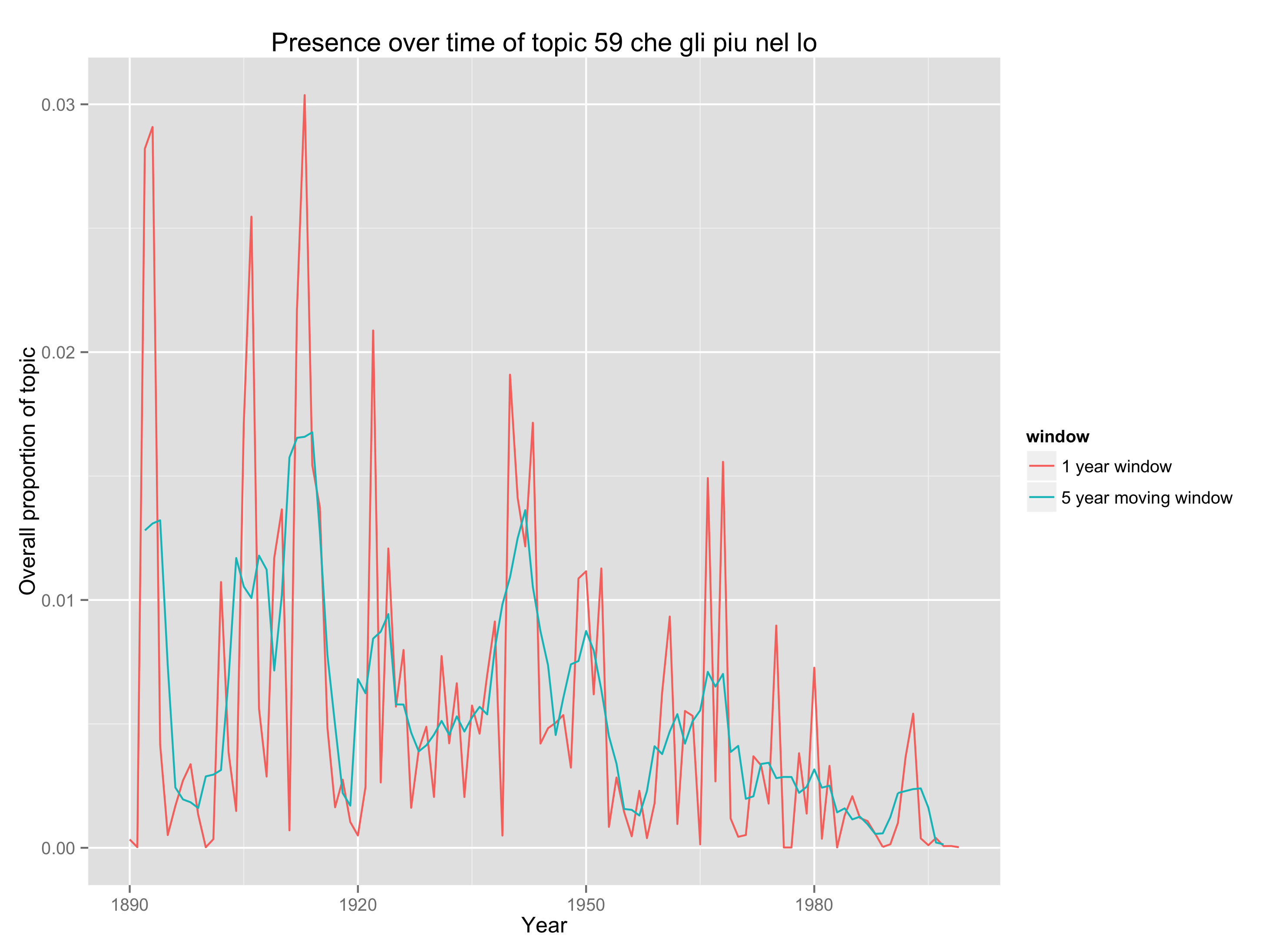
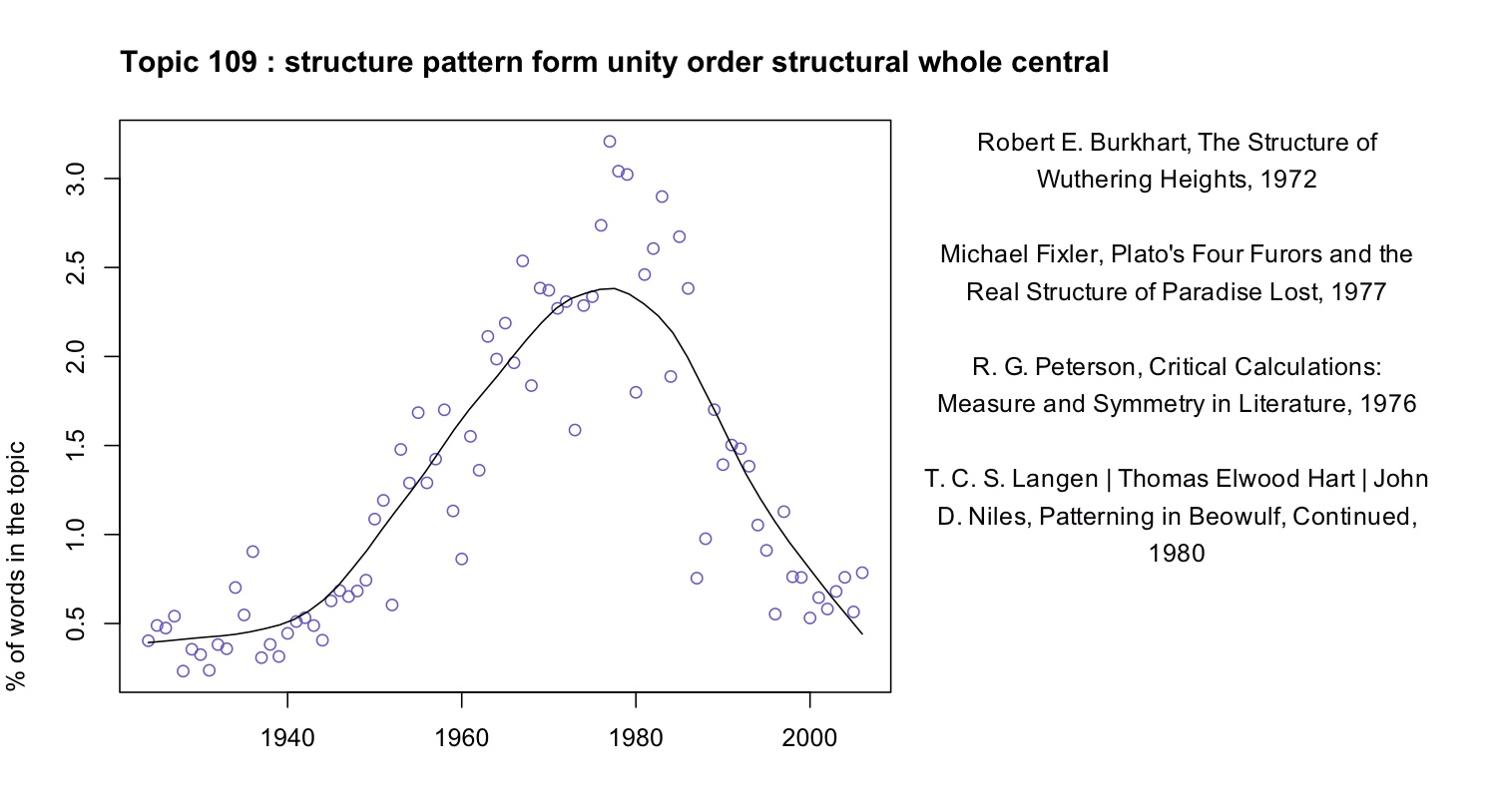
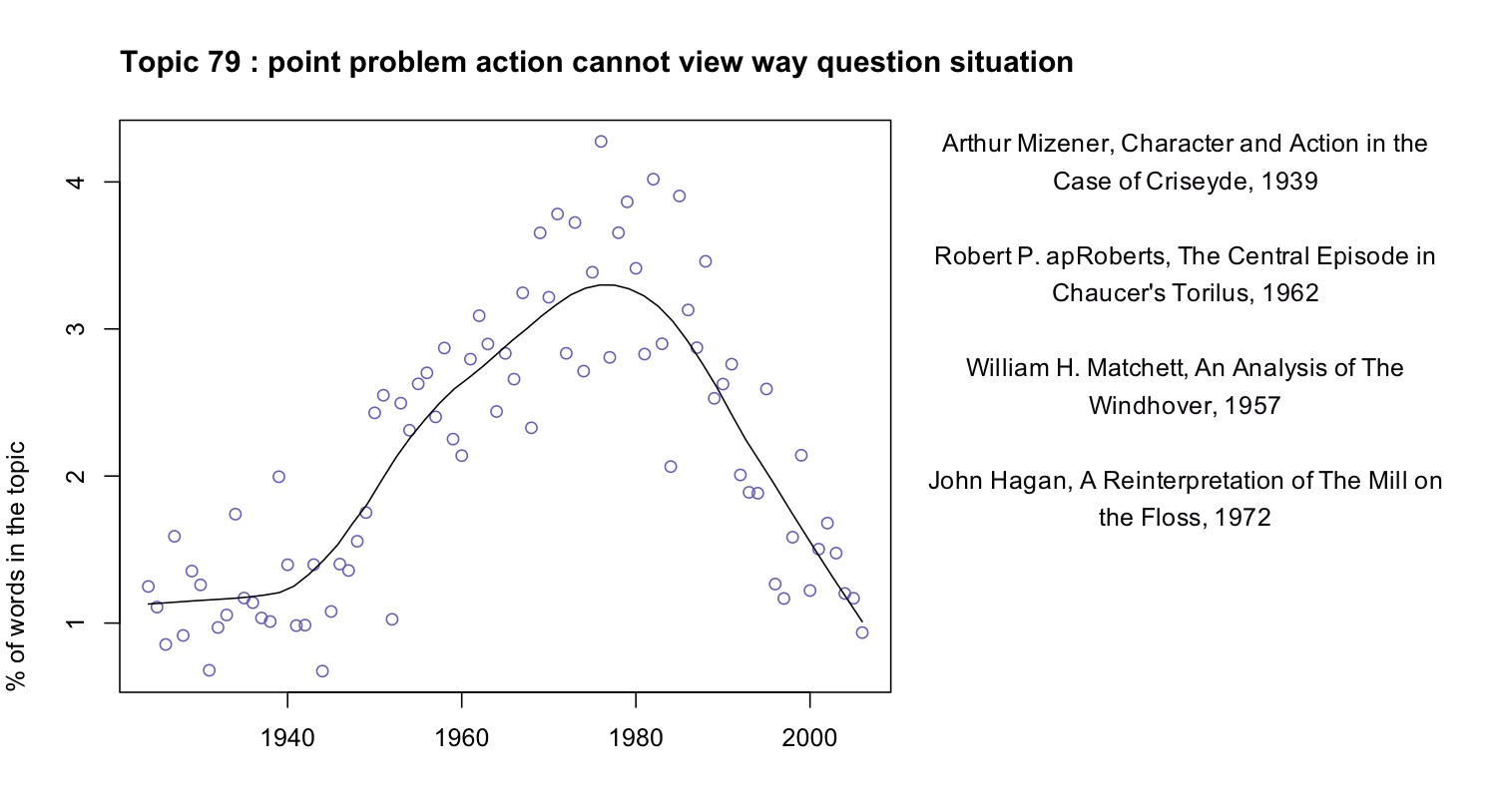



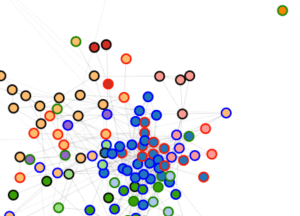
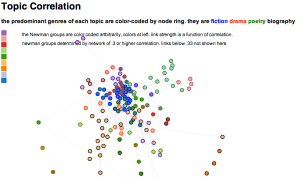


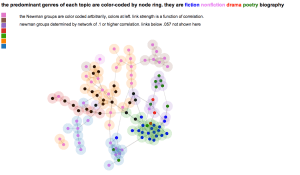














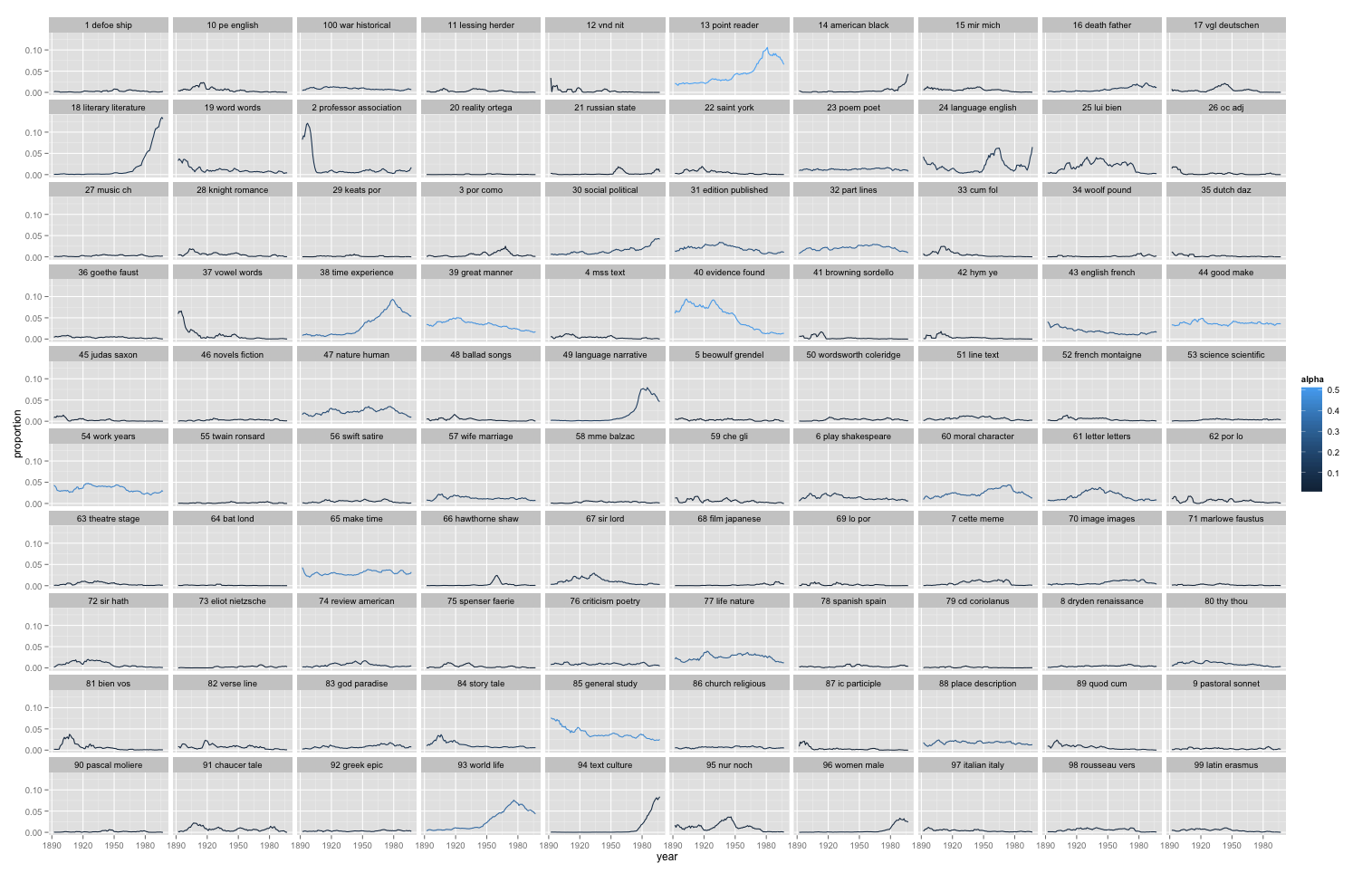{kind=link}